1. 개요
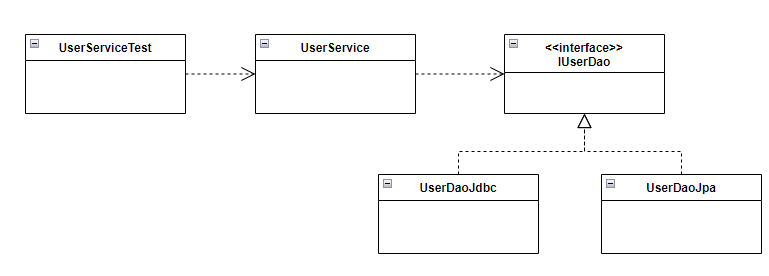
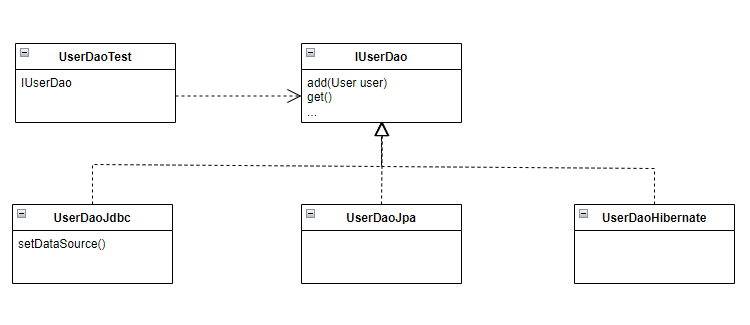
현재 트랜잭션 기술과, UserService, UserDao같은 어플리케이션 로직에 대해 추상화기법이 적용되어 있다. UserDao와 UserService는 각각 User에 대한 데이터 처리, 비지니스 처리에 대한 관심으로 구분되어 있다.
이 둘 모두 전략 패턴이 적용되어 있으며, 낮은 결합도를 갖는다. 결합도가 낮기 때문에 UserDao의 데이터 처리 로직이 바뀌어도 UserService의 코드에는 영향을 주지 않는다. 반대도 마찬가지다.
UserDao는 DB Connection을 생성하는 방법에 대해서도 독립적이다. DataSource 인터페이스와 DI를 통해 추상화된 방식으로 로우레벨의 DB 연결 기술을 사용하기 때문이다. DB 풀링 라이브러리를 사용하든, JDBC의 DriverManager를 사용하든, WAS가 JNDI를 통해 데이터 소스 서비스를 이용하든 상관없이 UserDao 코드에는 영향을 주지 않는다. 즉, UserDao와 DB 연결 기술도 결합도가 낮고, 수직적으로 분리되어 있다는 뜻이다.
이렇게 결합도가 낮은 구조로 만들 수 있는 데에는 스프링의 DI가 중요한 역할을 하고 있다. DI의 가치는 관심, 책임, 성격이 다른 코드를 깔끔하게 분리하는 데 있다. 이제 이러한 내용을 단일 책임원칙이라는 개념과 함께 이해해보자.
2. 단일 책임 원칙
2.1. 단일 책임 원칙이란?
DI의 가치인 '분리'는 객체지향 설계의 원칙 중 하나인 '단일 책임 원칙'으로 설명할 수 있다.
단일 책임 원칙(SRP : Single Responsibility Principle)
객체는 단 하나의 책임만 가져야 한다.
UserService에 JDBC Connection 메서드를 직접 사용했을 때에는 사용자의 레벨 관리와 트랜잭션 관리에 대한 두가지 책임을 갖고 있었다. 단일 책임 원칙을 지키지 못하는 것이다. 이로써 사용자의 레벨 관리 정책이 바뀌거나, 트랜잭션 기술이 JDBC 에서 JTA로 변경될 경우 UserService 클래스의 코드도 반드시 수정되어야 했었다.
추후 트랜잭션 기술에 대한 추상화 기법의 도입하여 트랜잭션 관리 책임을 트랜잭션 매니저에게 위임했다. 이로써 UserService는 단일 책임 원칙을 지키게 됐고, 트랜잭션 기술이 바뀌어도 UserService의 코드는 바뀔 필요가 없게 되었다.
2.2. 단일 책임 원칙의 장점
어떤 변경이 필요할 때 수정 대상이 명확해진다. 트랜잭션 기술이 바뀌면 기술 추상화 계층의 설정만 바꿔주면 되고, 데이터를 가져오는 테이블이 바뀌었다면 데이터 액세스 로직을 담고있는 UserDao만 변경하면 된다. 마찬가지로 레벨 관리 정책이 바뀌면 UserService만 변경하면 된다.
이러한 구조로 만들기 위해 빠지지 않았던게 바로 스프링 DI였다. 인터페이스의 도입과 적절한 DI는 단일 책임 원칙 뿐 아니라 개방 폐쇄 원칙도 잘 지키게 되니 결합도가 낮아 변경에 유연하며, 단일 책임에 집중하는 응집도 높은 코드를 개발할 수 있다.
3. 메일 서비스 추상화
위 내용을 생각하며 메일 발송에 대한 추상화를 적용해보자. 메일은 자바에서 제공하는 메일 발송 표준 기술인 JavaMail을 사용한다. 일반적으로 사용되는 예제 코드를 사용했으며, 필자의 경우 NAVER에서 제공하는 SMTP를 사용하였기에 사용에 필요한 여러 프로퍼티와 id, password 정보를 담고있는 Authenticator 객체 활용해주었다.
3.1. DefaultUserLevelUpgradePolicy.java
public class DefaultUserLevelUpgradePolicy implements UserLevelUpgradePolicy{
...
public String upgradeLevel(User user){
user.upgradeLevel();
userDao.update(user);
sendUpgradeMail(user); // 메일 발송 추상화메서드
return user.getId();
}
private void sendUpgradeMail(User user) {
Properties props = new Properties();
props.put("mail.host", "smtp.naver.com");
props.put("mail.port", "465");
props.put("mail.smtp.auth" , "true");
props.put("mail.smtp.ssl.enable", "true");
props.put("mail.smtp.ssl.trust", "smtp.naver.com");
props.put("mail.debug", "true");
Session s = Session.getInstance(props, new Authenticator() {
protected PasswordAuthentication getPasswordAuthentication() {
return new PasswordAuthentication("ID","PASSWORD");
}
});
MimeMessage message = new MimeMessage(s);
try{
message.setFrom(new InternetAddress("test@naver.com"));
message.addRecipient(Message.RecipientType.TO, new InternetAddress(user.getEmail()));
message.setSubject("Upgrade 안내");
message.setText("사용자님의 등급이 " + user.getLevel().name() +" 로 업그레이드 되었습니다.");
Transport.send(message);
} catch (AddressException e) {
e.printStackTrace();
throw new RuntimeException(e);
} catch (MessagingException e) {
e.printStackTrace();
throw new RuntimeException(e);
} catch (Exception e) {
e.printStackTrace();
throw new RuntimeException(e);
}
}
}
3.2. 테스트 결과
기존에 작성했던 테스트 코드를 실행하니 레벨 업그레이드 관련된 테스트 시 지정한 메일 주소로 메일이 발송됨을 확인할 수 있었다. (필자의 메일로 보냈다.)

3.3. 메일이 발송되는 테스트
이제 테스트 코드를 실행할 때마다 메일이 발송되게 되었다. 그런데 이처럼 메일이 발송되는 테스트는 바람직한 테스트라고 할 수 없다. 그 이유는 다음과 같다.
첫째, 메일 발송이란 부하가 큰 작업이다. 필자의 경우 네이버에서 제공하는 메일 서버를 사용했지만, 만약 유료 메일서버나, 본인이 속한 회사에서 실제 운영중인 메일 서버를 사용한다면 해당 서버에 상당한 부담을 줄 수 있다.
둘째, 실수로 인해 메일을 발송할 수 있다. 메일 테스트를 위해 개발자 자신의 이메일이나, 더미 이메일을 설정할수도 있지만, 개발, 운영 환경 설정 실수로 인해 테스트 메일을 실 사용자에게 발송할 수도 있다.
셋째, 테스트 속도가 느려진다. 레벨 업그레이드에 대한 테스트 케이스가 많다면, 실제 메일 발송도 많이 일어나게 된다. 메일 발송이 많다면, 테스트도 느려질 수 있다.
메일 서버는 충분히 테스트된 시스템이므로 초기에 몇번정도만 실제 주소로 메일을 보내고 받는걸 확인하는 걸로 충분하다. 결국 바람직한 메일 발송 테스트란 메일 전송 요청은 받되 메일 발송은 되지 않도록 하는것이다. 운영 시에는 JavaMail을 직접 이용해서 동작하도록 하고, 테스트 중에는 JavaMail을 사용할 때와 동일한 인터페이스를 갖는 코드가 동작하도록 구현해보자.
4. 메일 발송 테스트를 위한 서비스 추상화
실제 메일 전송을 수행하는 JavaMail 대신 JavaMail과 같은 인터페이스를 갖는 오브젝트를 만들어 사용하려했으나 그럴 수 없었다. 이유는 JavaMail의 핵심 API에는 DataSource처럼 인터페이스로 만들어진게 없기때문에 구현부를 바꿀 수 없다. 메일 발송 시 사용하는 Session, MailMessage, Transport 모두 인터페이스가 아닌 클래스이다. 실제로 JavaMail은 확장이나 지원이 불가능하도록 만들어진 API 중 하나라고 한다.
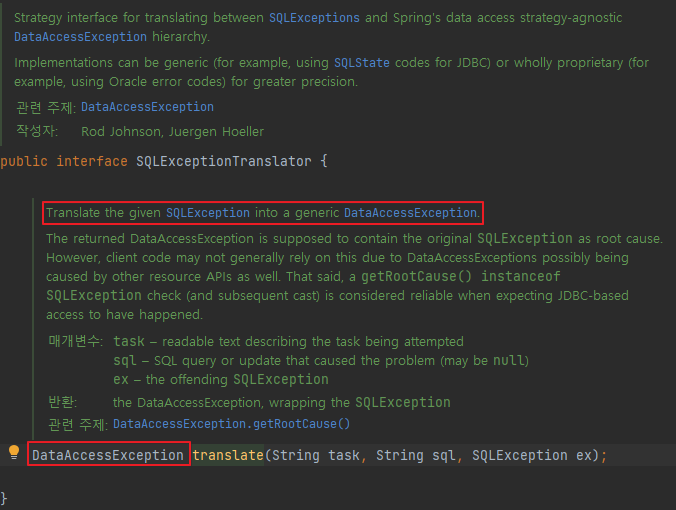
스프링에서는 이러한 JavaMail에 대한 추상화 기능을 제공하고 있다. JavaMail의 서비스 추상화 인터페이스는 다음과 같다.
public interface MailSender{
void send(SimpleMailMessage simpleMessage) throws MailException;
void send(SimpleMailMessage[] mailMessages) throws MailException;
}
이 인터페이스는 SimpleMailMessage라는 인터페이스를 구현한 클래스에 담긴 메일 메시지를 전송하는 메서드로 구성되어 있다. 이를 사용해 메일 발송 코드를 수정해보자.
4.1. 코드 리팩토링
4.1.1. DefaultUserLevelUpgradePolicy.java
public class DefaultUserLevelUpgradePolicy implements UserLevelUpgradePolicy{
private IUserDao userDao;
private MailSender mailSender;
private static final int MIN_LOGIN_COUNT_FOR_SILVER = 50;
private static final int MIN_RECOMMEND_FOR_GOLD = 30;
public void setUserDao(IUserDao userDao){
this.userDao = userDao;
}
public void setMailSender(MailSender mailSender){
this.mailSender = mailSender;
}
...
private void sendUpgradeMail(User user) {
SimpleMailMessage mailMessage = new SimpleMailMessage();
mailMessage.setTo(user.getEmail());
mailMessage.setFrom("test@naver.com");
mailMessage.setSubject("Upgrade 안내");
mailMessage.setText("사용자님의 등급이 " + user.getLevel().name() +" 로 업그레이드 되었습니다.");
mailSender.send(mailMessage);
}
}비지니스 로직을 서비스 추상화 인터페이스인 MailSender에 맞게 수정한다. SMTP 및 계정 관련 속성은 DI 시 설정하고, SimpleMailMessage 클래스에는 발송할 메일과 관련된 내용을 설정한다.
4.1.2. applicationContext.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id = "dataSource" class ="org.springframework.jdbc.datasource.SimpleDriverDataSource">
<property name="driverClass" value="com.mysql.jdbc.Driver"></property>
<property name="url" value = "jdbc:mysql://localhost/spring"></property>
<property name="username" value = "ID"></property>
<property name="password" value = "PW"></property>
</bean>
<bean id = "userDao" class = "org.example.user.dao.UserDaoJdbc">
<property name = "dataSource" ref = "dataSource"></property>
</bean>
<bean id = "userService" class = "org.example.user.service.UserService">
<property name="userDao" ref = "userDao"></property>
<property name="userLevelUpgradePolicy" ref = "userLevelUpgradePolicy"></property>
<property name="transactionManager" ref="transactionManager"></property>
</bean>
<bean id = "userLevelUpgradePolicy" class = "org.example.user.attribute.DefaultUserLevelUpgradePolicy">
<property name="userDao" ref = "userDao"/>
<property name="mailSender" ref ="mailSender"></property>
</bean>
<bean id = "transactionManager" class ="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource"></property>
</bean>
<bean id = "mailSender" class = "org.springframework.mail.javamail.JavaMailSenderImpl">
<property name="host" value = "smtp.naver.com"></property>
<property name="port" value = "465"></property>
<property name="username" value = "ID"></property>
<property name="password" value = "PASSWORD"></property>
<property name="javaMailProperties">
<props>
<prop key="mail.smtp.ssl.enable">"true"</prop>
<prop key="mail.smtp.ssl.trust">"smtp.naver.com"</prop>
<prop key="mail.smtp.auth">"true"</prop>
</props>
</property>
</bean>
</beans>JavaMailSenderImpl에 대한 Bean을 생성하고, userLevelUpgradePolicy의 mailSender에 DI한다.
4.2. 테스트
아래와 같이 JavaMail API를 사용했을 때와 동일하게 메일이 발송된다면 추상화 인터페이스로의 전환에 성공한것이다.

4.3. 테스트용 메일 발송 오브젝트 생성
메일 전송 기능을 추상화해서 인터페이스를 적용하고 DI를 통해 빈으로 분리했다. 이제 MailSender 인터페이스를 구현하는 테스트 클래스를 만들고, 테스트용 application-context에서 DI 해주면 된다.
4.3.1. DummyMailSender.java
public class DummyMailSender implements MailSender{
@Override
public void send(SimpleMailMessage simpleMessage) throws MailException {
}
@Override
public void send(SimpleMailMessage... simpleMessages) throws MailException {
}
}MailSender 인터페이스를 구현하였으나, 로직은 아무것도 작성하지 않았다. 테스트에서는 메일 발송할 필요가 없기때문이다.
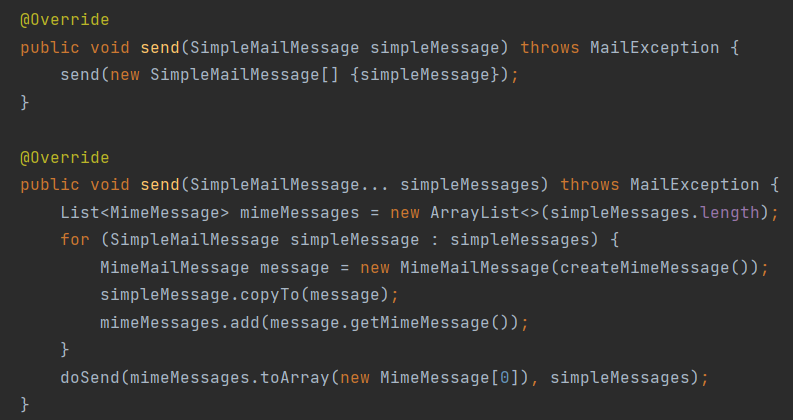
참고로 JavaMailSenderImpl 클래스의 경우 아래와 같이 실제 메일 발송 로직이 구현되어 있는 상태이다. 이제 운영시에는 이 클래스를 DI, 테스트 시에는 DummyMailSender 클래스를 DI하면 된다.
4.3.2. test-applicationContext.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
...
<bean id = "mailSender" class = "org.example.user.service.DummyMailSender"/>
</beans>test-applicationContext.xml의 mailSender의 구현체 클래스를 DummyMailSender로 설정한다.
4.3.3. DefaultUserLevelUpgradePolicyTest.java
@ExtendWith(SpringExtension.class)
@ContextConfiguration(locations = "/test-applicationContext.xml")
class DefaultUserLevelUpgradePolicyTest {
@Autowired
IUserDao userDao;
@Autowired
DefaultUserLevelUpgradePolicy userLevelUpgradePolicy;
List<User> users; // 테스트 픽스처
public static final int MIN_LOGIN_COUNT_FOR_SILVER = 50;
public static final int MIN_RECCOMEND_FOR_GOLD = 30;
@BeforeEach
void setUp(){
users = Arrays.asList(
new User("test1","테스터1","pw1", Level.BASIC, MIN_LOGIN_COUNT_FOR_SILVER-1, 0, "tlatmsrud@naver.com"),
new User("test2","테스터2","pw2", Level.BASIC, MIN_LOGIN_COUNT_FOR_SILVER, 0, "tlatmsrud@naver.com"),
new User("test3","테스터3","pw3", Level.SILVER, 60, MIN_RECCOMEND_FOR_GOLD-1, "tlatmsrud@naver.com"),
new User("test4","테스터4","pw4", Level.SILVER, 60, MIN_RECCOMEND_FOR_GOLD, "tlatmsrud@naver.com"),
new User("test5","테스터5","pw5", Level.GOLD, 100, 100, "tlatmsrud@naver.com")
);
}
@Test
void canUpgradeLevel() {
assertThat(userLevelUpgradePolicy.canUpgradeLevel(users.get(0))).isFalse();
assertThat(userLevelUpgradePolicy.canUpgradeLevel(users.get(1))).isTrue();
assertThat(userLevelUpgradePolicy.canUpgradeLevel(users.get(2))).isFalse();
assertThat(userLevelUpgradePolicy.canUpgradeLevel(users.get(3))).isTrue();
assertThat(userLevelUpgradePolicy.canUpgradeLevel(users.get(4))).isFalse();
}
@Test
void upgradeLevel() {
userLevelUpgradePolicy.upgradeLevel(users.get(1));
assertThat(users.get(1).getLevel()).isEqualTo(Level.SILVER);
userLevelUpgradePolicy.upgradeLevel(users.get(3));
assertThat(users.get(3).getLevel()).isEqualTo(Level.GOLD);
}
}
테스트 코드는 기존과 바뀐게 없다. 이로써 아래와 같이 MailSender 인터페이스를 핵심으로 하는 메일 전송 서비스 추상화 구조가 아래와 같이 구성되었다.
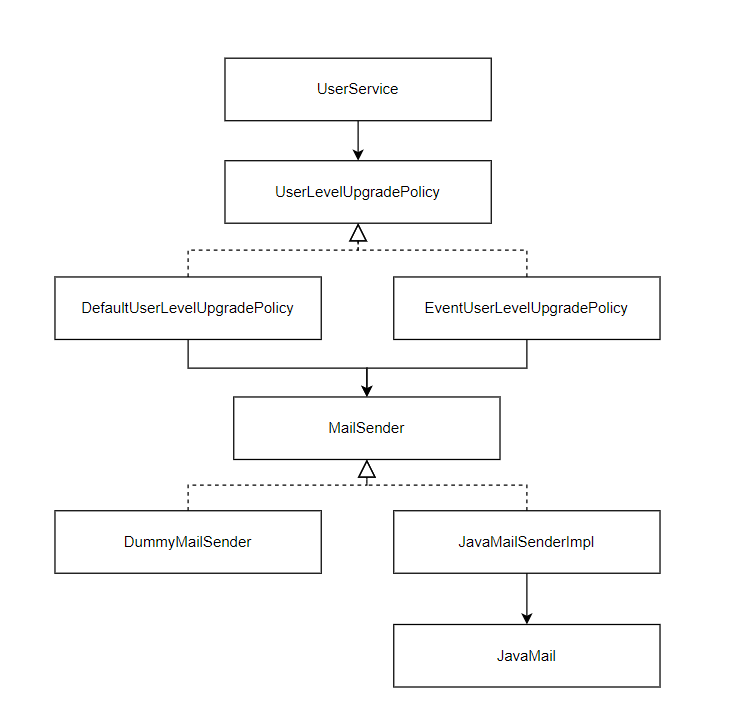
4.4. 테스트
테스트가 성공했을 때 메일 발송은 되지 않는 걸 확인할 수 있을 것이다.
5. 테스트 대역
5.1. 테스트 대역이란?
그런데 사실 이제까지 작성한 테스트 코드는 문제점이 하나 있다. 바로 테스트의 범위이다. UserServiceTest 클래스의 경우 UserService 클래스의 메서드를 테스트하는 코드이다. 하지만 그와 동시에 의존하는 UserLevelUpgradePolicy의 실제 로직도 수행된다. 사실 UserServiceTest 클래스의 관심사는 오로지 UserService 클래스의 로직이어야 한다. 의존하는 객체에 대해서는 그 클래스의 Test 코드에서 수행하는게 맞다.
테스트 대상 오브젝트에는 여러 의존 오브젝트들이 있을 수 있다. 이때에는 의존 오브젝트에 대한 '대역' 역할을 하는 오브젝트를 만들어 테스트가 이상없이 동작되도록 해야한다. 이러한 오브젝트들을 테스트 대역(test double) 이라고 한다.
5.2. 테스트 대역의 종류
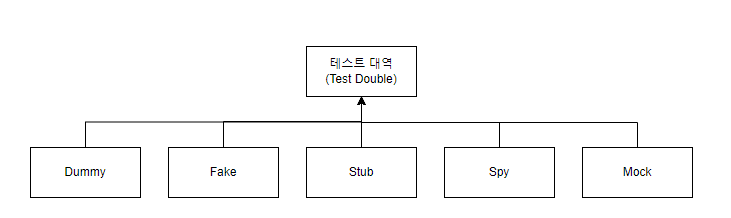
5.2.1. Dummy
아무런 동작을 하지 않는 테스트 대역이다. 인스턴스화된 객체는 필요하지만 기능은 굳이 필요없는 경우에 사용한다. 앞서 생성한 DummyMailSender가 Dummy에 속한다.
public class DummyMailSender implements MailSender{
@Override
public void send(SimpleMailMessage simpleMessage) throws MailException {
}
@Override
public void send(SimpleMailMessage... simpleMessages) throws MailException {
}
}
5.2.2. Fake
동작은 하지만, 실제 동작 방식과 다르게 구현하는 테스트 대역이다. DB 데이터 처리를 Fake로 만들고자 한다면 Repository 인터페이스에 대한 구현체 클래스를 만들고 내부에 ArrayList와 같은 멤퍼 필드를 생성하여 인메모리로 관리할 수 있다. 즉, DB가 아닌 다른 방식으로 구현하는 것이다.
아래는 데이터를 실제 DB가 아닌 인메모리에 저장한 list로 처리하도록 구현한 예이다.
public class FakeUserDao implements IUserDao{
private final List<User> list = new ArrayList<>();
@Override
public void add(User user) {
list.add(user);
}
@Override
public void deleteAll() {
list.clear();
}
@Override
public User get(String id) {
return list.stream()
.filter(user -> id.equals(user.getId()))
.findFirst()
.get();
}
@Override
public int getCount() {
return list.size();
}
...
}
5.2.3. Stub
Dummy 객체가 실제로 동작하는 것처럼 구현하는 테스트 대역이다. 어떤 메서드를 호출했을 때 반환 값이 없을 경우 Dummy를 사용해도 되지만, 반환 값이 있거나 네거티브 테스트로 인해 예외를 발생시켜야 할 경우에는 기존 Dummy 객체에 의도한 동작을 구현해줘야 한다.
아래는 ID가 100인 사용자 정보를 요청할 경우 RuntimeException을 발생시키고, 그 외에는 무조건 테스터 유저에 대한 픽스처를 생성 후 리턴하는 예이다.
public class StubUserDao implements IUserDao{
...
@Override
public User get(String id) {
if("100".equals(id)){
throw new RuntimeException("삭제된 ID입니다.");
}
return new User("1", "테스터","비밀번호", Level.BASIC,0 ,0,"test@naver.com");
}
...
}
5.2.4. Spy
기본적으론 실제 오브젝트처럼 동작한다. 대신, 원하는 메서드에 Stubbing 처리를 하여 응답을 미리 지정할 수 있다. 즉, Subbing이라는 스파이를 지정할 수 있는 테스트 대역이다. mockito 라이브러리에서 제공하는 SpyBean 어노테이션을 사용하면 쉽게 구현할 수 있다.
아래는 upgradeLevel() 메서드 호출 시 users.get(3)에 대해서만 RuntimeException을 발생시키고, 나머지는 실제 로직을 수행시키도록 하는 예이다. given 메서드를 사용하여 upgradeLevel에 대한 Stub를 지정하고 있다.
@SpyBean
DefaultUserLevelUpgradePolicy spyUserLevelUpgradePolicy;
...
@Test
@DisplayName("레벨업 처리 도중 예외 발생 테스트")
void exceptionDuringLevelUp(){
...
// users.get(3) 오브젝트로 upgradeLevel 메서드를 호출하면 RuntimeException을 발생시키도록 Stubbing
given(spyUserLevelUpgradePolicy.upgradeLevel(users.get(3))).willThrow(new RuntimeException());
/* upgradeLevels 메서드 내부에서 spyUserLevelUpgradePolicy.upgradeLevel()를 호출하고 있음.
* users.get(0), users.get(1), users.get(2)에 대한 매개변수로 호출 시 실제 로직이 실행되나,
* users.get(3) 으로 호출 시 RuntimeException이 발생함.
*/
userService.upgradeLevels();
...
}
5.2.5. Mock
가짜 객체를 만든 후 Stubbing을 통해 미리 명세를 정의해 놓은 대역을 말한다. Stub와 다른 점은 메서드의 리턴 값으로는 판단할 수 없는 행위를 검증할 수 있다는 점이다. 예제에서는 리턴 값이 없어 메일 발송 내역 확인이 어려운 DummyMailSender 클래스 대신 발송 내역을 확인할 수 있는, 즉 어떤 행위를 했는지를 명확히 검증하기 위해 MockMailSender 클래스를 생성하였다. 테스트 코드에서는 requests를 조회한 후 누구에게 발송했는지를 확인할 수 있다.
public class MockMailSender implements MailSender {
private final List<String> requests = new ArrayList<>();
@Override
public void send(SimpleMailMessage simpleMessage) throws MailException {
requests.add(simpleMessage.getTo()[0]);
}
@Override
public void send(SimpleMailMessage... simpleMessages) throws MailException {
}
public List<String> getRequests(){
return requests;
}
}
추가로 mockito 라이브러리에서 제공하는 기능 중 Mock 객체에 대해 특정 메서드를 어떤 파라미터로 호출 했는지를 검증할 수 있는 기능을 활용할 수 있다. 아래의 경우 userService.upgradeLevels() 내부에서 호출되는 mockUserLevelUpgrdePolicy라는 Mock 객체에 대해 users.get(3)을 파라미터로 하여 upgradeLevel 메서드가 호출됐는지를 확인한다. 이처럼 Mock은 상태 뿐 아닌 행위까지 검증할 수 있다.
@Test
void exceptionDuringLevelUp(){
...
userService.upgradeLevels();
verify(mockUserLevelUpgradePolicy).upgradeLevel(users.get(3));
}
'공부 > 토비의 스프링 스터디' 카테고리의 다른 글
| [토비의 스프링 스터디] 스프링이란 무엇인가 (0) | 2023.08.29 |
|---|---|
| [토비의 스프링 스터디] AOP / 트랜잭션 분리 / Mockito (0) | 2023.06.29 |
| [토비의 스프링 스터디] 9주차 / 서비스 추상화(2) / 트랜잭션 (1) | 2023.06.13 |
| [토비의 스프링 스터디] 8주차 / 서비스 추상화 (0) | 2023.06.06 |
| [토비의 스프링 스터디] 7주차 / 예외 / 예외 처리 방법 및 전략 (0) | 2023.05.25 |