1. 개요
Redis를 활용하여 사전순으로 조회되는 자동완성 기능을 구현했으나 검색빈도에 따라 자동완성 리스트를 뿌려주는 것이 사용자 입장에서 유용할 것 같다는 생각이 들었다. 또한 사용자 검색한 새로운 키워드도 데이터 셋에 추가해야 트렌드에 맞는 자동완성 리스트를 제공할 수 있을 것 같아 이를 적용하는 작업을 진행하였다.
2. 분석
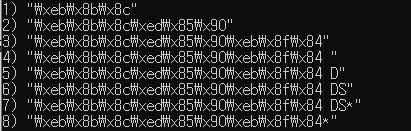
현재 redis에 들어가 있는 자동완성 데이터는 Score가 모두 0인 Sorted Set 형식이다. 또한 사용자가 검색한 단어를 prefix로 갖고 있는 완성된 단어를 뿌려주기 위해 필자가 정한 규칙에 맞게 데이터가 들어가 있는 상황이다. 예를들어 '대', '대한', '대한민', '대한민국' 이라는 키워드 입력시 자동완성 리스트에 '대한민국' 이라는 단어가 나오도록 하기 위해 score를 모두 0으로하여 '대', '대한', '대한민', '대한민국', '대한민국*' 값을 sorted Set 형식의 데이터 셋에 저장시킨 상태이다.
비지니스 로직은 다음과 아래와 같이 구현되어 있다.
1) 검색어와 일치하는 단어의 index 조회(zrank 명령어 사용)
2) index 번째부터 index + 100번째까지의 데이터 조회(zrange 명령어 사용)
3) '*' 문자를 포함하는 완전한 단어를 필터링
4) 검색어의 prefix와 일치하는 완전한 단어를 필터링 및 limit
위에 대한 자세한 내용은 이전 포스팅에 기재되어있다.
https://tlatmsrud.tistory.com/106
[Redis] Redis를 활용한 자동완성 구현 / 자동완성 데이터 셋 만들기
1. 개요 Redis를 활용하여 자동완성 기능을 구현해보았다. 2. Redis를 선택한 이유 2.1. 속도 Redis는 인 메모리에 데이터를 저장하고 조회하기 때문에 디스크에 저장하는 DB보다 훨씬 빠르다. 속도가
tlatmsrud.tistory.com
어쨌든 검색빈도 순으로 조회시키기 위해서는 반드시 검색횟수를 관리하는 데이터셋이 필요했다. 먼저 기존 데이터셋을 활용하는 쪽으로 시도하였으나 실패했다.
3. 기존 테이터 셋 활용
기존 데이터 셋의 score를 활용할 경우 사용자가 단어를 입력 후 '검색' API를 호출했을 때 검색한 단어가 데이터 셋에 추가되어야 하고, score가 1이 올라가야 한다. 이때 두가지 케이스로 나눌 수 있는데, 검색한 단어에 대해서만 score를 올리는 케이스, 검색한 단어와 연관된 데이터들의 score를 올리는 케이스이다.
3.1. 검색한 단어에 대해서만 Score 증가
전자의 경우 score가 올라가는 완성된 단어들은 데이터셋의 하단부에 위치하게 되고, 나머지 데이터들은 상단부에 위치하게 된다. 원래 나머지 데이터들은 자동완성 단어를 index 기반으로 빠르게 조회하기 위해서 사용했었으나, 자동완성 단어의 score가 올라가며 index 규칙이 깨지게 되었다.
아까 말한대로 자동완성들은 하단부, 나머지 데이터는 상단부에 위치하게 되니 결국 index부터 끝까지 모든 값을 조회해야하는 상황이 발생했다. 지금은 데이터 셋이 적어서 큰 문제가 되지 않을테지만, 시간 복잡도에 따라 데이터 양이 증가할수록 속도가 느려질 것이다. (zrange의 시간복잡도는 O(log(n)+m)이다. m은 반환된 결과의 수이다.) 아래는 그 예이다.
AS-IS의 경우 '대'에 대한 zrange 시 index 기준 +4에 대한민국*이 위치한다. 즉, 가까운 곳에 자동완성 단어들이 위치하고 있기 때문에 굳이 데이터셋의 끝까지 조회할 필요가 없다. 필자의 경우 가중치를 두어 index ~ index+1000 까지만 조회하도록 했다.
| index | score | value |
| n | 0 | 대 |
| n+1 | 0 | 대한 |
| n+2 | 0 | 대한민 |
| n+3 | 0 | 대한민국 |
| n+4 | 0 | 대한민국* |
TO-BE의 경우 '대'에 대한 zrange 시 index와 먼 곳에 자동완성 단어들이 위치한다. 데이터 셋의 끝까지 조회해야 할 필요성이 느껴진다.
| index | score | value |
| n | 0 | 대 |
| n+1 | 0 | 대한 |
| n+2 | 0 | 대한민 |
| n+3 | 0 | 대한민국 |
| ... | ... | .. |
| m | 1 | 대한민국* |
3.1. 검색한 단어와 연관된 데이터들의 Score 증가
후자의 경우는 자동완성 단어 누락을 야기할수 있다. '대만'이라는 데이터를 추가하여 예를 들어보겠다.
| index | score | value |
| n | 0 | 대 |
| n+1 | 0 | 대만 |
| n+2 | 0 | 대만* |
| n+3 | 0 | 대한 |
| n+4 | 0 | 대한민 |
| n+5 | 0 | 대한민국 |
| n+6 | 0 | 대한민국* |
score가 0일때는 위와 같이 사전순으로 정렬된다. 사용자가 '대한민국'이라는 검색 API를 통해 검색하는 순간 관련된 데이터인 '대', '대한', '대한민', '대한민국', '대한민국*'의 score가 1씩 올라갈것이다. 그리고 데이터는 아래와 같이 조회된다.
| index | score | value |
| n-2 | 0 | 대만 |
| n-1 | 0 | 대만* |
| n | 1 | 대 |
| n+1 | 1 | 대한 |
| n+2 | 1 | 대한민 |
| n+3 | 1 | 대한민국 |
| n+4 | 1 | 대한민국* |
이때 '대'에 대한 자동완성 단어들은 index 기준 앞, 뒤에 위치해있다. 기존에는 자동완성 단어들을 찾기위해 한쪽 방향으로 조회했다면, 이제는 양쪽 방향으로 조회하며 찾아야한다.
또한 새로운 단어들이 추가될 경우 score에 따라 데이터들이 뒤죽박죽 섞여버린다. 섞여버린 데이터들에서 자동완성 단어를 찾으려면 무조건 처음부터 끝까지 풀서치를 할수밖에 없는 상황이 되었다.
| index | score | value |
| n-? | 0 | 대만 |
| n-? | 0 | 대만* |
| n-? | 100 | 필라델피아* |
| ... | ... | |
| n | 500 | 대 |
| ... | ... | |
| n+? | 1000 | 대한민국* |
| ... | ... | |
| n+? | 20000 | 삼성전자 주가* |
결국 기존 데이터셋은 그대로 유지하고, 검색 횟수를 관리하는 새로운 데이터셋을 추가하기로 했다.
4. 새로운 데이터 셋 도입
검색 단어들을 관리하는 새로운 데이터 셋을 만들었다. value는 검색어, score는 검색횟수이다. 기존 데이터셋은 자동완성 데이터를 조회하기 위해 기존과 동일하게 사용하고, 새로운 데이터셋은 기존 데이터셋에서 조회한 자동완성 단어에 대해 score(검색횟수)를 조회하는 용도로 사용했다. 이후 비지니스 로직을 통해 score 기준으로 내림차순 정렬처리 하였다.
| 자동완성 데이터 셋 | 검색 횟수 데이터셋 | ||
| score | value | score | value |
| 0 | 대 | 0 | 대만 |
| 0 | 대만 | 0 | 대한민국 |
| 0 | 대만* | ||
| 0 | 대한 | ||
| 0 | 대한민 | ||
| 0 | 대한민국 | ||
| 0 | 대한민국* | ||
검색 횟수 데이터셋이 추가됨에 따라 기존 로직에서 아래 빨간 부분에 대한 로직을 추가하였다.
1) 검색어와 일치하는 단어의 index 조회(zrank 명령어 사용)
2) index 번째부터 index + 100번째까지의 데이터 조회(zrange 명령어 사용)
3) '*' 문자를 포함하는 완전한 단어를 필터링
4) 검색어의 prefix와 일치하는 완전한 단어를 필터링 및 limit
5) 필터링된 데이터의 score 조회 (zscore)
6) score를 기준으로 정렬
* 참고로 zscore를 사용한 이유는 시간복잡도가 O(1)이기 때문이다. 시간이 지날수록 데이터 양이 많아지는 데이터 특성 상 처리 속도를 일정하게 유지하는 것이 효율적이라고 판단하여 이 방식을 채택했다.
이제 실제로 구현해보자.
5. 구현
5.1. AutocompleteController.kt
@RestController
@RequestMapping("/api/autocomplete")
class AutocompleteController (
private val autocompleteService : AutocompleteService
){
@GetMapping("/{searchWord}")
@ResponseBody
fun getAutocompleteList(@PathVariable searchWord : String) : ResponseEntity<AutocompleteResponse> {
return ResponseEntity.ok(autocompleteService.getAutocomplete(searchWord))
}
}기존과 동일하다.
5.2. AutocompleteService.kt
@Service
class AutocompleteService (
private val redisTemplate : RedisTemplate<String, String>,
@Value("\${autocomplete.limit}") private val limit: Long,
@Value("\${autocomplete.suffix}") private val suffix : String,
@Value("\${autocomplete.key}") private val key : String,
@Value("\${autocomplete.score-key}") private val scoreKey : String
){
fun getAutocomplete(searchWord : String) : AutocompleteResponse {
val autocompleteList = getAutoCompleteListFromRedis(searchWord)
return sortAutocompleteListByScore(autocompleteList)
}
fun addAutocomplete(searchWord : String ){
val zSetOperations = redisTemplate.opsForZSet()
zSetOperations.incrementScore(scoreKey, searchWord, 1.0)
zSetOperations.score(key, searchWord)?:let {
for(i in 1..searchWord.length){
zSetOperations.add(key, searchWord.substring(0,i),0.0)
}
zSetOperations.add(key, searchWord+suffix,0.0)
}
}
fun getAutoCompleteListFromRedis(searchWord : String) : List<String> {
val zSetOperations = redisTemplate.opsForZSet()
var autocompleteList = emptyList<String>()
zSetOperations.rank(key, searchWord)?.let {
val rangeList = zSetOperations.range(key, it, it + 1000) as Set<String> // 가중치 1000
autocompleteList = rangeList.stream()
.filter { value -> value.endsWith(suffix) && value.startsWith(searchWord) }
.map { value -> StringUtils.removeEnd(value, suffix) }
.limit(limit)
.toList()
}
return autocompleteList
}
fun sortAutocompleteListByScore(autocompleteList : List<String>) : AutocompleteResponse{
val zSetOperations = redisTemplate.opsForZSet()
val list = arrayListOf<AutocompleteResponse.Data>()
autocompleteList.forEach{word ->
zSetOperations.score(scoreKey, word)?.let {
list.add(AutocompleteResponse.Data(word, it))
}
}
list.sortByDescending { it.score }
return AutocompleteResponse(list)
}
}
1) getAutoCompleteListFromRedis 메서드를 통해 Redis의 자동완성 데이터셋에서 자동완성 데이터를 가져온다. 가중치는 1000, limit는 10으로 설정하였다.
2) sortAutocompleteListByScore 메서드를 통해 검색횟수 데이터 셋에 값이 있는지 확인한다. 값이 있을 경우 score 가져와 list에 추가하고, sortByDescending 메서드를 사용해 score 기준으로 내림차순 정렬한다.
3) addAutocomplete는 검색 로직에서 사용하는 메서드로, 자동완성 데이터셋에 검색어가 없을 경우 규칙에 맞게 추가하고, 검색횟수 데이터 셋에 score를 추가 및 증가시킨다.
* 참고로 검색횟수 데이터 셋 score를 증가시킬 때 사용한 incrementScore는 데이터 셋에 값이 없을경우 자동으로 값을 추가해준다.
5.3. SearchService.kt
fun searchProductList(searchWord: String, pageable: Pageable): ProductListResponse? {
autocompleteService.addAutocomplete(searchWord)
return productRepository.selectProductListBySearchWord(searchWord,pageable)
}검색관련 비지니스 로직이다.(자동완성 로직이 아니다.) 여기서 autocompleteService를 DI받아 addAutocomplete를 호출하고 있다.
5.4. AutocompleteResponse.kt
data class AutocompleteResponse(
val list : List<Data>
){
data class Data(
val value: String,
val score: Double
)
}자동완성 응답 DTO 클래스이다.
6. 테스트
게임 기종 관련하여 자동완성 데이터셋과 검색횟수 데이터셋을 생성한 후 테스트를 진행하였다.
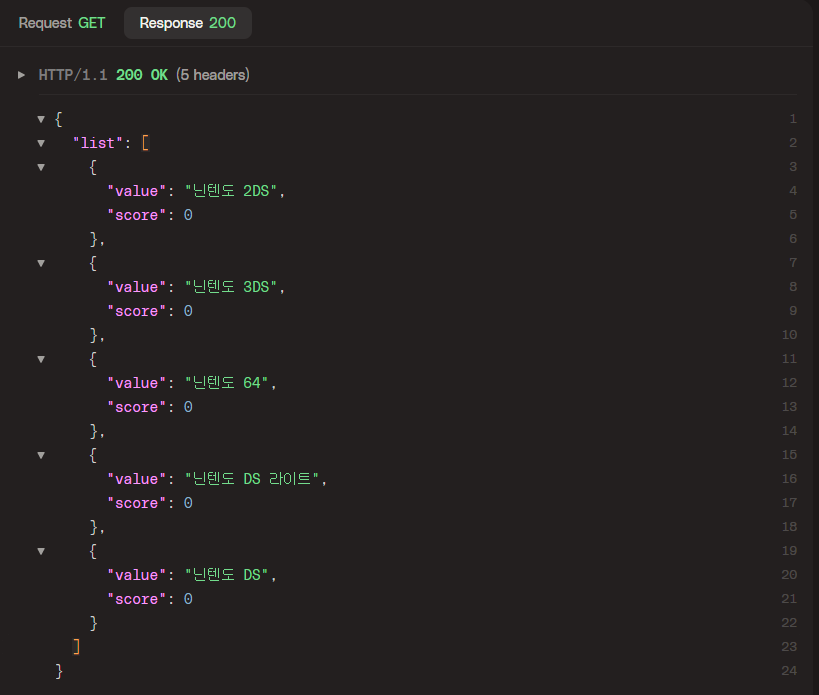
6.1. 자동완성 리스트 조회
'닌'이라는 단어를 입력했을 때 조회되는 자동완성 리스트들이다. value에는 자동완성 단어, score에는 검색횟수가 조회되고 있다.
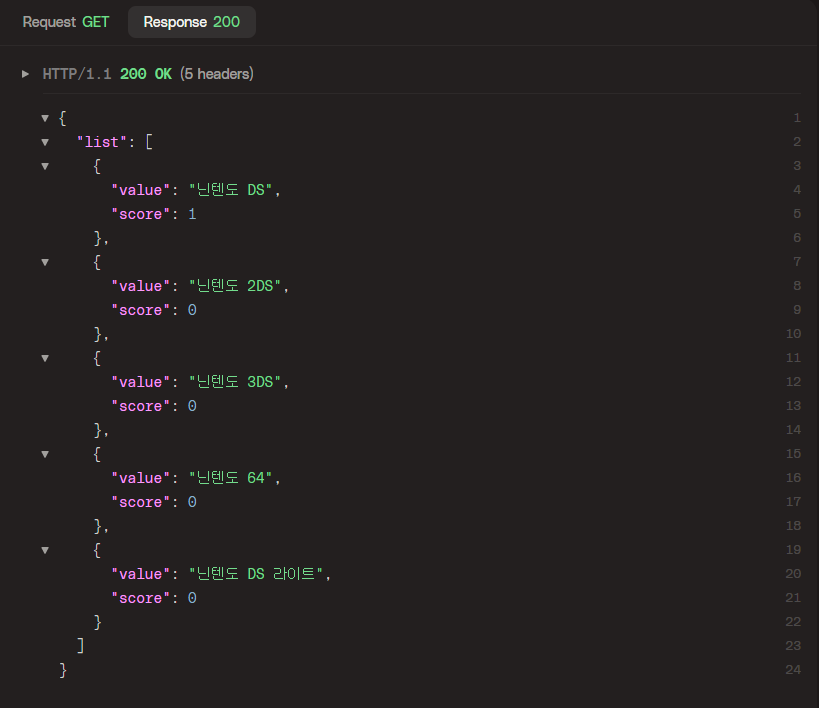
6.2. 검색 후 자동완성 리스트 조회
이제 제일 하단에 조회되는 '닌텐도 DS'라는 단어를 검색 API를 통해 검색한 후 '닌'에 대한 자동완성 리스트를 다시 조회해보자. 아래와 같이 닌텐도 DS라는 단어가 최상단에 조회됨을 확인할 수 있다.
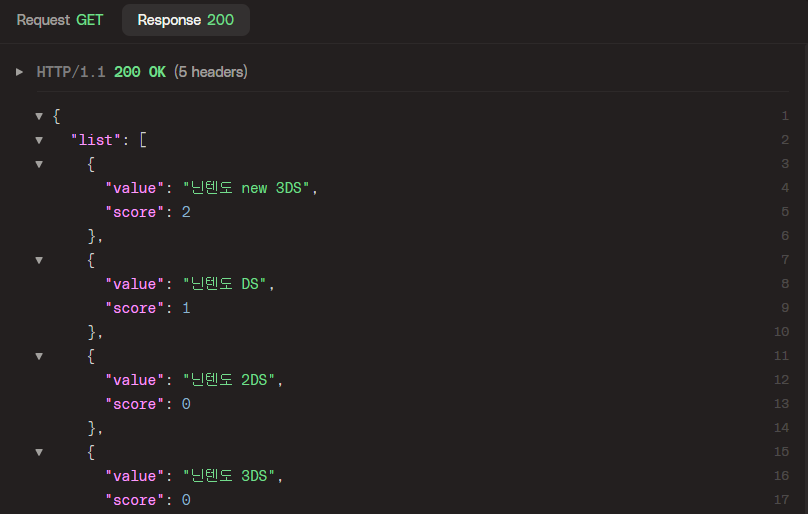
6.3. 새로운 단어 검색 후 조회
검색 API를 통해 '닌텐도 new 3DS'라는 새로운 단어를 두번 검색 후 다시 조회해보자. 아래와 같이 '닌텐도 new 3DS' 새로 추가됨과 동시에 최상단에 위치해있는 걸 확인할 수 있다.
7. 회고
기존 데이터셋을 활용하는게 메모리적와 속도면에서 훨씬 효율적일 것 같아 여러 시도를 해보았지만, 결국 새로운 데이터셋을 추가하는 쪽으로 구현하게 되었다.
새로운 데이터 셋 추가를 꺼려했던 이유는 속도 때문이었다. 처음엔 메모리도 신경쓰였으나 이 경우 기존 데이터셋보다 10분의 1도 안될 것이었기때문에 큰 걱정은 되지 않았다. 하지만 Redis를 한번 더 거쳐야 하고, 거기서 많은 자원을 사용하는 로직이 포함될 경우 처리 속도가 너무 느려지지 않을까하는 걱정이 앞섰다.
때문에 redis 문법에 대한 처리 속도와 redis 라이브러리에서 제공하는 여러 메서드들을 하나하나 찾아가며 어떤게 더 효율적일지를 고민하게 되었고, 값에 대한 score를 조회한 후 비지니스 로직에서 정렬하는 방식을 채택하게 되었다.
score 조회 명령어의 시간복잡도와, 비지니스 로직에서 정렬하는 데이터의 개수(10개)를 고려했을 때 처리속도에 큰 영향을 끼칠만큼의 복잡도가 아니라고 생각했기 때문이다.
글로 남기지 않은 많은 시행착오가 있었지만 결국 나름 괜찮은(?) 자동완성 API를 구현하게 된것 같다. 혹시 포스팅 관련하여 수정할 내용이나 피드백이 있다면 꼭! 꼭! 알려주시길 바란다 :)
8. 참고
1) RedisTemplate 공식문서 - https://docs.spring.io/spring-data/redis/docs/current/api/org/springframework/data/redis/core/RedisTemplate.html
2) Redis 명령어 - http://redisgate.kr/redis/command/zrange.php
'백엔드 > Redis' 카테고리의 다른 글
| [Redis] Redis를 활용한 자동완성 구현 (1) 및 자동완성 데이터 셋 만들기 (4) | 2023.06.09 |
|---|---|
| [Redis] 주소 검색에 대한 Redis 캐시 적용 및 개선 (0) | 2023.06.02 |