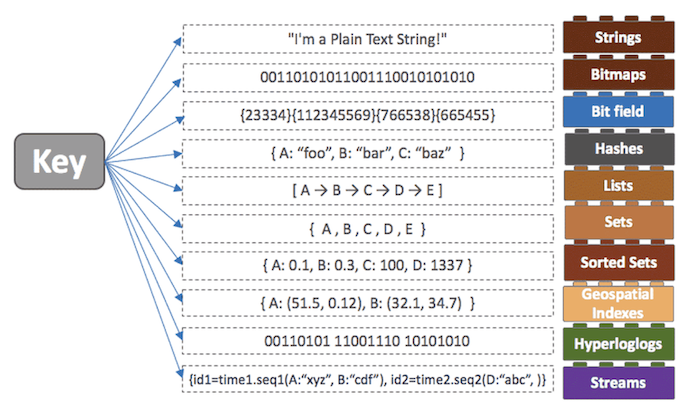
1. 개요
Redis를 활용하여 자동완성 기능을 구현해보았다.

2. Redis를 선택한 이유
2.1. 속도
Redis는 인 메모리에 데이터를 저장하고 조회하기 때문에 디스크에 저장하는 DB보다 훨씬 빠르다. 속도가 중요한 이유는 사용자가 단어를 한글자씩 입력할때마다 자동완성 값을 빠르게 뿌려줘야 하기 때문이다.
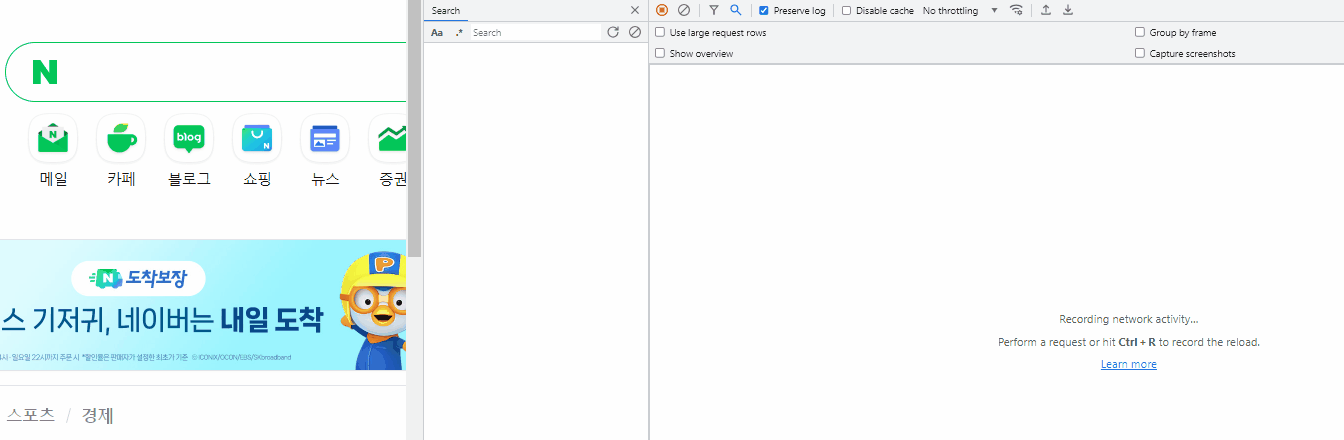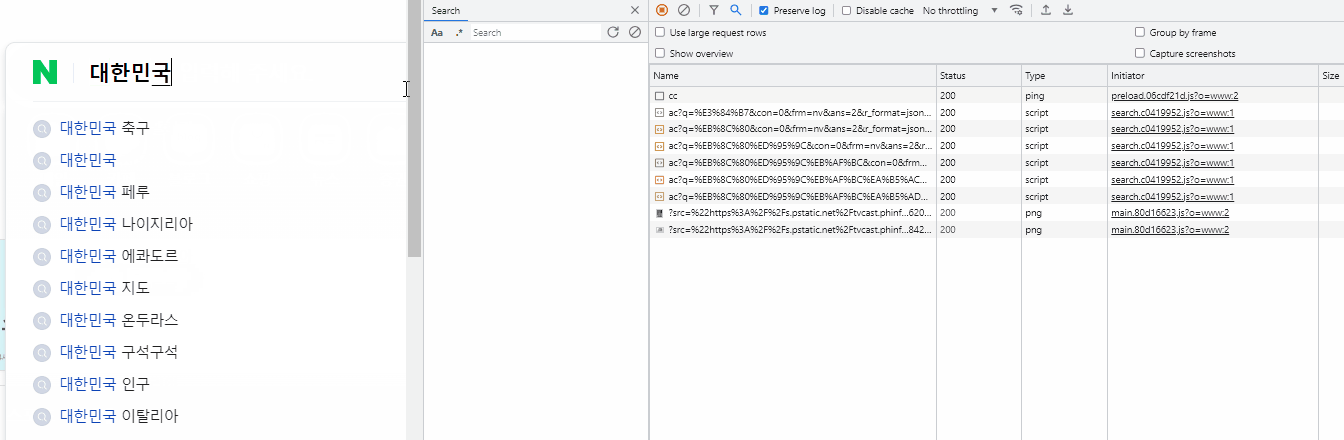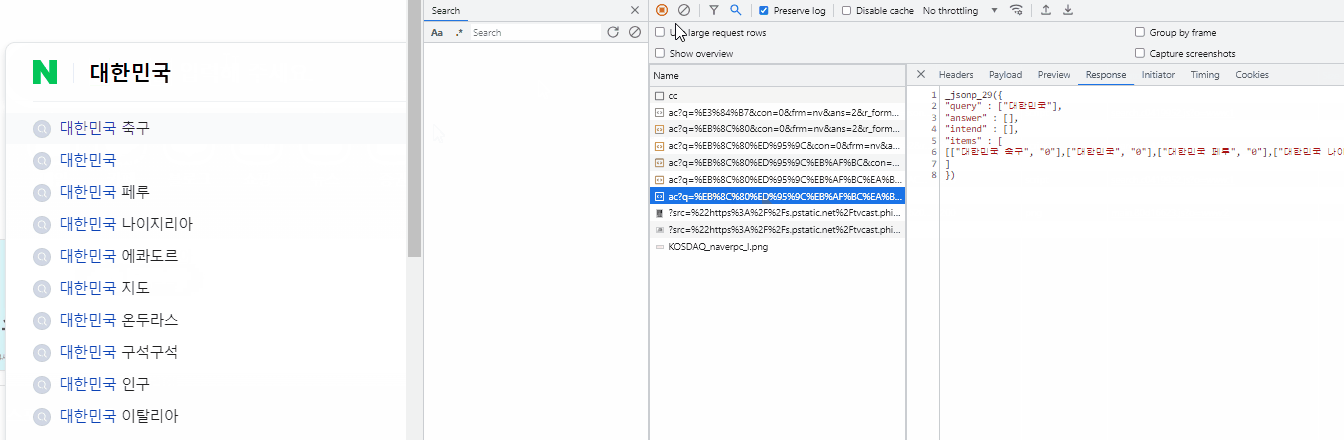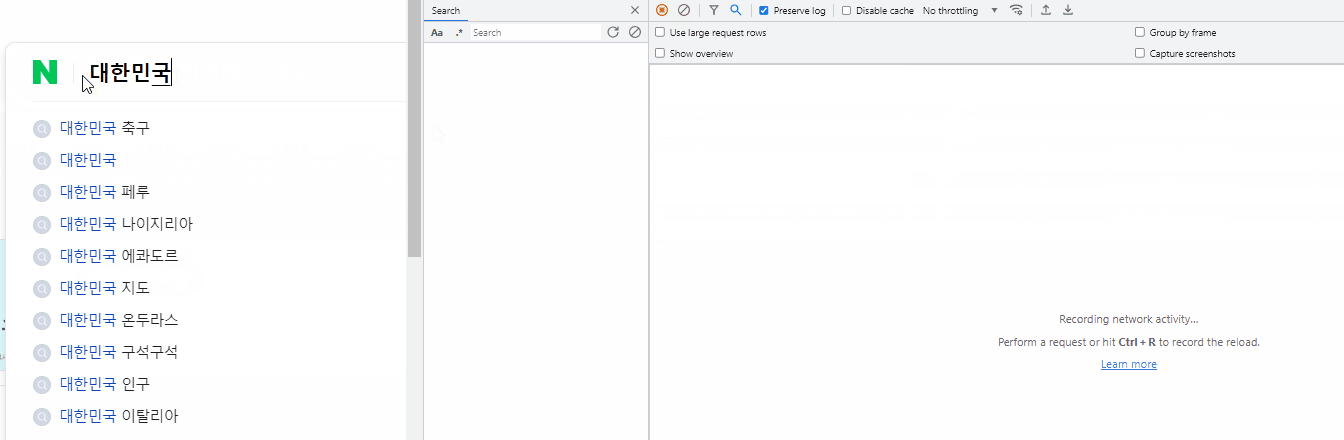
네이버에서 '가, 나, 다, 라' 단어를 입력하면 아래와 같이 '가, 가나, 가나다, 가나다라'에 대한 자동완성 조회 API로 통신한다. 프론트에 값이 미리 저장되어 있는 것처럼 즉시적으로 나오는데 서버 응답 값이다. 속도가 빠를수록 자동완성 리스트를 더 빨리 제공할 수 있으며, 조회의 성격이 강한 데이터이므로 Redis를 선택했다.
여담으로 네이버의 경우 입력한 검색어를 한번 더 입력할 경우 서버와 통신하지 않고 자동응답 값을 가져오고 있다. 서버에서 값을 조회했을 때 해당 검색어와 응답 데이터셋을 프론트에 저장해두고 가져다 쓰는 것 같다.
2.2. Sorted Set
Redis는 데이터를 저장하기 위한 다양한 자료구조를 제공한다. 그 중 Sorted Set은 문자열을 Score와 함께 관리하고, Score로 정렬되는 자료구조인데, 동일한 점수를 갖는 경우 '사전순'으로 정렬한다.
Redis 정렬 세트는 연관된 점수로 정렬된 고유한 문자열(구성원)의 모음입니다. 둘 이상의 문자열이 동일한 점수를 갖는 경우 문자열은 사전순으로 정렬됩니다. - https://redis.io/docs/data-types/sorted-sets/
일반적으로 검색어와 prefix가 일치하는 단어들을 자동완성 리스트로 뿌려야하는데, 사전순으로 정렬이 되어있다면 prefix가 일치하는 단어들은 검색어보다 뒤에 위치한다. 즉, 검색어의 index를 안다면 prefix가 일치하는 리스트를 뽑아낼 수 있다. 그리고 이 리스트가 자동완성 단어가 된다. 이러한 성격을 활용하면 어렵지 않게 자동완성 기능을 구현할 수 있다.
3. 관련 명령어
Sorted Set을 사용하기 위한 주요 Redis 명령어들이다. 이해를 위해 아래 명령어는 숙지하는 게 좋다.
3.1. ZADD
데이터 셋에 데이터를 Score와 함께 추가한다.
[ZADD key score value]
요청 > ZADD mydataset 1 한국
요청 > ZADD mydataset 2 미국
요청 > ZADD mydataset 3 러시아
요청 > ZADD mydataset 4 프랑스
요청 > ZADD mydataset 4 북한
요청 > ZADD mydataset 4 가나
3.2. ZRANGE
주어진 범위 내에 데이터 셋을 반환한다. Score가 적은 것부터 조회하며, 동일한 Score를 가진 데이터가 여러개 있을 경우 사전순으로 조회된다.
[ZRANGE key startIndex endIndex]
요청 > ZRANGE mydataset 0 -1
응답 >
1) 한국
2) 미국
3) 러시아
4) 가나
5) 북한
6) 프랑스
3.3. ZRANK
정렬된 기준이 오름차순이라고 가정하고 검색한 데이터의 index를 반환한다.
[ZRANK key value]
요청 > ZRANK mydataset 한국
응답 > 0
요청 > ZRANK mydataset 미국
응답 > 1
4. 분석
이제 Reids의 Sorted Set을 활용해 어떻게 구현할지 분석해보자.
4.1. 자동완성 단어 조회 매커니즘
기본적인 매커니즘은 어떤 값을 조회하면, 그 값을 prefix로 갖는 단어들을 조회하는 것이다.
'안' 이라는 값을 입력하면 '안경', '안경점'을 포함하는 리스트가 조회되어야 한다.
'안경' 이라는 값을 입력하면 '안경', '안경점'을 포함하는 리스트가 조회되어야 한다.
Sorted Set을 활용하면 이러한 구조를 쉽게 구현할 수 있다. 먼저 zadd를 통해 데이터 셋을 추가해주는데, '안경점' 이라는 문자를 추가하고자 할 경우, 이를 구성하는 [안, 안경] 이라는 문자열도 데이터 셋에 추가해줘야한다.
요청 > zadd mylist 0 안경점
요청 > zadd mylist 0 안경
요청 > zadd mylist 0 안
안경점 이라는 자동완성 단어를 추가하기 위해 Sorted Set에 0 Score로 '안경점', '안경', '안' 을 zadd 하였다. range mylist 0 -1로 모든 리스트를 조회하면 아래와 같이 사전순으로 '안', '안경', '안경점'이 조회된다.
요청 > zrange mylist 0 -1
응답 >
1) 안
2) 안경
3) 안경점
여기서 앞서 언급했던 매커니즘을 예시에 적용하면 ['안'을 조회하면, '안'을 prefix로 갖는 단어들이 조회되어야 한다.]이다. 그런데 사전순으로 정렬되어 있다보니 '안'을 prefix로 갖는 단어들은 '안'의 index를 포함하여 아래 위치한 값들이 된다. 마찬가지로 '안경'을 조회하면 '안경'을 prefix로 갖는 단어들은 '안경'이 갖는 index를 포함하여 아래 위치한 값들이다. 결국 검색어에 대한 index를 찾는다면 자동완성 단어를 추출할 수 있다. 이 index는 zrank 명령어로 찾으면 된다.
정리하면 zadd를 통해 자동완성 단어에 대한 데이터 셋을 만들고, zrank를 사용해 검색어에 대한 index를 찾고, zrange를 통해 index 부터 조회하여 연관 단어를 찾는 것이다.
4.2. 완전한 단어
'플레이스테이션' 이라는 단어로 예를 더 들어보겠다. 이 단어를 자동완성 단어로 사용하기 '플', '플레', '플레이' ... '플레이스테이션' 데이터들을 추가했다.
요청 > zadd mylist 0 플
요청 > zadd mylist 0 플레
요청 > zadd mylist 0 플레이
요청 > zadd mylist 0 플레이스
요청 > zadd mylist 0 플레이스테
요청 > zadd mylist 0 플레이스테이
요청 > zadd mylist 0 플레이스테이션
그리고 '플레이' 라는 단어에 입력했다고 가정하고 index를 구했다.
요청 > zrank mylist 플레이
응답 > 2
마지막으로 prefix를 가진 값들을 조회하기 index 부터 값을 조회했다.
요청 > zrange mylist 2 - 0
응답 >
1) 플레이
2) 플레이스
3) 플레이스테
4) 플레이스테이
5) 플레이스테이션
여기서 플레이스, 플레이스테, 플레이스테이와 같은 완전한 단어가 아니다. 이러한 값들은 자동완성 단어에 적합하지 않다. 하지만 없어서는 안된다. index를 찾아야만 완전한 단어를 검색할 수 있기 때문이다.
결국, 완전한 단어를 나타내는 데이터와 그 단어를 검색하기 위한 데이터를 구분해야한다. 이는 완전한 단어의 suffix에 '*'와 같은 구분자를 붙어주면 된다.
요청 > zadd mylist 0 플레이스테이션*
이 상태에서 다시 zrange를 하게 된다면 아래와 같이 값들이 조회될것이다.
요청 > zrange mylist 2 - 0
응답 >
1) 플레이
2) 플레이스
3) 플레이스테
4) 플레이스테이
5) 플레이스테이션
6) 플레이스테이션*
여기서 자동완성에 쓸 데이터는 완전한 단어인 '*'가 붙은 문자열들만 추출한 후 사용하면 된다. 이렇게 될 경우 플레이, 플레이스, 플레이스테이, 플레이스테이션을 검색해도 자동완성 리스트에 조회되는 결과는 플레이스테이션이라는 완전한 단어만이 조회될 것이다.
'*' 문자를 포함하는 데이터만을 추출하는 작업은 redis에서 지원하는 문법이 없는 관계로 비지니스 로직에서 처리하면 된다.
5. 데이터 셋 만들기
결국 위 내용에 따라 자동완성 데이터 셋들을 만들어야 한다. '플레이스테이션'이라는 단어에 대해서는 8개의 데이터를 redis에 넣어줘야한다. 엥? 필자는 많은 단어들을 넣어야하는데... 생각해보니 너무 오래걸릴 것 같아서 이 부분은 넘어가도록 하겠다.

는 대학생 과제 제출 시 마인드였고, 미래를 생각했을때 데이터 셋을 자동으로 생성해주는 뭔가가 있지 않을까 해서 구글링을 하였다. 마침 AWS 공식 블로그에서 Redis 자동완성 관련 내용을 다룬 게시글이 있었고 파이썬으로 데이터 셋을 만들어 redis에 넣는 코드가 있었다.
코드 내용을 분석하여 나에게 맞게 수정한 후 웹에서 파이썬 코드를 컴파일할 수 있는 https://replit.com/ 사이트에서 코드를 실행하였다. 여기 접속해서 아래 아래 코드를 실행시키면 Redis 서버로 위와 같은 데이터셋을 추가할 수 있다.
Redis Connection 에러 발생시!!
웹사이트에서 실행되는거라 그런지 host에 로컬 IP를 입력할 경우 redis connection refused 에러가 발생했다. 필자의 경우 포트포워딩 설정 후 host에 외부 IP를 입력해주니 connection 문제가 해결되었다.
Replit: the collaborative browser based IDE
Run code live in your browser. Write and run code in 50+ languages online with Replit, a powerful IDE, compiler, & interpreter.
replit.com
아래 코드에서 host, port을 입력하고 완전한 단어들이 들어있는 autocomplete.txt 파일을 생성해준다. text 파일은 왼쪽 파이썬 코드와 같은 레벨에 생성해주면 된다.
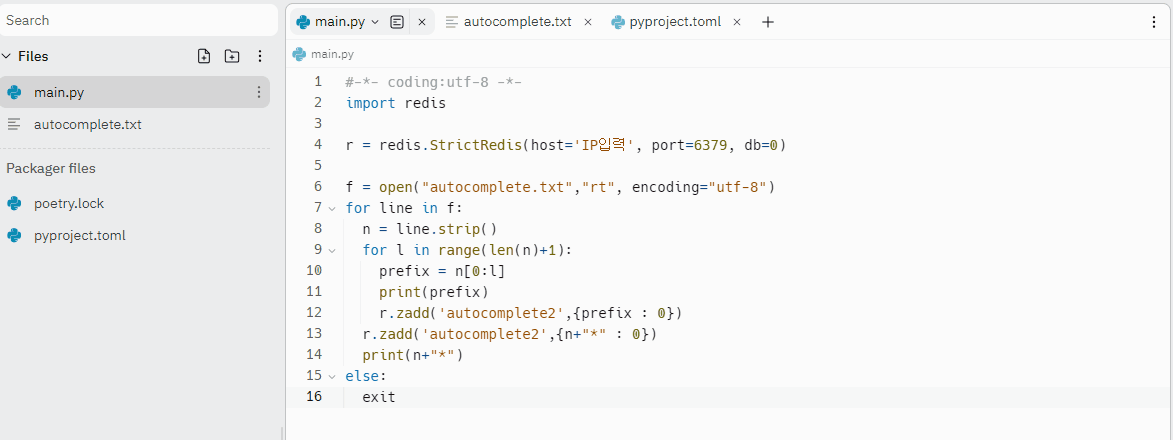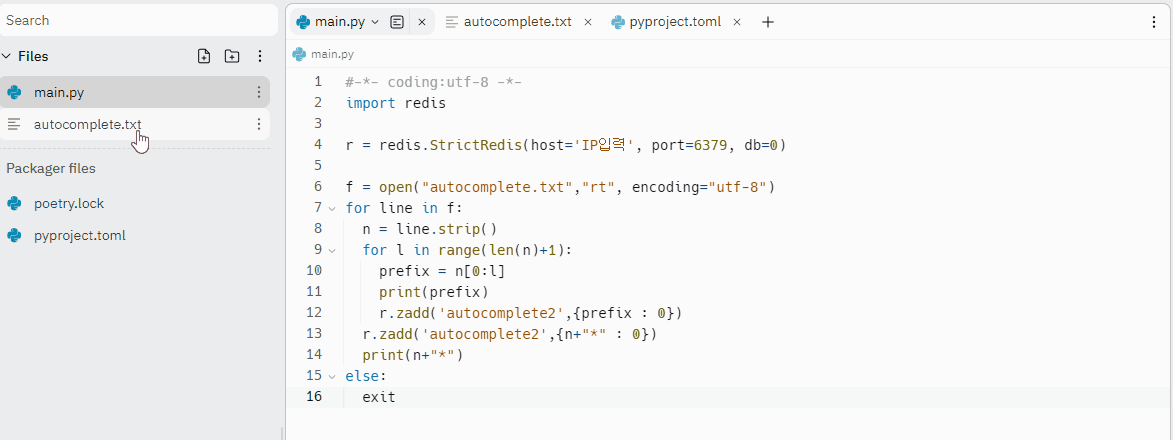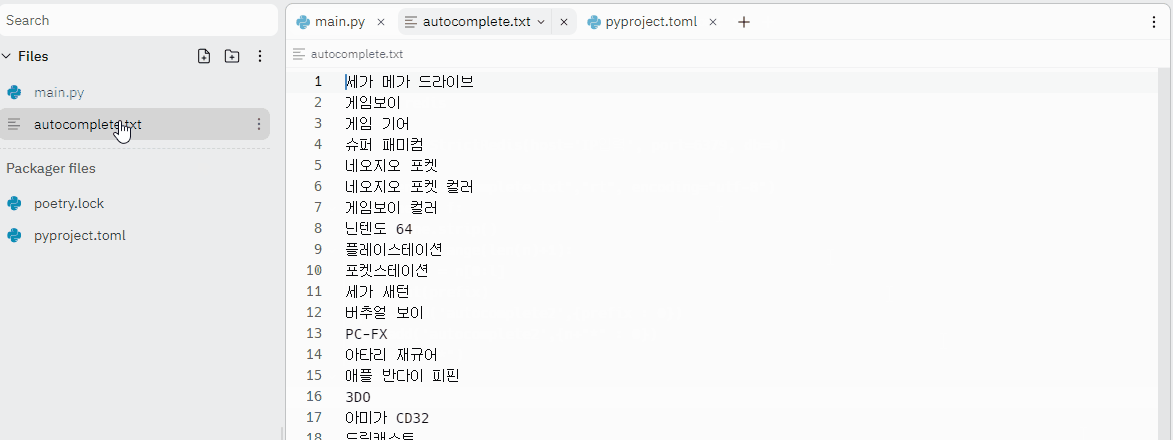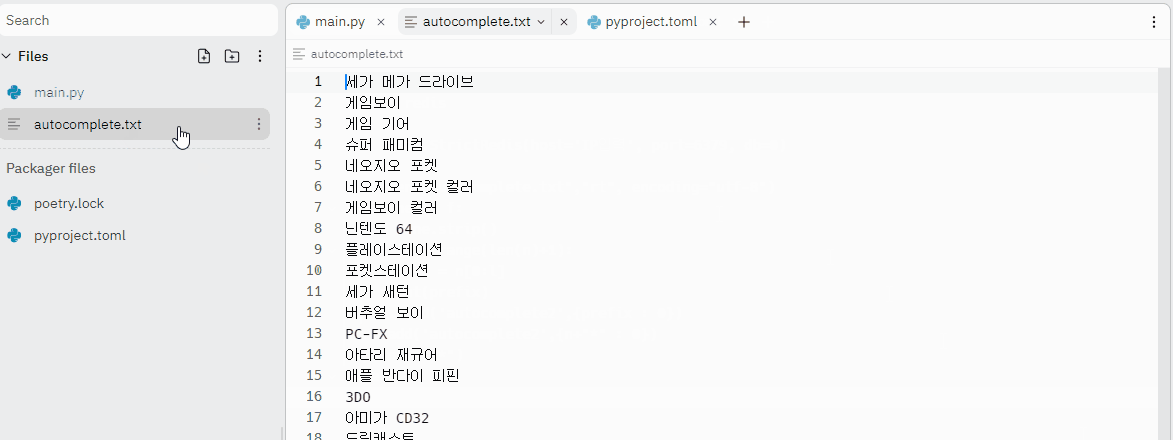
#-*- coding:utf-8 -*-
import redis
r = redis.StrictRedis(host='host 입력', port=port입력, db=0)
f = open("autocomplete.txt","rt", encoding="utf-8")
for line in f:
n = line.strip()
for l in range(len(n)+1):
prefix = n[0:l]
print(prefix)
r.zadd('autocomplete2',{prefix : 0})
r.zadd('autocomplete2',{n+"*" : 0})
print(n+"*")
else:
exit
여기서 또 여담하나 풀도록...(엣헴)
위 코드를 실행하고 redis에 들어간 데이터를 redis-cli로 확인해봤더니 아래와 같이 한글이 깨져서 들어갔다.

닌텐도와 닌텐도 DS라는 단어였는데 영어는 잘들어가고 한글은 깨져서 들어갔다. 이왕 사용할거 코드가 간단하기도 하고 스프링 기반으로 내가 직접 만들어보자라는 생각에 파이썬 코드를 분석하여 스프링 기반으로 만들었다.
나중에 알고보니 저렇게 깨지는건 필자가 언젠가 Redis 설정을 건들면서 발생한 문제로 한글이 깨져 보였던 것이었고, 재설치하니 잘 조회되더라. 참고로 저렇게 보여도 잘 들어간게 맞았습니다... (네?)
그렇다고 뻘짓을 한건 절대 아니다. 웹 사이트에서 실행 시 redis로 데이터가 들어가는 속도가 많이 느렸기 때문이다. git 잔디도 심었으니 오히려좋아...
6. 구현
코틀린 기반으로 로직을 구현했다. 설정 관련 코드와 주요 비지니스 로직이 담긴 Service 코드만 설명하겠다.
6.1. RedisConfig.kt
@Configuration
class RedisConfig(
@Value("\${spring.redis.port}") private val port: Int,
@Value("\${spring.redis.host}") private val host: String,
) {
@Bean
fun redisConnectionFactory(): RedisConnectionFactory? {
return LettuceConnectionFactory(host, port)
}
@Bean
fun redisTemplate(): RedisTemplate<String, String> {
val template = RedisTemplate<String, String>()
redisConnectionFactory()?.let { template.setConnectionFactory(it) }
template.keySerializer = StringRedisSerializer()
template.valueSerializer = StringRedisSerializer()
return template
}
}keySerializer와 valueSerializer를 모두 StringRedisSerializer로 설정하였다. 객체 형태의 value 값을 관리할 때에는 valueSerializer를 GenericJackson2JsonRedisSerializer 형식으로 설정하는데, 자동완성에 적용하니 큰따옴표(")로 인한 이슈가 발생했다.

'닌텐도', '닌텐도 DS' 문자로 데이터 셋을 만들면 위와 같이 문자열이 생성되는데 GenericJackson2JsonRedisSerializer 이 설정된 상태로 Redis에 데이터를 넣게 된다면 문자열마다 큰따옴표가 들어가게 된다. 아래와 같이 말이다.

의도했던 정렬 순서로
[닌, 닌텐, 닌텐도, 닌텐도*, 닌텐도(공백), 닌텐도 D, 닌텐도 DS, 닌텐도 DS*] 가 되어야 하는데 저 큰따옴표가 들어가는 바람에 사전순으로 정렬할 시 (공백)문자보다 큰따옴표를 나타내는 \" 문자가 뒤로 밀려
[닌, 닌텐, 닌텐도(공백), 닌텐도 D, 닌텐도 DS, 닌텐도 DS*, 닌텐도, 닌텐도*] 순으로 정렬이 되버렸다.
이 상태에서 '닌텐도 DS'를 검색한다면 '닌텐도 DS'와 '닌텐도' 가 조회되게 된다. 이 이슈로 인해 영향도를 분석 후 valueSerializer를 GenericJackson2JsonRedisSerializer 에서 StringRedisSerializer로 변경하였고, 큰따옴표로 인한 문제는 해결되었다.
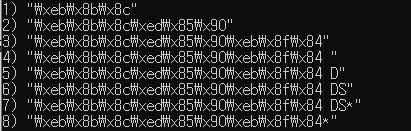
그런데 또다른 문제가 발생했다. 이번에는 완전한 단어를 나타내기 위해 넣었던 '*' 로 인해 발생했다. 현재 정렬되는 데이터 순서는 [닌, 닌텐, 닌텐도, 닌텐도(공백), 닌텐도 D, 닌텐도 DS, 닌텐도 DS*, 닌텐도*] 였기 때문에 '닌텐도 DS'를 검색한다면 위와 마찬가지로 '닌텐도 DS'와 '닌텐도'가 여전히 조회된다.
이에 대해 총 두가지 방법을 생각해냈다. 첫번째 방법은 검색어가 redis에서 추출한 데이터의 시작부분에 포함되어 있는지를 비지니스 로직에서 확인하는 것이고, 두번째 방법은 완전한 단어를 나타내는 문자 앞에 공백을 추가하여 '*'에서 ' *'로 변경하는 방법이었다.
결국은 첫번째 방법을 선택했는데, 그 이유는 이 과정이 필수적으로 들어가야 했기 때문이다. 플레이스테이션1, 플레이스테이션2 에대한 데이터 셋이 있을 때 '플레이스테이션'을 검색할 경우 [플레이스테이션1, 플레이스테이션2] 가 조회되어 정상으로 보이지만, '플레이스테이션1'을 검색할 경우 [플레이스테이션1] 뿐 아니라 [플레이스테이션 2]도 같이 조회되게 된다. 이 이유는 아래와 같이 플레이스테이션1보다 플레이스테이션2가 가나다 순으로 더 뒤에 위치하기 때문이다.
1)플
2) 플레
3) 플레이
...
x) 플레이스테이션1*
x+1) 플레이스테이션2
x+2) 플레이스테이션2*
6.2. AutocompleteService.kt
@Service
class AutocompleteService (
private val redisTemplate : RedisTemplate<String, String>,
@Value("\${autocomplete.limit}") private val limit: Long,
@Value("\${autocomplete.suffix}") private val suffix : String,
@Value("\${autocomplete.key}") private val key : String
){
fun getAutocomplete(searchWord : String) : AutocompleteResponse {
val zSetOperations = redisTemplate.opsForZSet()
var autoCompleteList = emptyList<String>()
zSetOperations.rank(key, searchWord)?.let {
val rangeList = zSetOperations.range(key, it, it+1000) as Set<String>
autoCompleteList = rangeList.stream()
.filter { value -> value.endsWith(suffix) && value.startWith(searchWord)}
.map { value -> StringUtils.removeEnd(value,suffix) }
.limit(limit)
.toList()
}
return AutocompleteResponse(autoCompleteList)
}
}sortedSet에 대한 작업을 수행할 수 있는 zSetOperation 객체를 생성하고, 위 매커니즘에서 언급했던 작업들을 구현하였다.
1) zSetOperations.rank(key, searchWord)?.ley{} : zrank를 명령어를 통해 검색어(searchWord) 데이터의 index를 구한다.
2) zSetOperations.range(key, it, it+1000) : zrange 명령어를 통해 index ~ index+1000 까지의 데이터를 조회한다. 사전순으로 정렬되어 있으니 index 와 가까운 위치에 자동완성 데이터가 존재할 것이기 때문이다. 이에 대한 가중치를 1000으로 설정하였기에 it+1000까지 조회하였다.
3) filter{value -> value.endsWith(suffix) && value.startWith(searchWord)} : 조회된 문자열 중 마지막이 suffix(=='*')로 끝나고, 검색어로 시작하는값들을 필터링한다.
4) map{ value -> StringUtils.removeEnd(value,suffix) } : 필터링 된 데이터들에 포함된 suffix를 제거한다.
5) limit(limit).toString() : 최대 limit개로 제한하여 리스트로 만든다.
7. 테스트
원하는 값들이 정상적으로 나옴을 확인할 수 있다. 지금은 URL에 일일이 입력하여 처리하고 있지만, 프론트 단에서는 검색란에 값을 입력하는 순간 위 API를 태우도록 구현하면 된다.

8. 회고
Sorted Set의 자료구조와 Redis 명령어들을 이해하기 위해 공식문서 위주로 보며 실습을 진행하였다. 어느정도 정리가 되니 어떻게 구현 방법을 계획했고, 실행에 옮겼다. 물론 이 과정에서 value 직렬화나, Redis 한글깨짐, 의도하지 않은 정렬 등 여러 이슈들을 마주했지만 그것들이 발생한 원인을 분석하고 해결해나가면서 배운 것들이 매우 의미있다고 생각한다.
지금은 정렬된 순서 그대로 자동완성 단어들을 뽑아내고 있지만, 단어의 검색 량에 따라 조회되는 우선순위를 달리하여 자동완성 단어들을 뽑아낼 수 있도록 수정해도 좋을 것 같다.
9. 참고
Redis Sorted Set - https://redis.io/docs/data-types/sorted-sets/
Redis Autocomplete - https://aws.amazon.com/ko/blogs/database/creating-a-simple-autocompletion-service-with-redis-part-one-of-two/
Redis Command - http://redisgate.kr/redis/command/zrange.php
'백엔드 > Redis' 카테고리의 다른 글
| [Redis] Redis를 활용한 자동완성 구현 (2) / 검색빈도 내림차순 조회 (2) | 2023.06.17 |
|---|---|
| [Redis] 주소 검색에 대한 Redis 캐시 적용 및 개선 (0) | 2023.06.02 |