1. 개요
앞선 포스팅에서는 Git Merge 에 대해 알아봤다. 코드 충돌이 나는 원인과 과정을 이해하고, Fast Forward Merge , 3-Way-Merge 가 어떤 상황에 발생하는지도 알았다. 다음은 병합과 연관되는 또 다른 명령어인 Rebase에 대해 알아보자. Rebase and Merge 전략이 있을 만큼 연관성있는 명령어이다.
2. Rebase 가 뭔가요? 🤔
Re-Base
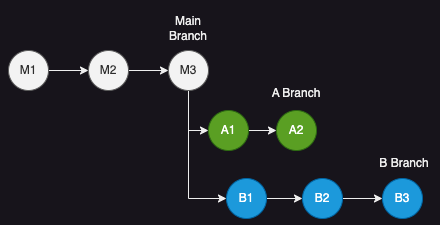
말 그대로 브랜치의 Base Commit(= Base) 를 재설정 (= Re) 하는 명령어이다.
A 브랜치에서 B 브랜치에 대한 Rebase를 할 경우 A 브랜치의 Base Commit이 B 브랜치의 Head Commit으로 변경된다.
3. 재설정하면 뭐가 좋은데요? 🤔
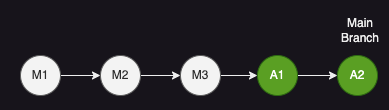
Fast Forward Merge를 통해 깔끔한 커밋 히스토리를 유지할 수 있다. 예를들어 Main 브랜치에서 A 라는 브랜치를 병합하기 전에, A 브랜치가 Main 브랜치에 Rebase 작업을 한다면 어떨까?
A 브랜치의 Base Commit이 Main 브랜치의 Head Commit으로 Re-base 될것이다.
이후 Main 브랜치에서 A 브랜치를 병합하면 어떻게 될까?
Fast Forward Merge가 되어 깃 히스토리가 직렬로 되어 깔끔하게 관리할 수 있다.
4. 자세한 예를들어 설명해주세요. 😖
아래의 깃 히스토리를 보자.
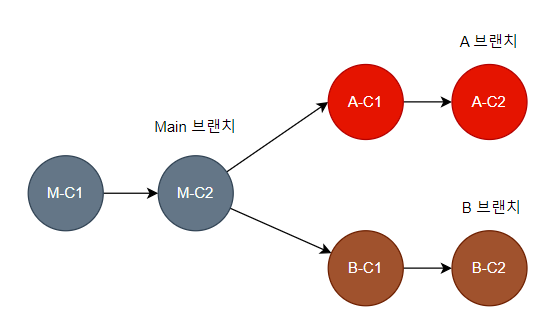
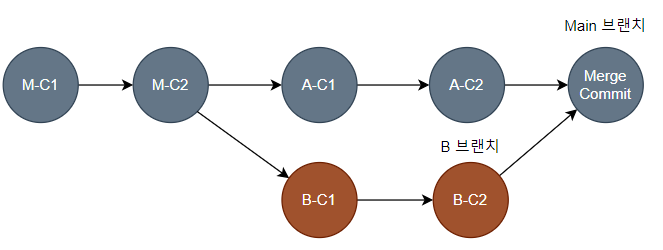
개발자는 D 기능 개발을 위해 Main 브랜치로부터 D 브랜치를 생성하고, 작업을 하며 D-C1, D-C2 Commit을 한 상황이다. 이때 D 브랜치의 Base Commit은 M-C2이다.

그리고 다른 개발자는 E 기능을 개발하기 위해 마찬가지로 Main 브랜치로부터 E 브랜치를 생성하고, 작업을 하며 E-C1 Commit을 한 상황이다. E 브랜치의 Base Commit은 M-C2이다.
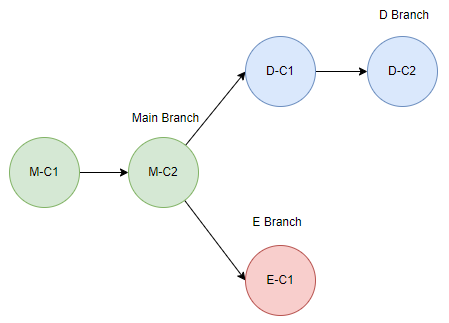
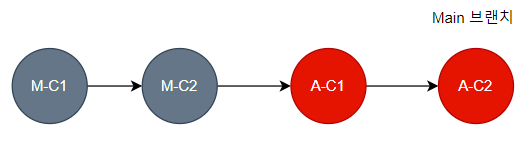
개발이 끝나고 테스트까지 마친 D 기능은 운영 반영을 위해 Main 브랜치에서 Merge 되게 된다. Main 브랜치의 Header Commit과 병합하려는 D 브랜치의 Base Commit이 일치하므로 Fast Forward 방식으로 병합된다.

곧이어 E 기능도 개발과 테스트가 끝났고, 운영 반영을 위해 Main 브랜치에서 Merge 하게 된다. 이때는 FF 병합이 불가능하므로 3-Way-Merge 방식의 병합이 진행된다.

5. Rebase 설명하랬더니 왜 Merge를...? 🙄
Rebase의 사용 목적을 이해하기 위함이다. 상황을 조금만 복잡하게 만들어보도록 하겠다.
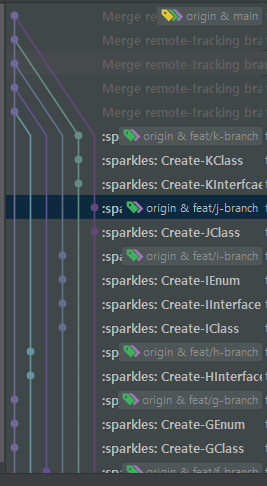
연초에 들어서니 개발 및 수정 요청건이 많아져 F, G, H, I, J, K 기능을 개발해야 하는 상황이 발생했다. 마찬가지로 Main 브랜치로부터 각각의 브랜치를 생성한 후 개발을 진행했으며, 결과적으로 아래와 같은 깃 히스토리가 만들어지게됐다.

이후 작업이 완료된 브랜치에 대해 하나씩 운영반영을 할 경우 Main 브랜치에서 브랜치별로 Merge 하게 된다. 몇일에 걸친 운영 반영을 모두 마치고 보니 아래와 같이 병렬 형태의 깃 히스토리가 생성되어 있었다. 예로 든건 6개의 브랜치이나, 작업이 더 추가되어 브랜치가 늘어날 경우 깃 히스토리는 두꺼운 병렬 형태를 띄게 되고, Main 브랜치에 대한 작업 히스토리를 파악하기 어려워진다.
6. Rebase를 하면 뭐가 달라지나요? 🤔
Rebase를 하면 어떻게 될까? 위 브랜치 중 F, G, H에 대해서만 시뮬레이션을 돌려보겠다.
본격적으로 들어가기 전 Rebase 의 정의를 리마인드 하도록 하겠다.
말 그대로 브랜치의 Base Commit(= Base) 를 재설정 (= Re) 하는 명령어이다.
A 브랜치에서 B 브랜치에 대한 Rebase를 할 경우 A 브랜치의 Base Commit이 B 브랜치의 Head Commit으로 변경된다.
먼저 F 브랜치 운영 반영을 위해 F 브랜치에서 Main 브랜치에 대해 Rebase를 한다.
Main 브랜치의 Head Commit은 Merge Commit이고, F 브랜치의 Base Commit 도 Main 브랜치의 Merge Commit 이므로 아무일도 일어나지 않는다.
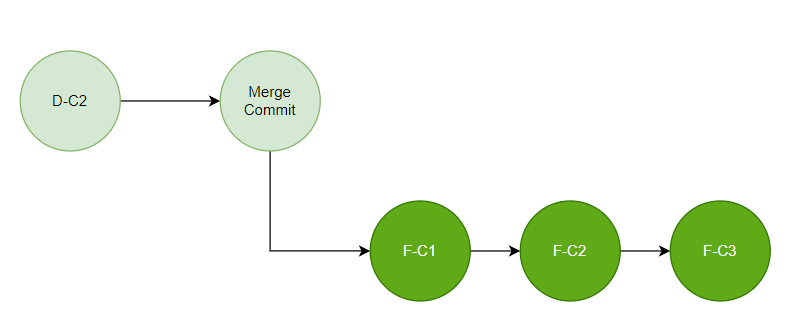
이제 Main 브랜치에서 F 브랜치를 Merge 하면 Fast Forward Merge 방식으로 병합된다.
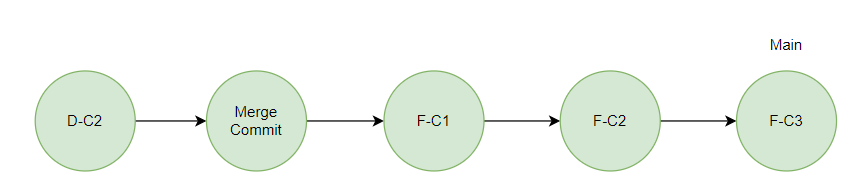
다음, H 브랜치 작업 운영 반영을 위해 H 브랜치에서 Main 브랜치에 대해 Rebase 한다.
Main 브랜치의 Head Commit은 F-C3 이고, H 브랜치의 Base Commit 은 Merge Commit 이므로
H 브랜치의 Base Commit은 F-C3로 변경된다.
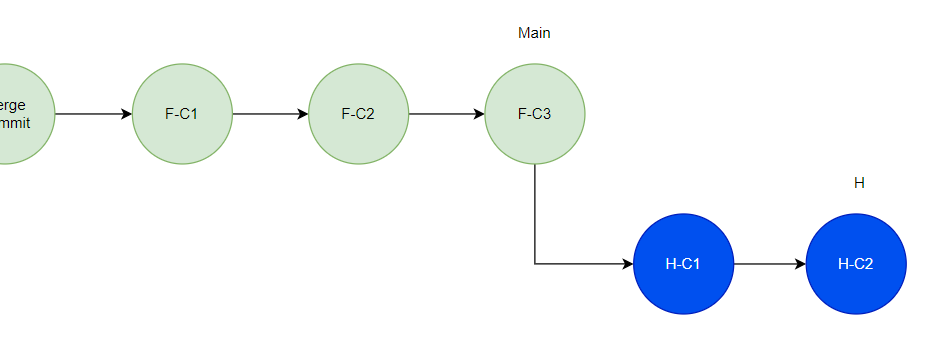
이제 Main 브랜치에서 H 브랜치를 Merge 하면 Fast Forward Merge 방식으로 병합된다.
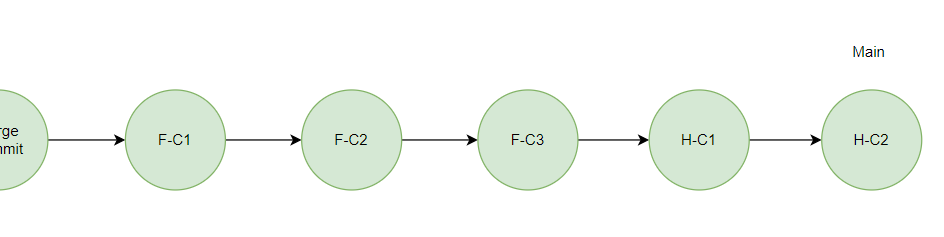
다음, G 브랜치 작업 운영 반영을 위해 G 브랜치에서 Main 브랜치에 대해 Rebase 한다.
Main 브랜치의 Head Commit은 H-C2 이고, G 브랜치의 Base Commit 은 Merge Commit 이므로
G 브랜치의 Base Commit은 H-C2로 변경된다.
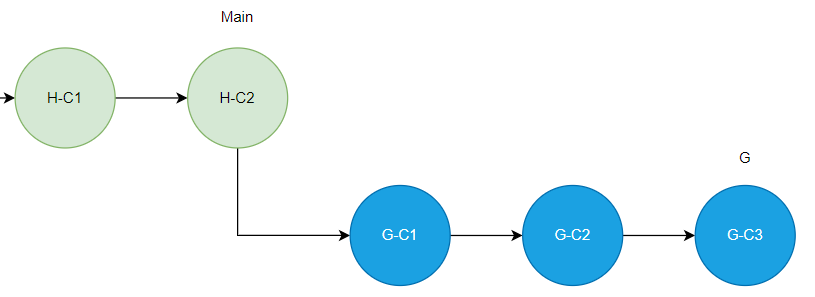
이제 Main 브랜치에서 G 브랜치를 Merge 하면 Fast Forward Merge 방식으로 병합된다.
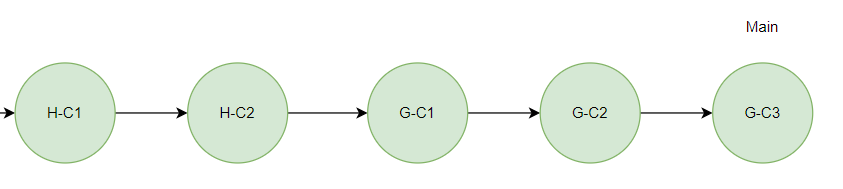
직접 테스트를 해보면 아래와 같이 직렬 형태의 깃 히스토리가 남는 것을 알 수 있다. 알아보기도 쉽다.
즉, Rebase를 통한 Merge를 하면 보기 쉬운 형태로 깃 히스토리를 관리하게 된다.
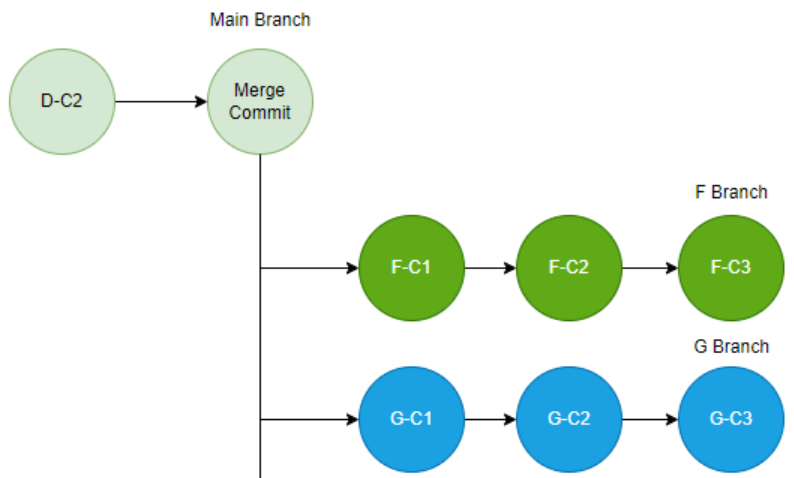
7. 위험이 도사리고 있는 Rebase 👺
Rebase를 사용하면 간단하게 Base Commit이 변경된다고 설명했지만, 사실 위험한 작업이다. 왜 위험할까?
Origin 입장에서 생각해보자.
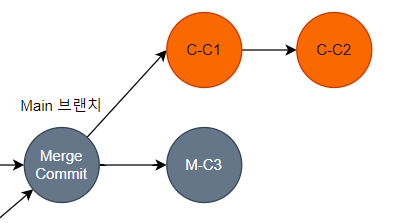
G 브랜치에서 작업 후 PUSH를 했을테니 로컬, 원격 브랜치 모두 아래와 같이 G-C1, G-C2, G-C3 커밋이 있었을 것이다.
그런데 G 브랜치에서 Main 브랜치에 대해 Rebase, 정확히 말하면 로컬 G 브랜치에서 Main 브랜치에 대해 Rebase를 한다. 그럼 로컬 G 브랜치의 깃 히스토리는 아래와 같이 변경된다. 이때 push를 하면 어떻게 될까?
그렇다. 충돌이 발생한다. Rebase 에 의해 로컬 브랜치의 깃 히스토리가 변경되었고 원격 브랜치로 Push 하려 하니 원격 브랜치 입장에서 깃 히스토리가 일치하지 않아 충돌이 발생하는 것이다. 원격 브랜치 입장에서는 로컬 브랜치가 자신과 이름만 같은 브랜치인 것이다.
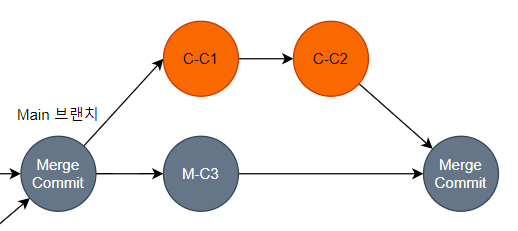
로컬, 원격 브랜치의 조상 Commit 이 다르니 3-Way-Merge 방식을 통해 아래와 같이 병합된다.
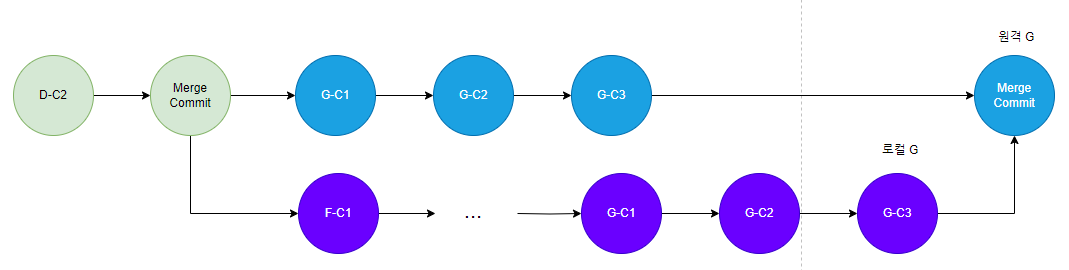
결과적으로 Rebase를 했더니 동일 브랜치간 Merge 작업이 추가되고, Main 에서 이를 Merge하면 이러한 히스토리도 남게된다. 이렇게 보니 그냥 Merge를 하는것 보다 못하는 상황이다.
앞서 예시에서 보여준 Rebase는 이러한 케이스가 없었다. 즉, 로컬, 원격 브랜치가 충돌이 일어나지 않았다는 건데, 이건 무엇을 의미할까?
바로 강제 Push 를 통해 로컬과 원격 브랜치 간 히스토리를 맞춰준 것이다. 즉, Rebase를 하면 강제 Push 작업이 동반된다.
이러한 강제 Push는 해당 브랜치에 협업자가 있을 경우 큰 문제를 야기할 수 있다. 특히 이러한 사실을 몰랐을 때 예기치 못한 상황에 당황할 수 있고, 자신이 Push 했던 작업 내역을 잃어버릴 수도 있다.
1번 개발자가 G 브랜치를 pull 받은 후 Rebase 한 이후 시점에 2번 개발자가 G 브랜치에 작업 내역을 push 한다면, 1번 개발자의 로컬 G 브랜치에는 2번 개발자가 작업한 내용이 반영되지 않은 상태이다. 이때 1번 개발자가 Rebase 한 내역을 원격 브랜치에 덮어쓰기 위해 강제 push를 하게 된다면 2번 개발자가 작업한 내용과 히스토리 모두 날아가게 된다.
다행히도 이 문제는 강제 push 시 force-with-lease 옵션을 사용하면 해결된다. 로컬 저장소와 원격 저장소를 비교했을 때, 원격 저장소에 새로운 커밋이 추가되어 있는 경우 강제 Push 작업을 취소시키는 옵션이다.
8. 양날의 검 Rebase
Rebase는 깔끔한 깃 히스토리를 관리하고, 매우 단순하게 동작하는 착한(?) 명령인줄 알았으나, 깃 히스토리를 조작하고, 강제 Push 를 동반해야하는 위험한 녀석이었다. 이러한 위험성을 인지하고, 협업자와 충분한 소통과 함께 사용한다면 큰 문제가 없을테지만, Git을 통한 협업이 어색하고, Rebase의 동작과 위험성을 충분히 인지하지 못한 상태에서 사용한다면 코드를 날려먹거나 협업 간 사소하지 않은 문제를 야기할 수 있을 테니 조심히 사용하자.
'Git' 카테고리의 다른 글
| [Git] Git Merge 란? / 쉽게 이해하기 / Fast Forward / 3-way-merge (0) | 2024.04.22 |
|---|