제네릭을 사용하면 많은 비검사 경고들을 마주한다. 필자의 경우 이러한 경고들은 IDE의 도움을 받아 수정했으며, 수정 자체에 큰 의의를 두진 않았다. 하지만 이러한 경고를 제거하는 것만으로 그 코드는 ClassCaseException이 발생할 일이 없는 타입 안전성을 보장하는 코드가 된다고 한다. 이제 비검사 경고를 제거하는 올바른 방법을 알아보자.
컴파일러의 도움을 받아 제거하라
대부분의 경고는 컴파일러가 알려준 대로 수정하면 사라진다.
Set<Coin> coinSet = new HashSet();
위 코드는 '매개변수화된 클래스 HashSet을 원시사용 했다.' 라는 경고가 발생한다. 매개변수화된 클래스는 제네릭 클래스를 나타낸다. 즉, 제네릭 클래스인데 타입 매개변수를 사용하지 않았다는 경고이다.
Set<Coin> coinSet = new HashSet<Coin>();
Set<Coin> coinSet = new HashSet<>(); // 컴파일러의 추론 기능 활용
위와 같이 타입 매개변수를 명시하여 경고를 해결할 수도 있지만 다이아몬드 연산자(<>) 만으로 해결할 수 있다. 컴파일러가 올바른 실제 타입 매개변수를 추론해주기 때문이다.
경고를 제거할 수 없지만 타입 안전함이 확신된다면 경고를 숨겨라
타입 관련 경고를 제거하려면 @SuppressWarnings("unchecked") 어노테이션 사용하면 된다. 이 어노테이션은 개별 지역변수 선언부터 클래스 전체까지 어떤 선언에도 달 수 있지만 가능한한 좁은 범위에 적용해야 한다. 보통 변수 선언, 아주 짧은 메서드, 생성자에 사용되며, 절대 클래스 전체에 적용해서는 안된다.
아래는 ArrayList의 toArray 메서드이다.
public <T> T[] toArray(T[] a) {
if (a.length < size)
// Make a new array of a's runtime type, but my contents:
return (T[]) Arrays.copyOf(elementData, size, a.getClass());
System.arraycopy(elementData, 0, a, 0, size);
if (a.length > size)
a[size] = null;
return a;
}
return 문에는 해당 어노테이션을 적용할 수 없으므로, 아래와 같이 변수를 선언하고 어노테이션을 적용해준다. 또한 경고를 무시해도 되는 안전한 이유를 항상 주석으로 남겨둔다.
public <T> T[] toArray(T[] a) {
if (a.length < size) {
// 생성한 배열과 매개변수로 받은 배열의 타입이 모두 T[]로 같으므로 올바른 형변환이다.
@SuppressWarnings("unchecked")
T[] result = (T[]) Arrays.copyOf(elementData, size, a.getClass());
return result;
}
System.arraycopy(elementData, 0, a, 0, size);
if (a.length > size)
a[size] = null;
return a;
}
SuppressWarnings 옵션
옵션
내용
all
모든 경고
cast
캐스트 연산자 경고
dep-ann
사용하지 말아야할 주석 경고
deprecation
사용하지 말아야할 메서드 경고
fallthrough
switch 문 break 누락 경고
finally
반환하지 않은 finally 블럭 경고
null
null 경고
rawtypes
제네릭을 사용하는 클래스 매개변수가 불특정일때 경고
unchecked
검증되지 않은 연산자 경고
unused
사용하지 않은 코드 관련 경고
정리
비검사 경고는 중요하니 무시하지 말자. 모든 비검사 경고는 런타임에 ClassCastException을 일으킬 수 있다. 경고를 없앨 방법을 찾지 못했다면, 그 코드가 타입 안전함을 증명하고 가능한 한 범위를 좁혀 @SuppressWarnings("unchecked") 어노테이션으로 경고를 숨기자. 그런 다음 경고를 숨긴 근거를 주석으로 남긴다.
OAuth2와 JWT를 사용하여 인증 정책을 수립했다. 그런데 문제가 발생했다. 인증이 필요한 API 요청 시 403 에러가 발생하는 것이다. 헤더에 JWT 토큰도 잘 들어가 있고, 토큰 값을 통해 생성한 인증객체도 Security Context Holder에 들어가 있으며, 인가 권한은 ROLE_USER 인데 말이다. 원인을 파악해보자.
뜬금없이 발생하는 403
Security Filter Chain 주요 필터
Security Filter Chain 주요 필터
원인을 찾기 전 현재 Security Filter의 구성이 어떻게 이루어져있는지 간단하게 정리해보았다.
1. OAuth2AuthorizationRequestRedirectFilter
OAuth2AuthorizationRequestRedirectFilter에서는 yml 또는 properties에 설정한 값을 기반으로, registrationId에 대한 OAuth2 인증 서버의 로그인 URI를 redirect 해준다.
시큐리티 설정에 OAuth2 로그인 요청 URI는 아래와 같은 형식으로 정의해달라고 하는데, 그 이유가 바로 이 필터를 거치게 하려 함이다.
/oauth2/authorization/[registrationId]
2. OAuth2LoginAuthenticationFilter
OAuth2LoginAuthenticationFilter 에서 하는 일이 아주 많다.
첫째, 로그인 성공 시 자신의 서버로 redirect 되는 authorization code를 받고,
둘째, authorization code 를 활용하여 OAuth2 인증 서버로 accessToken을 요청하고,
셋째, accessToken을 활용하여 OAuth2 리소스 서버로 유저 정보를 요청한다.
넷째, OAuth2UserService 구현체 인스턴스를 호출하며, 내부에서 Authentication 인스턴스를 생성한다.
정리하면, OAuth2 인증을 받고, 인증 유저에 대한 정보를 획득한 후 인증 객체를 생성하는 역할이다.
참고로 인증이 성공하면 추후 AuthenticationSuccessHandler의 구현체 인스턴스를 호출하게 되는데 이때 JWT 토큰을 발급하며, 클라이언트는 이 값을 받아 헤더에 추가한다. (이건 필자의 인증 정책 중 하나이니 굳이 이해할 필요는 없다. JWT 를 발급한다는 것만 알면 된다.
3. JWT Filter
헤더의 JWT 토큰 값을 추출 후 검증한다. 유효한 토큰일 경우 Authentication 객체를 생성하여 Security Context Holder 내에 저장한다.
로그인은 성공했으나, 인증된 자원에 대한 요청은 실패
OAuth2 로그인은 성공하고 JWT 토큰도 잘 발급이 되고, 헤더로 유효한 JWT 토큰도 오는 걸 확인했으나, 인증이 필요한 API 요청에만 실패했다. SpringSecurity 설정에 인증 필터를 거치지 않도록 설정한 view/login, /error 등에 대해서는 403 에러가 발생하지 않는 점을 고려해봤을 때 시큐리티 필터에서 '인증' 관련 문제가 있음을 추정하게 되었다.
public class SecurityConfig {
private final UserRepository userRepository;
private final JwtProvider jwtProvider;
@Bean
public SecurityFilterChain filterChain(HttpSecurity http) throws Exception{
http
.authorizeHttpRequests((authz -> authz
.requestMatchers("/api/**").hasRole("USER")
.anyRequest().authenticated())
)
...
return http.build();
}
@Bean
public WebSecurityCustomizer webSecurityCustomizer() {
return (web) -> web.ignoring().requestMatchers("/view/login", "/error", "/error/*", "/img/**", "/favicon.ico");
}
}
발견되지 않는 에러 로그
일반적으로 예외가 발생하면 에러 로그가 콘솔에 출력될텐데, 에러 로그가 출력되지 않았다. 시큐리티 로그에 /error 경로에 대한 요청이 들어오는걸로 봐서 내부 어딘가에서 예외가 발생했고, /error 경로로 리다이렉트 된것 같은데, 에러 로그가 보이지 않아 근원지를 찾을 수 없었다.
루트 로그 레벨을 trace 로 변경
/error 리다이렉트 원인이 되는 로그가 분명 찍었을 것이라 판단하고 루트 로그 레벨을 trace로 변경해보았다. 그리고 다시 실행을 하니 원인을 찾을 수 있었다. AuthrozationFilter에서 AccessDeniedException이 발생했고, 이로 인해 /error 경로로 리다이렉트 되고 있던 것이었다. 놀랍게도 로그 레벨은 TRACE 였다.
TRACE 에러는 왜...TRACE 레벨로 발생하는 예외
AuthorizationFilter 예외 발생 원인 분석
내부 소스를 확인해 보니 authrozationManager.check() 호출 후 얻은 AuthroziationDecision의 isGranted() 메서드의 호출 결과에 따라 Access Denied 예외가 발생함을 확인할 수 있었다. isGranted의 구현체 클래스를 따라가니 아래의 세 조건을 만족할 경우에만 true를 리턴하고 있었다.
예외 발생 부분isGranted 메서드
그런데 필자가 생성했던 Authentication 객체는... authenticated 값이 false 였던..것이었다.
지나갑니다~
아... 나 커스텀 Authentication 클래스 사용했었구나.
커스...터뮤ㅠㅠ
커스텀 Authentication 클래스 확인
헐레벌떡 확인해보니 부모 클래스에 authenticated 값이 있었지만, 따로 설정해주지 않았고, 부모 생성자만 호출해서는 authenticated 값도 설정되지 않고 있었다. 그렇다. 따로 설정을 해줬어야 했다.
public class UserAuthenticationToken extends AbstractAuthenticationToken {
private final Long principal;
private final String credentials;
public UserAuthenticationToken(Long userId, String email, Collection<? extends GrantedAuthority> authorities) {
super(authorities);
this.principal = userId;
this.credentials = email;
}
@Override
public String getCredentials() {
return credentials;
}
@Override
public Long getPrincipal() {
return principal;
}
}
super.setAuthenticated(true) 코드를 넣어 authenticated 값을 true로 설정했다.
유저에 대한 '인가'를 하면 당연히 '인증'된 객체로 처리될 줄 알았으나, 안된다. 비록 삽질을 하긴 했지만 매우 건강한 삽질이 아니었나 싶다.
Authentication 객체의 authenticated 값을 AuthorizationFilter 에서 확인한다는 것과 커스텀 Authentication 클래스를 사용할 때 권한을 인가할지라도 인증은 되지 않아 authenticated 값이 자동으로 설정되지 않는다는 것도 알게 되었다. 인증 객체의 부모 생성자 메서드를 좀더 자세히 확인했더라면, 이 문제는 발생하지 않았을 테지만 OAuth2 필터 복습도 하고, 인증 매커니즘에 대해 다시 한번 정리를 하게 된 건강한 삽질이었다!
이번 아이템에서도 생소한 용어인 '로 타입'이 등장했다. 로 타입이 뭐길래 사용하지 말라는 걸까?
로 타입
제네릭 타입에서 타입 매개변수(괄호 < > 안에 들어가는 타입 값)를 사용하지 않았을 때의 타입을 말한다. List<E>의 로 타입은 List, ArrayList<E>의 로 타입은 ArrayList 이다.
List list = ... // 로 타입!
로 타입의 사용 예
아래는 로 타입을 사용하는 예이다. 컴파일 시 오류가 발생하지 않으나, 런타임 시 타입 오류가 발생한다. Coin을 Money로 캐스팅하려하니 에러가 나는 건 당연하지만 중요한건 이 에러가 컴파일에는 발생하지 않는다는 점이다. 이런 케스팅 에러는 런타임보다 컴파일 타임에 발견되는 것이 좋다.
List list = new ArrayList();
Coin coin = new Coin();
list.add(coin); // 실수로 Coin 인스턴스를 추가하였다.
Money getCoin = (Money) list.get(0); // 런타임 시 ClassCastException이 발생한다.
컴파일 타임에 발견되는 캐스팅 에러
타입 매개변수를 사용한다면 컴파일 타임에에 컴파일러가 오류를 캐치하게 된다. 그럼 변수 초기화 시 타입 매개변수를 사용하면 무조건 해당 변수는 타입 안전성을 갖게되는걸까? 그건 아니다.
List<Money> list = new ArrayList(); // 타입 매개변수 사용
Coin coin = new Coin();
list.add(coin); // 컴파일 에러 발생!
Money getCoin = list.get(0);
메서드 파라미터에 사용되는 로 타입
앞에서 제공한 코드 중간에 unsafeAdd 메서드가 추가되었고, 로 타입으로 list 값을 받고 있다. 이때 list.add(o) 부분에서 과연 컴파일 또는 런타임 에러가 발생할까?
List<Money> list = new ArrayList();
Coin coin = new Coin();
unsafeAdd(list, coin);
Money getCoin = list.get(0);
...
public static void unsafeAdd(List list, Object o){
list.add(o); // 예외가 발생할까요?
}
list 에 대한 타입 매개변수를 Money로 했으니 당연히 list.add(o) 부분에서 컴파일 예러가 발생한다고 생각할 수 있지만 그렇지 않다. 심지어 list.add(o) 시 런타임 예외도 발생하지 않는다. Coin 타입의 인스턴스가 Money 타입의 list에 잘 들어간다. 대신 list.get(0) 을 통해 값을 조회할 때 ClassCastException이 발생한다.
list 변수의 타입 안전성이 unsafeAdd 메서드에 추가한 '로 타입' 매개변수에 의해 파괴되는 순간이다.
List<Money> 타입의 list에 Coin 인스턴스가 들어있는 상황
로 타입을 사용하면 안되는 이유
💡 제네릭 타입이 제공하는 타입 안정성과 표현력을 굳이 버리는 꼴이다. 제네릭 타입에서 공식적으로 발을 뺀 타입이다.
로 타입 완전 별로인데 그냥 자바 진영에서 제명하면 안돼?
로 타입을 폐기할 수 없는 이유는 개발자들이 제네릭을 받아들이는데 오랜 시간이 걸렸고, 이미 '로 타입'으로 작성된 코드들이 너무 많았기 때문에, 그 코드와의 호환성을 위해 남겨두고 있는 것이라고 한다.
모든 타입을 허용하려면 로타입 말고 Object 타입으로 사용하자
모든 타입을 허용하는 변수를 정의할때는 정해진 타입이 없으니 로 타입으로 쓸 수 있지만, 제네릭 타입에서 발을 뺀 로 타입을 쓰는 것 자체가 모순이다. 이때는 로 타입 대신 Object 타입을 사용하자.
Coin coin = new Coin();
Money money = new Money();
List<Object> list = new ArrayList<>(); // 로 타입 대신 Object 타입
list.add(coin);
list.add(money);
Coin getCoin = (Coin) list.get(0);
Money getMoney = (Money) list.get(1);
메서드 파라미터는 타입 매개변수를 Object 타입으로 만들 수 없다.
모든 타입을 허용하는 메서드를 만들고, 여러 타입 매개변수를 가진 리스트에서 이를 재사용하도록 만들 수 있을까? 실제로 Object 타입을 가진 list를 매개변수로 받는 add 메서드를 구현했더니 컴파일 에러가 발생한다. 컴파일 에러가 발생하는 이유는 List<Object> 타입과 List<Coin> 타입이 다르기 때문이다.
List<Money> list = new ArrayList<>();
Coin coin = new Coin();
objectAdd(list, coin); // 컴파일 에러
Coin getCoin = (Coin) list.get(0); // 컴파일 에러
...
public static void objectAdd(List<Object> list, Object o){
list.add(o);
}
비한정 와일드카드 타입 활용
컴파일 에러를 해결하기 위해 비한정 와일드카드 타입을 쓸 수도 있다. 하지만 와일드 카드를 사용할 경우 타입 안전성을 지키기 위해 null 외에 아무 값도 넣지 못하게 된다. 즉, 타입 안전성을 훼손하는 모든 작업은 할 수 없는 것이다. 단, get과 같은 작업은 타입 안전성을 훼손하지 않으므로 가능하다.
List<Money> list = new ArrayList<>();
Coin coin = new Coin();
objectAdd(list, coin);
...
public static void objectAdd(List<?> list, Object o){
list.add(o); // 컴파일 에러
list.get(0); // 컴파일 에러는 발생하지 않음.
}
만약 모든 타입에 대해 타입 안전성을 훼손하지 않는 비지니스 로직을 처리해야할 경우 비한정 와일드카드 타입을 활용하겠지만, 그게 아니라면 굳이 모든 타입을 허용하는 메서드를 만들 필요는 없다고 생각한다.
로 타입을 사용하는 예외 상황
로 타입을 사용해야 하는 상황도 있다.
1. class 리터럴
class 타입이 들어가야하는 자바 문법에 List.class 와 같은 로 타입은 허용하지만, List<String>.class와 같은 매개변수화 타입은 허용하지 않는다.
2. instanceof 연산자
instanceof 연산자는 비한정적 와일드카드 타입과 로 타입 말고는 적용할 수 없다.
정리
로 타입을 사용하면 런 타임에 예외가 일어날 수 있으니 사용하면 안된다. 로 타입은 제네릭 도입에 따른 호환성을 위해 제공될 뿐이다.
'태그달린 클래스'라는 단어가 되게 생소하다. 이에 대한 의미를 이해하고, 이 클래스가 과연 어떤 단점을 갖길래 계층구조로 리팩토링 하라는지도 이해해보자.
태그달린 클래스란?
태그달린 클래스란 멤버 필드와 관련있다. 멤버 필드가 클래스의 유형을 나타내는 경우 해당 멤버 필드를 태그 필드라고 한다. 그리고 태그 필드를 갖는 클래스를 태그달린 클래스라고 한다.
태그 달린 클래스의 예
Figure 클래스는 shape 필드가 이 클래스의 유형을 나타낸다. 즉, 태그 필드이다. 유형마다 생성자가 따로 존재하며, area 메서드의 동작도 달라지는 것을 볼 수 있다. 이러한 클래스의 단점을 하나씩 짚어보자.
public class Figure {
enum Shape { RECTANGLE, CIRCLE };
// 태그 필드 - 현재 모양을 나타낸다.
final Shape shape;
// 다음 필드들은 모양이 사각형(RECTANGLE)일 때만 쓰인다.
double length;
double width;
// 다음 필드는 모양이 원(CIRCLE)일 때만 쓰인다.
double radius;
// 원 생성자
Figure(double radius){
shape = Shape.CIRCLE;
this.radius = radius;
}
Figure(double length, double width){
shape = Shape.RECTANGLE;
this.length = length;
this.width = width;
}
double area(){
switch (shape){
case RECTANGLE:
return length * width;
case CIRCLE:
return Math.PI * (radius * radius);
default:
throw new AssertionError(shape);
}
}
}
태그달린 클래스의 단점
1. 쓸데없는 코드가 많다
열거 타입 선언, 태그 필드, switch 등 쓸데없는 코드가 많다. 이런 코드가 많은 이유는 이 클래스로 생성되는 인스턴스가 여러 유형(태그)을 가질 수 있기 때문이다.
2. 가독성 저하
한 클래스에 여러 유형에 대한 로직이 혼합돼어 있어 가독성이 저하된다.
3. 불필요한 초기화가 늘어난다.
멤버 필드의 불변성을 명시하기 위해 필드를 final로 선언한다. 위와 같은 코드는 필드를 final로 선언하려면 해당 태그에 쓰이지 않는 필드들도 생성자에서 초기화해야한다. 불필요한 초기화 코드가 늘어나는 것이다.
4. 태그 추가 시 클래스 전체를 수정해야한다.
또 다른 의미의 태그를 추가하려면 클래스 전체를 수정해야한다. 예를들어 삼각형이 추가될 경우 이에 대한 생성자가 추가되어야하고, area() 메서드도 수정이 되어야 한다.
5. 인스턴스 타입만으로는 어떤 태그인지 알 수 없다.
Figure 이라는 타입만으로 이 태그가 원인지, 사각형인지 알 수 없다.
태그 달린 클래스는 장황하고, 오류를 내기 쉽고, 비효율적이다. 태그 달린 클래스는 클래스 계층구조를 어설프게 흉내낸 아류일 뿐이다. - 책에서 태그 달린 클래스
클래스 계층 구조로 변환하기
많은 단점을 갖는 태그달린 클래스를 계층 구조로 리팩토링 해보자. 리팩토링이 끝나면 기존 단점들을 얼마나 극복했는지도 확인해보자. 가장 먼저 계층구조의 루트가 될 추상 클래스를 정의해야한다.
1. 추상 메서드 선언
태그 값에 따라 동작이 달라지는 메서드를 추상 메서드로 선언해야한다. 그리고 각각의 하위 클래스에서 이 동작을 정의하도록 한다. area 메서드가 이에 해당한다.
2. 일반 메서드 선언
태그 값에 상관 없이 동작이 일정한 메서드들을 추상 클래스의 일반 메서드로 추가한다. Figure 클래스에는 이러한 메서드가 없기 때문에 넘어간다.
3. 멤버 필드 선언
모든 하위 클래스에서 공통으로 사용하는 필드들을 전부 추상 클래스의 필드에 추가한다. Figure 클래스에는 이러한 필드가 없기 때문에 넘어간다.
이를 토대로 추상 클래스를 작성하면 아래와 같다.
abstract class Figure {
abstract double area();
}
4. 구체 클래스 설계
이제 추상 클래스를 확장한 구체 클래스를 설계한다. Figure의 태그는 원(Circle)와 사각형(Rectangle)이 있으므로 이를 클래스로 분리한다. 이로써 계층구조로의 리팩토링이 끝났다. 이제 기존 단점들을 극복했는지 확인해보자.
public class Circle extends Figure{
private final double radius;
public Circle(double radius){
this.radius = radius;
}
@Override
double area() {
return Math.PI * (radius * radius);
}
}
public class Rectangle extends Figure{
private final double length;
private final double width;
public Rectangle(double length, double width){
this.length = length;
this.width = width;
}
@Override
double area() {
return length * width;
}
}
단점을 모두 날려버린 계층구조
1. 쓸데없는 코드가 많다
> 열거 타입 선언, 태그 필드, switch 등 쓸데없는 코드가 모두 없어졌다.
2. 가독성 저하
> 다른 유형의 로직이 혼합되어 있지 않다. 클래스는 자신에 대한 로직만을 관리하고 있다.
3. 불필요한 초기화가 늘어난다
> 사용하지 않아 불필요하게 초기화 해야했던 필드들이 모두 없어졌다.
4. 태그 추가 시 클래스 전체를 수정해야한다
> 이제 태그 추가가 아닌 클래스 추가로 변경되었다. 만약 삼각형이라는 클래스가 추가되어도 기존 클래스의 수정은 필요 없게 되었다.
5. 인스턴스 타입만으로는 어떤 태그인지 알 수 없다
> 타입만으로도 원인지, 사각형인지 알 수 있다.
태그 필드가 있다면 무조건 계층구조로?
그럼 태그 필드가 있는 클래스는 모두 계층구조로 바꿔야할까? 그건 아닌것 같다. 분리될 태그들이 상위 클래스와 is-a 관계일 때만 효용성을 가진다고 생각하기 때문이다. 물론 이런 관계를 갖지 않았다면 애초에 태그 필드를 도입하지 않았을 확률이 높지만, 코드에는 정답이 없고 사람이 짜는 것이니 기존 클래스의 구조를 분석한 후 계층 구조로 리팩토링 하는 것이 바람직하다고 생각한다.
정리
태그 달린 클래스를 써야 하는 상황은 거의 없다. 만약 태그 필드가 있다면 이를 없애고 계층 구조로 리팩터링 하는 것을 고려해야 한다.
상속(inheritance)이란 기존의 클래스에 기능을 추가하거나 재정의하여 새로운 클래스를 정의하는 것을 의미합니다. 이러한 상속은 캡슐화, 추상화와 더불어 객체 지향 프로그래밍을 구성하는 중요한 특징 중 하나입니다. 출처 : TCP School
먼저 상속의 개념에 대해 한번 다시 짚어보자. 중요한 부분은 '재정의' 이다. 메서드를 재정의할 수 있다는 특성은 잠재적인 문제를 낳는다. 어디선가 자기 사용(self-use)중인 메서드를 재정의 할 수 있기 때문이다. 단순한 예를 들어보겠다.
상속을 통한 자기 사용 메서드 재정의
public class MyAdd {
public int add(int a, int b){
return a + b;
}
public int addAll(int... values){
int result = 0;
for(int value : values){
result = add(result, value);
}
return result;
}
}
위 클래스에 add, addAll 메서드가 정의되어 있다. 여기서 만약 add 메서드만 재정의하여 사용하고 싶다면 새로운 클래스에서 이를 상속받은 후 아래와 같이 재정의 할 수 있다.
간단하게 더한 값에 2를 곱하도록 재정의 하였다.
X 2
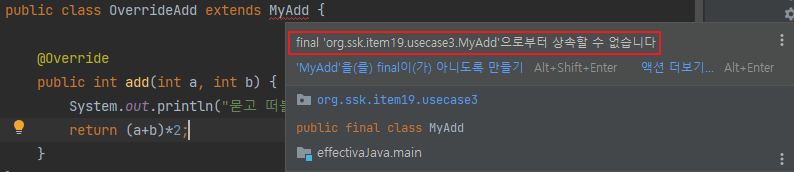
public class OverrideAdd extends MyAdd {
@Override
public int add(int a, int b) {
return (a+b)*2;
}
}
add 메서드를 재정의 한 후, add 메서드를 실행하였다. 2+2를 하고 더블로 한 8이 조회된다. 그런데 손댄 적 없는 addAll 메서드에서 2,2,3,3의 결과값이 10이 아닌 66이 조회된다. 이상하다.
class Main{
public static void main(String[] args) {
MyAdd overrideAdd = new OverrideAdd();
int result = overrideAdd.add(2,2);
System.out.println(result); // 8
...
int result2 = overrideAdd.addAll(2,2,3,3);
System.out.println(result2); // 66?!
}
}
원인은 addAll 메서드에서 자신의 add 메서드를 사용(self-use)하고 있었고, 재정의된 add 메서드에 의해 의도하지 값이 조회된 것이다. 상속을 통한 자기사용 메서드를 재정의했더니 생각지 못한 곳에서 오류가 발생한 것이다.
public class MyAdd {
public int add(int a, int b){
return a + b;
}
public int addAll(int... values){
int result = 0;
for(int value : values){
result = add(result, value); // self-use
}
return result;
}
}
내부 동작을 설명해야 하는 상속용 클래스
만약 addAll 메서드에 아래와 같은 주석을 추가했다면 어땠을까?
모든 가변인자를 더합니다. 하지만 매우매우매우 중요한 내용이 있습니다. 각 가변인자를 더할 때 add 메서드를 사용한다는 것입니다! 만약 add 메서드를 재정의한다면 이 메서드도 영향을 받게 되니 주의하세요!
이런 주석이 있었다면 addAll 메서드를 사용하는 시점에 이러한 사실을 알았을테니 add 메서드를 재정의하지 않거나, 다른 방법을 사용하여 변경 로직을 적용했을 것이다. 즉, 자기 사용(Self-use)을 하는 메서드에 대해서는 문서화를 통해 이러한 내부 구현을 알림으로써, 다른 개발자가 이를 인지할 수 있도록 해야한다.
문서화 시 포함되어야 할 내용들
1. 호출되는 재정의 가능한 자기사용 메서드 이름 2. 호출되는 순서 3. 호출 결과에 따른 영향도 4. 재정의 시 발생할 수 있는 모든 상황
문서화 시 포함되어야 할 내용들은 위와 같다. 항목을 보면 알 수 있듯이 결국 '내부 구현'을 설명해야 한다. 내부 구현에 대한 내용은 @implSpec 어노테이션 사용하여 기재한다. 자바독에서 이 어노테이션을 인식하여 자동으로 내부 구현을 설명하는 Implementation Requirements 항목에 기재한 내용을 포함시켜 문서를 생성해줄것이다.
문서화 하기(feat. javadoc)
1. 주석 추가하기
MyAdd 클래스에 다음과 같이 주석을 추가한다. addAll의 경우 @ImplSpec을 통해 내부 구현을 기재하였다.
public class MyAdd {
/**
* 두 인자를 더합니다.
* @param a 첫번째 인자
* @param b 두번째 인자
* @return 두 인자의 합
*/
public int add(int a, int b){
return a + b;
}
/**
* 모든 가변인자를 더합니다.
* @param values int 형 가변인자
* @return 모든 가변인자의 합
* @implSpec 각 가변인자를 더할 때 add 메서드를 사용합니다. 만약 add 메서드를 재정의한다면 이 메서드도 영향을 받게 됩니다.
*/
public int addAll(int... values){
int result = 0;
for(int value : values){
result = add(result, value);
}
return result;
}
}
2. javadoc 문서 만들기 (intellij 기준)
[도구 > JavaDoc 생성] 을 선택하여 javadoc 문서를 생성한다. JavaDoc 범위는 현재 파일로 하고, 명령줄 인수에 필요한 명령어들을 입력한 후 '생성' 버튼을 누른다.
javaDoc 생성
※ unknown tag: implSpec 오류
@implSpec 어노테이션은 기본적으로 활성화되어 있지 않다. 만약 unknown tag: implSpec 오류가 난다면 명령줄 인수에 이를 활성화하도록 아래 명령어를 추가해주자.
-tag "implSpec:a:Implementation Requirements:"
※ 인코딩 관련 오류
만약 인코딩 관련 오류가 난다면 아래 명령어를 추가해주자.
-encoding UTF-8 -docencoding UTF-8 -charset UTF-8
3. 문서 확인하기
생성된 문서를 확인하자. @implSpec 에 기재한 내용이 Implementation Requirements 항목에 포함되어 있따면 내부 구현이 담긴 문서 생성 작업에 성공한 것이다. 만약 이 클래스를 사용하는 개발자가 이 문서를 한번이라도 본다면, add 메서드를 재정의 했을 때 발생할 수 있는 문제 상황에 대해 인지할 수 있을 것이다.
javaDoc으로 생성된 문서
AbstractCollection 클래스에서 사용하고 있는 @implSpec 예
@implSpec를 어떻게 사용하고 있는지 AbstractCollection 클래스의 remove 메서드를 통해 확인해봤다.
/**
* @implSpec
* This implementation iterates over the collection looking for the
* specified element. If it finds the element, it removes the element
* from the collection using the iterator's remove method.
* {@code UnsupportedOperationException} if the iterator returned by this
* collection's iterator method does not implement the {@code remove}
* method and this collection contains the specified object.
**/
public boolean remove(Object o)
번역 이 메서드는 컬렉션을 순회하며 주어진 원소를 찾도록 구현되었다. 주어진 원소를 찾으면 반복자의 remove 메서드를 사용해 컬렉션에서 제거한다. 주어진 원소를 찾으면 remove 메서드를 사용해 컬렉션에서 제거하지만, 이 컬렉션의 iterator 메서드가 반환한 반복자가 remove 메서드를 구현하지 않았다면 UnsupportedOperationException을 던진다.
AbstractCollection 클래스에서도 내부 구현을 @implSpec 을 통해 기재하고 있다. 설명에 따르면 iterator 메서드를 재정의하면 이 remove 메서드의 동작에 영향을 줌을 알 수 있다.
하지만 단순 내부 메커니즘을 문서화 시키는 것만이 상속을 위한 설계의 전부는 아니다. 클래스의 내부 동작 과정 중간에 끼어들 수 있는 훅을 잘 선별하여 재정의하도록 할 수 있도록 하는 것도 중요하다.
AbstractList의 removeRange
/**
* Removes from this list all of the elements whose index is between
* {@code fromIndex}, inclusive, and {@code toIndex}, exclusive.
* Shifts any succeeding elements to the left (reduces their index).
* This call shortens the list by {@code (toIndex - fromIndex)} elements.
* (If {@code toIndex==fromIndex}, this operation has no effect.)
*
* <p>This method is called by the {@code clear} operation on this list
* and its subLists. Overriding this method to take advantage of
* the internals of the list implementation can <i>substantially</i>
* improve the performance of the {@code clear} operation on this list
* and its subLists.
*
* @implSpec
* This implementation gets a list iterator positioned before
* {@code fromIndex}, and repeatedly calls {@code ListIterator.next}
* followed by {@code ListIterator.remove} until the entire range has
* been removed. <b>Note: if {@code ListIterator.remove} requires linear
* time, this implementation requires quadratic time.</b>
*
* @param fromIndex index of first element to be removed
* @param toIndex index after last element to be removed
*/
protected void removeRange(int fromIndex, int toIndex){
...
}
번역 fromIndex 부터 toIndex까지의 모든 원소를 리스트에서 제거한다. ... 중략 이 리스트 혹은 이 리스트의 부분리스트에 정의된 clear 연산이 이 메서드를 호출한다. 리스트 구현의 내부 구조를 활용하도록 이 메서드를 재정의하면 이 리스트와 부분리스트의 clear 성능을 크게 개선할 수 있다. @implSpec 이 메서드는 fromIndex에서 시작하는 리스트 반복자를 얻어 모든 원소를 제거할 때까지 ListIterator.next와 ListIterator.remove를 반복 호출하도록 구현되었다. 주의 : ListIterator.remove 가 선형 시간이 걸리면 이 구현의 성능은 제곱에 비례한다.
clear 메서드의 훅(hook)으로써의 역할을 하는 removeRange 메서드이다. 서브 클래스에서 접근할 수 있도록 protected 접근제어자로 설계되었다.
clear의 성능을 크게 개선할 수 있다고 말하는 이유는 내부 구현을 담은 @ImplSpec 을 보면 알 수 있다. 리스트 반복자를 얻어 원소를 제거할 때까지 next()와 remove()를 반복 호출하는 것이 기본 내부 구현 로직이라고 언급하고 있다. 만약 이 로직을 ArrayList, LinkedList 등 구현체의 구조에 맞게 적절히 재정의한다면 처리 시간을 단축시킬 수 있고, 이를 hook으로 사용하는 모든 메서드, 즉 clear 메서드의 성능을 개선할 수 있다.
List 구현체의 사용자는 removeRange 메서드에는 관심이 없음에도 불구하고 이에 대한 메서드와 내부 구현을 제공한 이유는 하위 클래스의 clear 메서드를 고성능으로 만들기 쉽게 하기 위함인 것이다. 즉, 서브 클래스의 구현 클래스에서 성능 개선이 가능한 부분이 있다면 이를 재정의하여 hook으로 활용할 수 있도록 protected 접근제어자를 가진 메서드로 설계해야 한다.
protected 메서드 설계의 기준
마법은 없다. 상속용 클래스를 시험하는 방법은 직접 하위 클래스를 만들어보는 것이 '유일'하다.
하지만 protected 메서드 설계에 대한 정해진 기준은 따로 없다고 한다. 책에서는 심사숙고해서 잘 예측해본 다음, 실제 하위 클래스를 만들어 시험해보는 것이 최선이라고 말하고 있다.
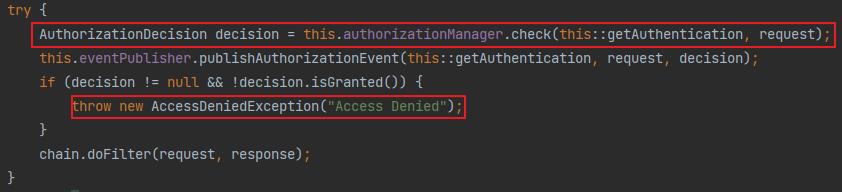
재정의 가능 메서드는 생성자에서 호출하면 안된다.
상속용 클래스의 생성자는 직접적으로든 간접적으로든 재정의 가능 메서드를 호출해서는 안된다. 아래와 같이 생성자에서 재정의 가능 메서드를 호출한다면, 이를 재정의했을 때 오작동을 일으킬 수 있다.
public class Super {
// 생성자가 재정의 가능 메서드를 호출하는 잘못된 예
public Super(){
overrideMe();
}
public void overrideMe(){
}
}
public class Sub extends Super {
private final Instant instant;
Sub(){
instant = Instant.now();
}
@Override
public void overrideMe(){
System.out.println(instant);
}
public static void main(String[] args) {
Sub sub = new Sub();
sub.overrideMe();
}
}
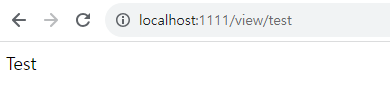
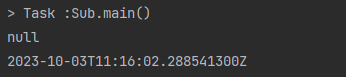
sub.overrideMe() 메서드를 호출하면 instant를 두 번 출력하리라 기대하겠지만, 첫 번째는 null을 출력한다. 상위 클래스의 생성자는 하위 클래스의 생성자가 인스턴스 필드를 초기화하기 전에 overrideMe()를 호출하기 때문이다.
실행 결과
만약 생성자에 메서드를 넣어야한다면 해당 메서드를 재정의하지 못하도록 private 접근 제어자를 사용하거나 final, static 타입으로 생성자를 설계하면 된다.
상속용 클래스는 족쇄가 되면 안된다.
널리 쓰일 클래스를 상속용으로 설계한다면 문서화한 내용과, protected 메서드, 필드를 구현하면서 선택할 결정에 영원히 책임져야 한다. 그 클래스의 성능과 기능에 족쇄를 채울 수 있기 때문이다.
처음 보여준 MyAdd 클래스의 경우 add 메서드를 재정의하면 addAll 메서드에 문제가 발생할 수 있기 때문에 함부로 수정할 수 없다. 기능에 대한 족쇄가 채워진 것이다.
상속용 클래스 말고 일반 클래스는?
그럼 일반적은 구체 클래스는 어떨까? 상속용으로 설계된 클래스가 아니니 문서화도 되어있지 않고, 다른 클래스에서 상속도 가능하다. 이 클래스에 변경 사항이 생기게 되면 이를 상속받는 하위 클래스에서 문제가 발생하거나, 하위 클래스에서 재정의하여 사용할 경우 자기 호출로 인한 문제도 발생할 수 있다.
이 문제를 해결하는 가장 좋은 방법은 상속용으로 설계하지 않은 클래스는 상속을 금지하는 것이다.
상속을 금지하는 방법
1. 클래스를 final 로 선언하기
클래스를 final로 선언할 경우 해당 클래스를 다른 클래스에서 상속할 수 없다. 만약 MyAdd 클래스를 final로 선언한다면 다른 클래스에서 상속 시 컴파일 에러가 발생하게 된다.
상속이 불가능한 MyAdd #1
2. 모든 생성자를 private로 선언하고 정적 팩터리 메서드로 만들기.
상속 시 기본적으로 부모 클래스의 기본 생성자를 호출하게 된다. 기본 생성자를 호출하지 못하도록 private로 막고, 정적 펙터리 메서드를 통해 인스턴스를 제공하는 방법이다.
public class MyAdd {
private MyAdd(){
}
public static MyAdd newInstance(){
return new MyAdd();
}
상속이 불가능한 MyAdd #2
정리
상속용 클래스를 설계하기란 결코 만만치 않다. 클래스 내부에서 사용되는 자기사용 패턴을 모두 문서로 남겨야 하고, 내부 구현에서는 이를 반드시 지켜야한다. removeRange처럼 다른 이가 효율 좋은 하위 클래스를 만들 수 있도록 일부 메서드를 protected로 제공해야 할 수도 있다. 하지만 이에 대한 기준은 없으며 설계자의 많은 고민과 테스트가 필요하다.
그러니 클래스를 확장해야 할 명확한 이유가 떠오르지 않으면 상속을 금지시키도록 설계하는 것이 정신건강에 좋다.
상속은 코드 중복을 줄이고, 기능을 확장하는 강력한 수단이지만, 잘못 사용하면 오류를 내기 쉽기 때문에 주의를 요한다.
HashSet이 처음 생성된 이후 원소가 몇개 더해졌는지(HashSet의 크기와는 다른 개념이다.) 를 확인하는 기능을 상속을 통해 추가해보았다.
잘못 사용된 상속
public class InstrumentedHashSet<E> extends HashSet<E> {
private int addCount = 0;
public InstrumentedHashSet(){
}
@Override
public boolean add(E e){
addCount++;
return super.add(e);
}
@Override
public boolean addAll(Collection<? extends E> c) {
addCount += c.size();
return super.addAll(c);
}
public int getAddCount(){
return addCount;
}
}
class Main{
public static void main(String[] args) {
InstrumentedHashSet<String> s = new InstrumentedHashSet<>();
s.addAll(Set.of("가","나","다"));
System.out.println(s.getAddCount());
}
}
HashSet을 상속받는 InstrumentedHashSet 클래스를 생성한 후 추가된 원소의 수를 나타내는 addCount 멤버필드를 생성하고, HashSet 클래스에 원소를 추가하는 메서드를 재정의하여 addCount를 증가시키도록 구현하였다.
겉으로 봐선 문제가 없어보이지만 실제로 main 메서드를 실행하면 getAddCount()은 예상했던 3이 아닌 6을 리턴한다.
6을 리턴하는 이유
HashSet에서 사용하는 addAll 메서드는 내부적으로 add 메서드를 호출하기 때문이다. 이 add 메서드는 addCount를 증가시키도록 재정의되었기 때문에 3이 아닌 6이 증가하는 것이다.
public boolean addAll(Collection<? extends E> c) {
boolean modified = false;
for (E e : c)
if (add(e))
modified = true;
return modified;
}
상속을 유지하고 문제를 해결하는 방법
하나, addAll 메서드를 재정의하지 않는다.
addAll 메서드를 재정의하지 않으면 HashSet에 존재하는 addAll 메서드를 사용하게 된다. 이때에는 addCount 값을 증가시키지 않고, 재정의된 add 메서드를 호출할 때만 증가시키게되므로 당장은 제대로 동작하게 된다.
하지만 이는 HashSet의 addAll이 add 메서드를 이용해 구현했음을 가정한 해법이다. addAll의 내부 구현에 종속된 것이다. 이런 상황에서 HashSet의 addAll 메서드 내부 구현이 add 메서드를 호출하게 아닌 다른 방식으로 변경된다면 어떨까? 재정의한 add 메서드는 호출되지 않아 버그가 발생할 것이다.
이처럼 상위 클래스의 내부 구현에 의존하는 메서드는 항상 잠재적인 위험요소가 된다.
public class InstrumentedHashSet<E> extends HashSet<E> {
private int addCount = 0;
public InstrumentedHashSet(){
}
@Override
public boolean add(E e){
addCount++;
return super.add(e);
}
public int getAddCount(){
return addCount;
}
}
class Main{
public static void main(String[] args) {
InstrumentedHashSet<String> s = new InstrumentedHashSet<>();
s.addAll(Set.of("가","나","다"));
System.out.println(s.getAddCount());
}
}
둘, addAll 메서드를 다른 식으로 재정의한다.
주어진 컬렉션을 순회하며 원소 하나당 add 메서드를 한번만 호출하는 것이다. 이 방식은 상위 클래스의 addAll 메서드를 호출하지 않으니 그 메서드의 내부 구현이 어떻게 동작하는지 신경쓸 필요가 없다.
하지만 상위 클래스의 메서드 동작을 다시 구현하는 것은 단순 호출하는 것보다 많은 시간과 노력이 필요하다. 자칫 성능을 떨어뜨릴 수도 있다.
public class InstrumentedHashSet<E> extends HashSet<E> {
private int addCount = 0;
public InstrumentedHashSet(){
}
@Override
public boolean add(E e){
addCount++;
return super.add(e);
}
public boolean addValues(Collection<? extends E> c) {
for(E e : c){
add(e);
}
return true;
}
public int getAddCount(){
return addCount;
}
}
class Main{
public static void main(String[] args) {
InstrumentedHashSet<String> s = new InstrumentedHashSet<>();
s.addValues(List.of("가","나","다"));
System.out.println(s.getAddCount());
}
}
캡슐화를 깨뜨리는 상속
두번째 방법을 사용하면 문제가 해결되긴 하지만, 객체지향적인 문제가 발생하는데 바로 캡슐화가 무너지게 되는 것이다.
캡슐화 객체의 속성과 행위를 하나로 묶고, 실제 구현 내용 일부를 내부에 감추어 은닉한다.
첫번째 방법의 경우 부모 클래스의 addAll 메서드를 호출했다. 이는 HashSet의 addAll 메서드가 내부적으로 add 메서드를 호출한다는 사실에 근거하였다는 점에서 캡슐화를 무너뜨린다.
두번째 방법은 어떨까? addAll 의 메서드를 호출하지도 않고 HashSet의 구현부를 꼭 알아야하는 부분도 당장은 없어보인다. 하지만 InstrumentedHashSet에 메서드를 추가할 때 HashSet의 메서드 시그니처를 알고 피해야한다는 점에서 캡슐화를 무너뜨린다.
이를 반대로 생각하면 기존 자식 클래스에서 사용하는 메서드 시그니처와 똑같은 메서드가 부모 클래스에 새로 추가될 때 문제가 발생할 수 있다.
아래 코드는 들어오는 정수 값에 대해서는 반드시 0 이상의 양수만 받을 수 있도록 하는 HashSet을 관리하기 위해 integerValidation 이라는 private 메서드를 추가한 상황이다.
테스트를 해보면 -1 과 같은 값이 들어갈 경우 예외가 발생하게 된다.
public class InstrumentedHashSet<E> extends HashSet<E> {
private int addCount = 0;
public InstrumentedHashSet(){
}
@Override
public boolean add(E e){
integerValidation(e);
addCount++;
return super.add(e);
}
@Override
public boolean addAll(Collection<? extends E> c) {
for(E e : c){
add(e);
}
return true;
}
public int getAddCount(){
return addCount;
}
private void integerValidation(E e){
if(Integer.class.isInstance(e)){
Integer a = (Integer)e;
if(a.intValue() < 0){
throw new IllegalArgumentException("Integer 타입은 0 이상 값만 추가할 수 있습니다.");
}
}
}
}
class Main{
public static void main(String[] args) {
InstrumentedHashSet<Integer> s = new InstrumentedHashSet<>();
s.addAll(List.of(Integer.valueOf(0),Integer.valueOf(1),Integer.valueOf(-1))); // 예외발생
System.out.println(s.getAddCount());
}
}
그런데 몇년 후 HashSet에 똑같은 메서드 시그니처를 갖고 반환만 다른 integerValidation이 추가된다면, 부모 클래스와 자식 클래스의 메서드가 충돌하게 되어 컴파일 에러가 발생하게 된다.
결국 캡슐화가 무너지기 시작하면 결합도가 강해지게 되고, 강해진 결합도는 어떤 클래스의 변경이 일어났을 때 결합된 클래스에도 영향을 미치게 된다.
상속말고 컴포지션
이러한 문제를 피해가는 방법이 바로 컴포지션이다.
컴포지션 다른객체의 인스턴스를 자신의 인스턴스 변수로 포함해서 메서드를 호출하는 기법.
위 상속을 컴포지션 방식으로 변경하면 아래와 같다.
기존 인스턴스를 확장하는게 아닌 독립적인 InstrumentedHashSet 클래스를 만들고, private 필드로 기존 클래스의 인스턴스를 멤버필드로 추가하였다. 이 방식은 HashSet의 내부 구현을 새롭게 재정의할 필요가 없고, Set 타입 인스턴스를 외부로부터 주입받는다는 점에서 약한 결합도를 갖게 된다.
또한 Set 인스턴스의 캡슐화도 무너뜨리지 않는다. 앞서 HashSet에 같은 시그니처를 갖는 메서드가 추가되도 이 클래스에는 아무런 영향을 끼치지 않는다.
public class InstrumentedHashSet<E> {
private Set<E> set;
private int addCount = 0;
public InstrumentedHashSet(Set<E> set){
this.set = set;
}
public boolean add(E e){
addCount++;
set.add(e);
return true;
}
public boolean addAll(Collection<? extends E> c) {
addCount += c.size();
set.addAll(c);
return true;
}
public int getAddCount(){
return addCount;
}
}
class Main{
public static void main(String[] args) {
Set set = new HashSet<String>();
InstrumentedHashSet<String> s = new InstrumentedHashSet<>(set);
s.addAll(Set.of("가","나","다"));
System.out.println(s.getAddCount());
}
}
그럼 상속은 언제써야해?
상위 클래스와 하위 클래스와 관계가 정말 is-a 관계일 때만 사용해야한다. 예를들어 Dog과 Animal의 경우 Dog is Animal 이라는 관계가 성립한다. 하지만 이를 확신할 수 없다면 컴포지션을 사용하자.
이를 위반한 Properties와 Hashtable
자바 라이브러리에서 이 원칙을 위반한 예시로 Properties가 있다. 이 클래스는 String 타입의 key, value를 관리하는 클래스로 Hashtable을 상속받고 있다.
Properties에 값을 추가하려면 String 값만 받는 setProperty 메서드를 사용하면 된다.
이 결과 Properties의 store 메서드와 같은 공개 API를 더이상 사용할 수 없다. 아래와 같이 object 타입의 값을 String 으로 변환하는 부분에서 Cast 예외가 발생하기 때문이다.
for (Map.Entry<Object, Object> e : entrySet()) {
String key = (String)e.getKey();
String val = (String)e.getValue();
key = saveConvert(key, true, escUnicode);
/* No need to escape embedded and trailing spaces for value, hence
* pass false to flag.
정리
상속은 강력하지만 캡슐화를 해친다는 문제가 있다. 상속은 상위 클래스와 하위 클래스가 is-a 관계일때만 사용해야 하지만 이를 확신할 수 없다면 컴포지션을 사용하자.
조슈아 블로크의 'Effective Java' 책을 읽고 제멋대로 정리한 내용입니다. :)
1. 개요
잘 설계된 컴포넌트의 판단 기준 중 하나는 클래스 내부 필드와 구현 정보를 외부로부터 얼마나 잘 숨겼는지이다. 구현 정보를 숨기면 외부 컴포넌트에서 이를 사용할때 내부 동작 방식에는 전혀 신경쓰지 않게 된다. 이를 소프트웨어 설계 근간이 되는 원리인 정보은닉 혹은 캡슐화라고 한다.
2. 정보은닉의 장점
2.1. 시스템 개발 속도를 높인다.
다른 컴포넌트의 동작 방식에 신경쓰지 않는다는 건, 컴포넌트를 개발하는 시점에서 다른 컴포넌트의 구현에 대해 신경쓰지 않아도 된다는 것이다. 작업자들이 컴포넌트를 병렬적으로 개발할 수 있다.
성능 최적화는 곧 코드 수정이다. 앞서 말한것처럼 결합도가 낮으므로 어떤 컴포넌트를 최적화하기 위해 코드를 수정한다 한들 다른 컴포넌트에 영향을 미치지 않는다. 온진히 성능 최적화 작업에 집중할 수 있다.
2.4. 소프트웨어 재사용성을 높인다.
외부에 거의 의존하지 않고 독자적으로 동작할 수 있는 컴포넌트라면 다른 어플리케이션에서도 유용하게 재사용될 가능성이 크다.
2.5. 큰 시스템을 제작하는 난이도를 낮춰준다.
단위 컴포넌트의 동작을 테스트를 통해 검증할 수 있다.
3. 정보 은닉의 기본 원칙
정보 은닉 원리를 적용한 컴포넌트 설계의 첫 단추는 당연하게도 정보 은닉의 기본 원칙을 준수하는 것이다.
정보 은닉의 기본 원칙 모든 클래스와 멤버필드의 접근성을 가능한 한 좁혀야 한다.
그럼 접근성을 좁히는 가장 간단한 방법은 뭐가 있을까?
4. 접근성을 좁히는 가장 간단한 방법! 접근제어자
접근제어자 클래스 및 멤버에 대해 접근할 수 있는 범위를 제어해주는 제어자이다. private, package-private(default), protected, public이 있다.
5. 클래스 접근제어자
클래스 접근제어자는 public, package-private (default 제어자) 만 사용된다. public 사용 시 모든 클래스에서 접근 가능하며, package-private 사용 시 해당 패키지에 존재하는 클래스에서만 접근 가능하다.
1) 동일 패키지의 public AClass 클래스
package org.ssk.item16.usecase1.pack1;
public class AClass {
}
2) 동일 패키지의 pacakge-private BClass 클래스
package org.ssk.item16.usecase1.pack1;
class BClass {
}
3) 동일 패키지의 Main 클래스
package org.ssk.item16.usecase1.pack1;
public class Main {
AClass aClass = new AClass(); // 같은 패키지에서 접근 가능한 AClass
BClass bClass = new BClass(); // 같은 패키지에서 접근 가능한 BClass
}
Main 클래스는 BClass, AClass 와 동일한 패키지에 위치하기 때문에 각 클래스로 접근이 가능하다.
4) 하위 패키지의 EClass 클래스
package org.ssk.item16.usecase1.pack1.innerPack;
public class EClass {
AClass aClass = new AClass();
BClass bClass = new BClass(); // 컴파일 에러 발생
}
하위 패키지에 위치한 EClass는 BClass와 다른 패키지에 위치하기 때문에 접근을 못하며 컴파일 에러가 발생한다.
5) 상위 패키지의 RootClass
package org.ssk.item16.usecase1;
public class RootClass {
AClass aClass = new AClass();
BClass bClass = new BClass(); // 컴파일 에러 발생
}
상위 패키지에 위치한 RootClass도 BClass와 다른 패키지에 위치하기 때문에 컴파일 에러가 발생한다.
중요한 점은 접근 제어자를 통해 정해지는 클래스의 성격이다. public으로 선언한 클래스는 어느 클래스에서나 접근 가능하다는 점에서 '공개 API' 성격을, package-private로 선언한 클래스는 해당 패키지에서만 접근이 가능하다는 점에서 '내부 구현' 성격을 띈다.
일반적으로 내부 구현은 외부에서 접근 불가하므로 클라이언트에 대한 인터페이스로 사용하지 않는다. 클라이언트에 신경 쓸 필요 없이 코드를 수정할 수 있다는 뜻이다. 반면, 공개 API는 그 API를 사용하는 모든 코드가 해당 클래스에 의존하게 된다. 이 클래스에 대한 변경(교체)은 하위 호환성 문제를 일으킬 수 있다.
(변경 가능성이 있는 클래스의 경우 인터페이스가 활용하면 호환성을 지킬 수 있다. )
때문에 public 클래스는 공개 API를 제공하고, package-private 클래스는 내부 구현으로 숨겨 사용한다. 접근 제어자만 설정했을 뿐인데 자연스럽게 정보 은닉 성격을 띄게 되었다.
1) Client
APIClass apiClass = new APIClass();
String result = apiClass.sayHi();
System.out.println(result);
2) APIClass
package org.ssk.item16.usecase4;
public class APIClass {
public String sayHi(){
return ImplementClass.hi();
}
}
ImplementClass는 해당 패키지에 있는 클래스들이라면 자유롭게 접근할 수 있다. 만약 여러 클래스가 아닌 특정 클래스에서만 접근할 수 있도록 하고 싶다면, 클래스 안에 private static class(중첩 클래스) 만들어 사용할 수도 있다.
public class PublicClass {
public void logic(){
InnerClass.innerLogic();
}
//publicClass 클래스에서만 접근 가능한 클래스
private static class InnerClass{
static void innerLogic(){
}
}
}
6. 멤버 접근 제어자
멤버 접근 제어자의 멤버는 필드, 메서드, 중첩 클래스, 중첩 인터페이스를 뜻한다. 멤버 접근 제어자는 private, package-private, protected, public 이 사용되며, 접근 범위는 다음과 같다.
3) 같은 패키지 내 다른 클래스에서private 멤버에 대해 접근해야한다면 package-private로 만들어준다.
4) 작성한 클래스 내에 package-private가 많아질 경우 컴포넌트를 분해하여 pacakge-private 클래스로 관리해야하는 것은 아닌지 고민한다.
8. 멤버의 접근성 제어에 대한 제약
멤머의 접근성을 제어할 때 하나의 제약이 있다. 상위 클래스의 메서드를 재정의할 때 접근 수준을 상위 클래스보다 좁게 설정할 수 없다는 것이다. 이는 상위 클래스의 인스턴스는 하위 클래스의 인스턴스로 대체해 사용할 수 있어야 한다는 리스코프 치환 원칙을 위배하기 때문이다.
리스코프 치환 원칙(LSP) 하위 타입은 언제나 상위 타입과 호환될 수 있어야 한다는 원칙으로 다형성을 보장하기 위한 원칙이다.
public class UpperClass {
public void hello(){
System.out.println("hello");
}
}
public class Client {
public static void main(String[] args) {
UpperClass clazz = new UpperClass();
clazz.hello(); // hello 출력
}
}
여기에 서브 클래스를 만들고, UpperClass의 hello 메서드를 재정의하였다. 일단 접근제어자를 수정하지 않고 public으로 동일하게 가져갔다.
public class SubClass extends UpperClass{
@Override
public void hello() {
System.out.println("hello my friend!");
}
}
그 후 Client에서 상위 타입 대신 하위 타입 인스턴스로 변경하였다. 리스코프 치환 원칙이 지켜진다.
public class Client {
public static void main(String[] args) {
// UpperClass clazz = new UpperClass();
SubClass clazz = new SubClass(); // 기반 타입 대신 하위 타입을 사용한다
clazz.hello(); // hello my friend! 출력
}
}
8.2. 리스코프 치환 원칙을 위배하는 케이스
재정의한 메서드의 접근 제어자를 public 에서 protected로 수정하였더니 컴파일 에러가 발생했다. UpperClass의 hello는 어디서든 호출이 가능한데 바뀐 SubClass의 hello는 자식클래스 혹은 같은 클래스에서만 호출이 가능하다. 즉, SubClass가 UpperClass를 대체할 수 없기 때문에 리스코프 교환 원칙 위배하게 되는 것이다.
public class SubClass extends UpperClass{
@Override
protected void hello() {
System.out.println("hello my friend!");
}
}
컴파일 에러 발생
이에 대한 다른 예로 인터페이스와 구현 클래스가 있는데, 이때 클래스는 인터페이스가 정의한 모든 메서드를 public으로 선언해야 한다. 접근제어자로 인한 리스코프 교환 원칙을 위배하지 않아야 하기 때문이다.
9. public 클래스의 인스턴스 필드는 되도록 public이 아니어야 한다.
필드가 가변 객체를 참조하거나 final이 아닌 필드를 public으로 선언하면 해당 필드를 제한할 수 없게 된다. 어디서든 해당 필드에 접근하여 수정할 수 있으며 이는 상태 값을 공유하는 것이므로 Thread Safe 하지 않다.
하지만 클래스 내에서 바뀌지 않는 꼭 필요한 상수라면 public static final 필드로 공개해도 좋다. 이런 필드는 불변성을 가져야 하므로 기본 타입 값이나 불변 객체를 참조해야 한다.
하지만 길이가 0이 아닌 배열은 final이어도 수정이 가능하기 때문에 public static final 배열 필드를 두거나 이 필드를 반환하는 접근자 메서드를 제공해서는 안된다.
아래의 경우 길이 0인 emptyArr는 값을 추가하려 할 때 arrayIndexOutOfBoundsException이 발생하여 런타임 시 수정이 불가능하지만, arr의 경우 예외가 발생하지 않고 수정됨을 확인할 수 있다.
public class MyClass {
public static final Thing[] arr = {new Thing(), new Thing()};
public static final Thing[] emptyArr = {};
}
public class Main {
public static void main(String[] args) {
MyClass.arr[0] = new Thing(); // 런타임 에러가 발생하지 않음.
MyClass.emptyArr[0] = new Thing(); // ArrayIndexOutOfBoundsException 발생
}
}
이에 대한 해결책은 두 가지다. 첫번째 방법은 public 배열을 private로 만들고 public 불변 리스트를 추가하는
것이고, 두번째 방법은 clone을 통한 방어적 복사를 사용하는 것이다.
전자의 경우 수정은 불가능하지만 PRIVATE_VALUES과 동일함을 보장할 수 있고, 후자의 경우 자유롭게 수정할 수 있다. 상황에 따라 선택하면 된다.
public class MyClass {
private static final Thing[] PRIVATE_VALUES = {new Thing(), new Thing()};
public static final List<Thing> VALUES = List.of(PRIVATE_VALUES); // 불변 객체의 List로 변환 후 반환
public static Thing[] values(){
return PRIVATE_VALUES.clone(); // clone을 통해 방어적 복사
}
}
10. 정리
정보은닉 기반의 설계를 위해 공개 API는 꼭 필요한 것만 골라 최소한으로 설계해야 한다.
그 외에는 클래스, 인터페이스, 멤버가 의도치 않게 공개 API가 되지 않도로 한다.
public 클래스는 상수용 public static final 필드 외에 어떠한 public 필드도 가져서는 안된다.
스프링 시큐리티에서 제공하는 OAuth2Login을 통해 사용자 정보를 받아오고, 자체적으로 JWT 토큰을 발급하고 있다. JwtAuthorizationFilter에서 JWT 토큰에 대한 인증 처리 로직을 구현하였고, 구글링을 통해 필터의 위치를 UsernamePasswordAuthenticationFilter 이후로 설정하였다.
요청마다 JWT Filter가 호출되긴 했지만 막상 Security Filter 로그를 통해 Security Filter Chain 리스트를 보니 UsernamePasswordAuthenticationFilter 가 보이지 않았다. 😲
이 필터가 없는 이유와 없는 필터에 커스텀 필터가 추가되는 것이 이해 되지 않았다. 이 이유를 알아보자.
2. UsernamePasswordAuthenticationFilter 가 없는 이유
이유는 매우 간단했다. UsernamePasswordAuthenticationFilter는 클라이언트에서 요청한 username과 password를 통해 인증을 처리하는 필터이다. formLogin 시 UsernamePasswordAuthenticationFilter 가, OAuth2Login시 OAuth2AuthorizationRequestRedirectFilter와 OAuth2LoginAuthenticationFilter 가 추가된다.
OAuth2Login 을 사용하므로 UsernamePasswordAuthenticationFilter 가 없는건 매우 당연했다.
OAuth2AuthorizationRequestRedirectFilter는 OAuth2 서비스 제공 서버의 로그인 페이지를 호출하는 필터이다. 기본 제공하지 않는 Naver나 Kakao의 로그인 페이지는 yml 설정한 정보를 조합하여 uri를 만든 후 호출한다.
OAuth2LoginAuthenticationFilter는 AbstractAuthenticationProcessingFilter의 서브클래스로 RedirectURI를 통해 받은 AuthorizationCode로 토큰 인증 API를 호출하여 accessToken 및 refreshToken을 받아오고, 이를 통해 유저 정보 조회 API를 호출하여 유저 정보도 받아온다. 관련 로직은 아래와 같다.
3) OAuth2LoginAuthenticationProvider 클래스의 userService.loadUser() 메서드 호출하여 유저 정보 취득 (OAuth2UserService 를 재정의하여 사용하기도 함.)
유저 정보 취득 부분
4. Filter Chain에 없는 AbstractAuthenticationProcessingFilter
디버깅을 하면서 추적해 나가다보니 AbstractAuthenticationProcessingFilter 클래스의 특정 메서드가 호출되는 부분이 있었다. 이 필터에서는 요청 URI를 추출하여 OAuth2 서비스에 대한 redirectURI로 온 요청일 경우 attemptAuthentication 메서드를 통해 OAuth2LoginAuthenticationFilter의 인증 처리를 하고 있었다. 그런데 이 필터는 Security Filter Chain 리스트에 없다. 이 녀석의 정체는 뭘까? 🤔
AbstractAuthenticationProcessingFilter 코드 일부
스프링 공식문서를 보면 아래와 같이 해당 클래스의 서브 클래스 리스트가 나온다. 그런데 아주 눈에 익은 클래스가 보인다. 그렇다. OAuth2LoginAuthenticationFilter가 이 클래스의 서브클래스였다. 😲
AbstractAuthenticationProcessingFilter
Direct Known Subclasses: CasAuthenticationFilter, OAuth2LoginAuthenticationFilter, Saml2WebSsoAuthenticationFilter, UsernamePasswordAuthenticationFilter
필터를 신경써서 봤다면 OAuth2LoginAuthenticationFilter는 이 클래스를 상속받고 있고, 추상 메서드인 attemptAuthentication 를 구현함을 알 수 있었을것이다. 참고로 OAuth2LoginAuthenticationFilter는 Security Filter Chain 목록에 있다.
OAuth2LoginAuthenticationFilter
5. UsernamePasswordAuthenticationFilter 가 없어도 JwtAuthorizationFilter 가 추가된 이유
두번째로 궁금했던 UsernamePasswordAuthenticationFilter 가 없어도 커스텀한 필터가 추가된 이유를 알아보았다. 추가에 사용한 메서드는 addFilterAfter() 이며 Security 설정 부분에 아래와 같이 사용하였다.
결론부터 말하면 스프링 시큐리티에서 필터를 유연하게 추가할 수 있도록 내부 로직이 구성되어 있기 때문이었다. UsernamePasswordAuthenticationFilter 처럼 실제로 사용하지 않는 필터라도 말이다.
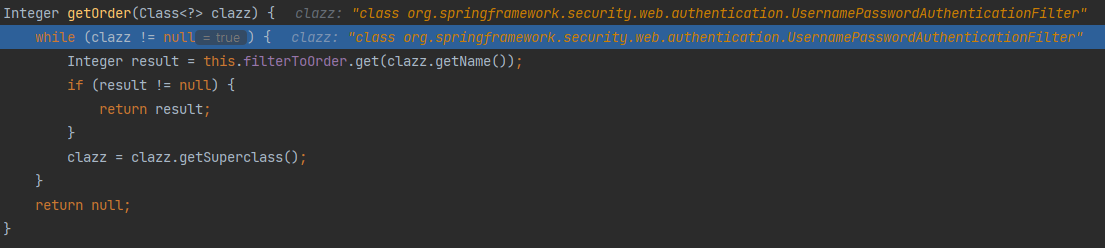
아래 코드는 addFilterAfter 메서드를 실행했을 때 FilterOrderRegistration 클래스의 getOrder 메서드를 통해 UsernamePasswordAuthenticationFilter의 위치를 Integer로 추출하는 로직이다.
필터의 순서를 조회하는 getOrder
filterToOrder은 필터 클래스 이름과 순서를 Map 타입으로 관리하는 변수이다. 이는 FilterOrderRegistration 클래스의 생성자 메서드를 통해 생성된다. 여기서 중요한 점은 이 값은 순수하게 필터의 순서를 관리하기 위해 존재한다는 것이다.
필터의 클래스명과 순서를 관리하는 filtersToOrder
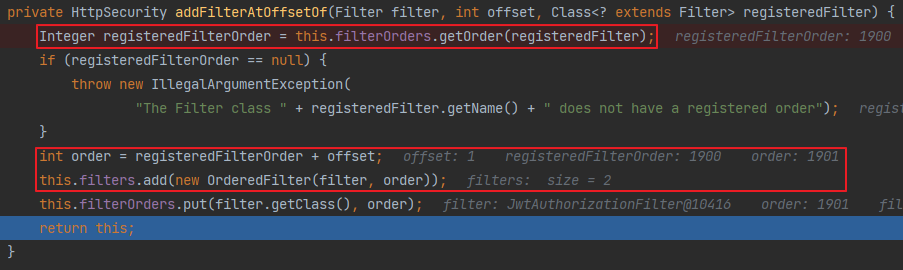
위 로직을 통해 UsernamePasswordAuthenticationFilter가 1900번째 필터임을 알았으며, 해당 값에 offset 인 1을 추가하여 새로 추가될 필터인 JwtAuthorizationFilter를 1901번 필터로 추가하였다. 즉, UsernamePasswordAuthenticationFilter의 바로 다음 순서의 필터로 JwtAuthorizationFilter를 지정한 것이다.
그 후 filters에 JwtAuthorizationFilter와 1901 정보를 갖는 OrderedFilter 타입 인스턴스를 추가하였다.
이 filters가 실제 어플리케이션에서 사용될 필터들을 관리한다.
filters에 추가되는 부분
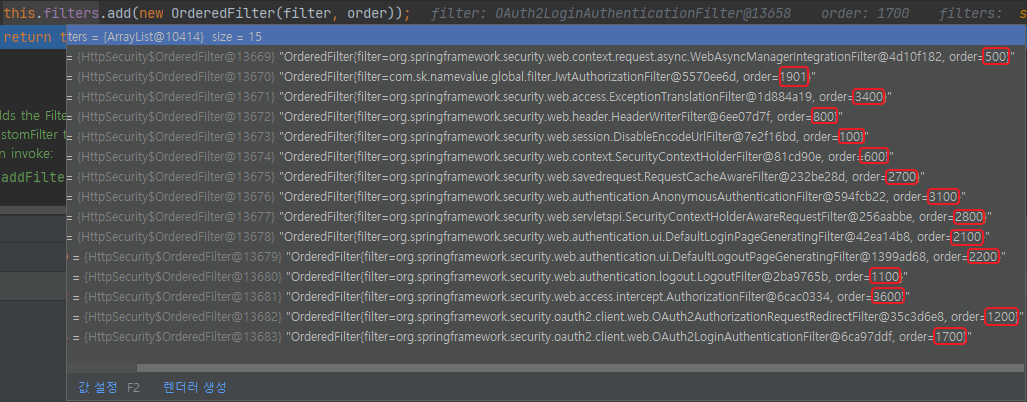
최종적으로 등록된 filters 리스트를 살펴보면 filter와 order 필드를 갖는 OrderedFilter 타입의 객체들이 있으며, order를 오름차순으로 정렬해보면 이 포스팅의 제일 첫 그림과 동일한 순서를 갖는 필터 리스트임을 확인할 수 있다. 이러한 내부 로직에 의해 실제로 사용하지 않는 필터에 대해 addFilterAfter와 같은 메서드를 사용하여 필터를 추가해도 에러가 발생하지 않았던 것이었다.
filters 리스트
6. JwtAuthrizationFilter의 위치
위를 근거로 하여 JwtAuthrizationFilter는 OAuth2LoginAuthenticationFilter 다음으로 수정하였다.
단순히 UsernamePasswordAuthenticationFilter가 왜 없지? 라는 단순한 호기심으로 시작했지만 내부 코드를 까보며 OAuth2 인증이 스프링 내부에서 어떻게 처리되는지, 필터는 어떻게 구성되는지에 대해 이해하게 되었고, 1,2년 전쯤 스프링 시큐리티의 폼 인증에 대한 내부 로직에 대해 정리한 적이 있는데, 이를 한번 더 상기하게 되었고, 모든 코드에는 근거가 있어야함을 다시한번 느끼게된 좋은 계기가 되었다.
조슈아 블로크의 'Effective Java' 책을 읽고 제멋대로 정리한 내용입니다. :)
1. Comparable이란?
1.1. 정의
객체를 비교할 수 있도록 만드는 인터페이스이며, compareTo 메서드를 재정의하여 비교의 기준을 제공한다.
public int compareTo(T o);
1.2. 객체를 비교한다?
int 타입의 1과 2를 비교한다면 단순히 관계 연산자를 통해 비교하면 된다. 하지만 아래와 같은 Student 객체를 비교할 어떻게 해야할까?
여러 값을 가진 Student 객체를 비교하기 위한 기준이 없다. number를 기준으로 할지, name을 기준으로 할지에 대한 명확한 기준 말이다. Comparable의 compareTo 메서드는 이 기준을 정의할 수 있도록, 즉, 비교의 기준을 제공할 수 있도록 하며, Arrays.sort 메서드 호출 시 이 기준을 참조하여 정렬하게 된다.
public class Student implements Comparable<Student>{
private int number;
private String name;
public Student(int number, String name){
this.number = number;
this.name = name;
}
@Override
public int compareTo(Student o) {
if(this.number > o.number){ // number에 대해 오름차순
return 1;
}
else if(this.number == o.number){
return 0;
}
else{
return -1;
}
}
@Override
public String toString() {
return "Student{" +
"number=" + number +
", name='" + name + '\'' +
'}';
}
}
1.3. 반환 값 1, 0, -1?
compareTo 메서드를 보면 1, 0, -1을 반환하고 있다. Arrays.sort 메서드 호출 시 내부적으로 클래스에 정의한 compareTo 메서드를 호출하는데, 이때 응답 값이 양수이면 두 객체의 위치를 바꾸고, 음수나 0이면 그대로 유지한다.
결국 this.number 와 o.number 사이의 부등호가 > 인지, < 인지에 따라 반환 값이 달라지므로 정렬 방식이 달라지게 되는데, 정렬방식이 어떻게 달라지는지 헷갈릴 경우 다음과 같이 생각하면 편하다.
예를들어 10, 21, 3의 number를 가진 Student가 있고, 이를 sort 할 경우 compareTo 메서드의 this.number는 첫 인스턴스의 number인 10일 것이고, o.number는 그 다음 인스턴스의 number인 21 일 것이다.
그 후 정의한 compareTo 메서드를 실행시킨다고 가정하면 10 < 21 이므로 -1이 리턴되고, 순서는 그대로 유지된다. [10, 21] 순서로 정렬되며 이는 오름차순 정렬이 된다. (실제로 이렇게 동작하는 것은 아니다)
Student student1 = new Student(10, "홍길동");
Student student2 = new Student(21, "심심이");
Student student3 = new Student(3, "심심이");
Student[] arr = new Student[]{student1, student2, student3};
Arrays.sort(arr);
for(Student student : arr){
System.out.println(student);
}
실행 결과
1.4. 뺀 값을 반환하면 안돼?
현재 조건문에 따라 1, 0, -1을 반환하는 대신 두 변수의 차를 반환하는 것이 더 깔끔해보인다. this.number가 더 크면 양수를 반환할테고, 동일하면 0을, o.number가 더 크면 음수를 반환할 것이다. 실제 정렬에는 이 두 수의 '차이'를 이용하는 게 아닌 양수, 0, 음수인지를 이용하기 때문에 큰 문제가 없어보인다. 실제로 아래와 같이 this.number - o.number로 수정해도 그 결과는 동일하다.
@Override
public int compareTo(Student o) {
return this.number - o.number; // number에 대해 오름차순
}
실행 결과
하지만 overflow가 발생하게 될 경우 문제가 된다. 만약 this.number가 int의 최대값인 2,147,483,647 이고 o.number가 -1일 경우 연산 결과는 양수(2,147,483,648)가 아닌 음수(- 2,147,483,648) 가 된다. 최댓값을 넘어서 overflow가 발생한 것이다. 속도도 월등히 빠르지도 않기에 이 방법은 권장하지 않고 있다.
2. Comparable을 구현할지 고려하자.
본론으로 와서 Comparable의 메서드인 compareTo는 단순 동치성 비교 뿐 아니라 순서까지 비교할 수 있고, 제네릭한 성질을 갖는다. Comparable을 구현한 객체들의 배열은 앞서 언급했던 Arrays.sort() 메서드를 통해 쉽게 정렬할 수 있다.
이런 강력한 정렬 기능을 제공하는데 필요한 건 단 하나, Comparable의 compareTo 메서드를 구현하는 것 뿐이다. 때문에 자바 플랫폼 라이브러리의 모든 값 클래스와 열거 타입이 Comparable을 구현하기도 했다.
알파벳, 숫자, 연대 같이 순서가 명확한 값 클래스를 작성한다면 Comparable 인터페이스를 구현하는 것이 바람직하다.
3. 관계 연산자보다 compare를 사용하자.
앞선 예제에서도 두 값을 비교할 때 >, == 와 같은 관계 연산자를 사용했다. 하지만 자바 7부터 박싱된 기본 타입 클래스(ex. Integer)들에 새로 추가된 compare 메서드 사용을 권장하고 있다. 내부적으로 삼항 연산자를 통해 비교 후 -1, 0, 1 값을 리턴한다.
@Override
public int compareTo(Student o) {
return Integer.compare(number, o.number);
}
Integer.compare
문자열을 비교할때도 마찬가지이다. Java에서 제공하는 String.CASE_INSENSITIVE_ORDER.compare 메서드를 사용하면 대소문자 구분 없이 문자열을 비교할 수 있다. 만약 number가 아닌 name에 대한 오름차순 정렬을 해야한다면 아래와 같이 코드를 수정하면 된다.
@Override
public int compareTo(Student o) {
return String.CASE_INSENSITIVE_ORDER.compare(this.name, o.name);
}
4. 정리
순서를 고려해야하는 값 클래스를 작성한다면 꼭 Comparable 인터페이스를 구현하여, 그 인스턴스들을 쉽게 정렬하고, 검색하고, 비교하는 기능을 제공하는 컬렉션과 어우러지도록 해야한다.
compareTo 메서드에서 필드 값을 비교할 때 <와 > 연산자를 쓰는 대신 박싱된 기본 타입 클래스가 제공하는 정적 compare 메서드를 사용하자.