HTTP 메시지는 애플리케이션 간 주고받는 데이터의 블록들로 시작줄, 헤더, 본문으로 구성된다. 이 데이터 블록 안에 어떤 데이터들이 있는지 알아보고, 요청 메시지와 응답 메시지의 데이터가 약간 다르기때문에,이 차이도 알아보도록 하자.
HTTP 메시지 형태 (출처 : https://developer.mozilla.org/ko/docs/Web/HTTP/Messages)
2. 시작줄
요청 메시지의 시작줄에는 메서드, URL, HTTP 버전이, 응답 메시지의 시작줄에는 HTTP 버전, 상태 코드, 사유 구절 정보가 포함된다.
2.1. 메서드
메서드는 서버에게 어떤 형식의 작업을 해야하는지 알려준다.
메서드
설명
GET
서버에서 데이터를 가져온다.
HEAD
서버에서 데이터에 대한 헤더만 가져온다.
POST
서버가 처리해야할 데이터를 보내거나, 새로 저장시킨다.
PUT
서버에 요청 메시지의 본문을 (덮어)저장한다.
PATCH
서버에 저장된 데이터의 일부분을 수정한다. (2010년 RFC 표준화됨)
TRACE
메시지가 프락시를 거쳐 서버에 도달하는 과정을 추적한다.
OPTIONS
어떤 메서드를 지원하는지 확인한다.
DELETE
서버에서 데이터를 제거한다.
2.2. POST와 PUT ??
사실 위는 책의 내용을 필자가 재해석하여 쓴것이다. 책에 기재된 POST와 PUT의 설명을 보고 바로 이해하기 어려웠기 때문인데, 책의 내용은 아래와 같다.
메서드
설명
POST
서버가 처리해야할 데이터를 보낸다.
PUT
서버에 요청 메시지의 본문을 저장한다.
필자의 경우 POST는 데이터를 저장할때, PUT은 덮어쓸때 사용했었다. 그런데 POST 에는 없고 PUT에는 있는 '저장'이라는 단어가 잘 이해되지 않았다. HTTP 메서드에 대해 공식문서를 찾아본 결과 '멱등성'이라는 개념을 통해 이해하게 되었고, '저장'이라는 단어에 대해 편협하게 바라보고 있었다는 걸 깨닫게 되었다.
멱등성 동일한 요청을 한 번 보내는 것과 여러 번 연속으로 보내는 것이 같은 효과를 지니고, 서버의 상태도 동일하게 유지될 때 해당 HTTP 메서드가 멱등성을 가졌다고 말한다.
모질라 개발자 페이지를 보면 HTTP 메서드 중 GET, HEAD, PUT, DELETE, OPTION, TRACE 는 멱등성 메서드, POST, PATCH는 비 멱등성 메서드라는 것을 알 수 있다.
PUT 메서드는 Word나 한글파일에서의 '저장'과 같다고 생각했다. 처음 저장할때는 디스크에 새로 저장하지만, 이후부터는 계속 덮어쓴다. 동일한 내용을 한번 저장하는 것과 여러번 저장하는 것이 같은 효과를 지님과 동시에 서버의 상태도 동일하게 유지(리소스가 1개 -> 리소스가 1개)된다는 점에서 멱등성을 보장함을 알 수 있다.
이에 반해 POST는 '다른이름으로 저장' 과 같다고 생각했다. 저장할때마다 무조건 디스크에 새로 저장하게 된다. 동일한 내용을 한번 '다른이름으로 저장'하는 것과 여러번 '다른이름으로 저장'하는 것이 같은 효과를 지니고 있지만, 리소스를 계속 생성하여 서버의 상태를 변경한다는 점에서 비멱등성이라는 것을 알 수 있다.
이를 이해하니 PUT은 '서버에 요청 메시지의 본문을 저장한다'라는 내용도 이해할 수 있었다.
2.3. PATCH는 비멱등성?
멱등성을 알아보던 중 한번의 물음표가 더 나왔다. PATCH는 특정 부분만 수정하니 당연히 멱등성 메서드일줄 알았으나 비멱등성 메서드라는 부분때문이었다. 결론은 PATCH는 로직에 따라 멱등성을 보장할 수 없기 때문에 비멱등성 메서드로 정의하고 있었다. 비멱등을 유발하는 케이스를 아래에 정리해보았다.
사용자의 나이를 한살 증가시키는 HTTP API가 있다고 가정하자. 이는 일부분을 변경하는 것이므로 PATCH 메서드를 사용할 것이며, 사용자의 나이에 1을 더하는 로직이 들어갈 것이다.
만약 A라는 사용자의 나이가 5살이었다면, 한번 요청했을 때는 6살이, 두번 요청했을 때는 7살이 될 것이다. 이는 멱등성을 보장하지 않는다고 할 수 있다.
반대로 만약 사용자의 이름을 변경하는 API가 있다고 가정하자. 마찬가지로 일부분을 변경하는 것이므로 PATCH 메서드를 사용할 것이며, 사용자의 이름을 요청 이름으로 변경하는 로직이 들어갈 것이다. 만약 A라는 사용자의 이름을 B로 변경한다면, 한번 요청하던, 두번 요청하던 이름은 B가 될 것이다. 이는 멱등성을 보장한다고 할 수 있다.
즉, 로직에 따라 멱등성을 보장할수도, 보장하지 못할수도 있으므로 비멱등성 메서드로 정의되는 것이다.
2.4. 상태코드
상태코드는 서버에서 어떤 행위가 일어났는지에 대한 것을 코드로 표현한 것이다. 백단위마다 다른 종류로 분류된다.
전체 범위
분류
100 ~ 199
정보
200 ~ 299
성공
300 ~ 399
리다이렉션
400 ~ 499
클라이언트 에러
500 ~ 599
서버에러
2.5. 사유구절
사유 구절은 상태 코드에 대한 설명을 말한다. 예를들어 200 상태 코드에 대해서는 OK이라는 사유구절이 포함된다.
2.6. HTTP 버전
HTTP 애플리케이션들이 자신이 따르는 프로토콜의 버전을 상대방에게 말해주기 위한 수단으로 사용된다.
3. 헤더
헤더는 HTTP의 요청과 응답 메시지에 더하는 추가 정보로, 이름/값 쌍의 목록으로 관리되며, 일반적으로 쿠키나 인증, 컨텐츠와 같은 메타 정보가 포함된다. 헤더는 목적에 따라 총 5가지로 분류된다.
3.1. 일반 헤더(General Header)
클라이언트와 서버 양쪽 모두가 사용하는 헤더이다. 예를들어 Date 헤더는 서버와 클라이언트를 가리지 않고 메시지가 만들어진 일시를 지칭하기 위해 사용된다.
3.2. 요청 헤더(Request Header)
요청 메시지를 위한 헤더이다. 예를 들어 "Accept : */*" 헤더는 서버에게 어떤 미디어 타입도 받을 수 있다는 것을 의미한다.
3.3. 응답 헤더(Response Header)
응답 메시지를 위한 헤더이다. 예를 들어 "Location : http://~" 헤더는 클라이언트에게 알려준 URL로 재 요청하라는 것을 의미한다.
3.4. 엔티티 헤더(Entity Header)
본문에 대한 헤더를 말한다. 예를들어 Content-Type : text/html 헤더는 클라이언트에게 본문에 들어간 데이터가 HTML 문서라는 것을 의미한다.
3.5. 확장 헤더(Extension Header)
개발자에 의해 커스텀되어 만들어졌지만 HTTP 명세에는 추가되지 않는 비표준 헤더이다.
4. 본문
HTTP 메시지에 덱스트, 이미지, 비디오, HTML 문서 등 여러 종류의 디지털 데이터를 포함시켜 요청하기 위해 사용된다.
'자바 엔터프라이즈 개발을 편하게' 해주는 '오픈소스' '경량급' '애플리케이션 프레임워크'
1.1. 애플리케이션 프레임워크
일반적으로 프레임워크는 특정 업무 분야나 한가지 기술에 특화된 목표를 가지고 만들어진다. 스프링은 특정 계층이나, 기술, 업무 분야에 국한되지 않고 애플리케이션 전 영역을 포괄하는 범용적인 프레임워크이다.
1.2. 경량급
스프링 자체가 가볍다는 뜻이 아니다. 개발환경, 빌드, 테스트 과정, 코드 등 매우 무겁고 복잡했던 EJB에 비해 불필요하게 무겁지 않다는 뜻이다.
1.3. 자바 엔터프라이즈 개발을 편하게
IoC/DI, 서비스 추상화, AOP 등을 통해 로우 레벨의 트랜잭션이나 상태관리, 스레딩, 리소스 풀링과 같은 복잡한 로우레벨의 API를 이해하지 못하더라도 아무 문제 없이 애플리케이션 개발을 할 수 있다.
1.4. 오픈소스
스프링은 오픈소스 프로젝트 방식으로 개발되고 있으며, 2009년 세계적인 IT 기업에 합병되었다. 즉, 전문적이고 성공적인 오픈소스 프레임워크이다.
2. 복잡한 엔터프라이즈 시스템?
'자바 엔터프라이즈 개발을 편하게' 라는 부분에서 알 수 있듯이 스프링을 사용하기 전 자바 엔터프라이즈 개발은 불편하고 복잡했다고 한다. 그 이유는 무엇일까?
2.1. 기술적인 복잡함
엔터프라이즈 시스템은 기업과 조직의 업무를 처리해주는 시스템이다. 기업 내 많은 사용자들의 요청을 처리해야 하기에 시스템의 안정성을 고려해야한다. 또한 조직의 업무 처리는 곧, 조직의 핵심 정보 처리이다. 핵심 정보에 대한 보안성도 고려해야 한다. 이 뿐 아니라 업무 자체에도 여러 기술이 사용된다.
정리하면 안정성과 보안성, 업무적인 기술 등, 다양한 기술적인 복잡도를 갖게 된다.
2.2. 비지니스 로직의 복잡함
기업의 핵심 업무는 복잡하고, 한정되어 있지 않다. 처리하는 업무가 많아짐에 따라 비지니스 로직도 늘어나고, 복잡해진다.
2.3. 기술과 비지니스 로직의 복잡함
엔터프라이즈 시스템은 기술적인 복잡함과 비지니스 로직의 복잡함이 얽혀있다. 코드를 담는 하나의 파일 안에 여러 기술이 담긴 코드와 비지니스 로직 코드가 얽혀있다고 생각하면 된다.
3. 스프링의 목적
스프링의 목적은 엔터프라이즈 애플리케이션 개발을 편하게 하는 것이다. 스프링은 이를 위해 기술 부분과 비지니스 로직 부분을 분리하고 사용할 수 있도록 도와준다. OOP와 DI를 통해서 말이다.
사용하는 기술들은 추상화 되어있다. 기술에 대한 로우 레벨의 코드를 이해하고 있지 않아도 사용할 수 있으며, 기술이 변경되어도 비지니스 로직을 수정할 필요가 없게된다.
AOP를 사용하면 트랜잭션과 같은 기술을 담당하는 부분을 비지니스 로직과 아예 분리할 수도 있다.
이처럼 스프링은 엔터프라이즈 애플리케이션 개발을 편하게 하도록 돕는다.
4. 결론
스프링은 객체지향이라는 도구를 극대화해서 애플리케이션 개발을 편하게 할 수 있도록 도울 뿐이다. 객체 지향적인 프로그래밍을 얼마나 잘 하냐에 따라 스프링의 활용도가 달라지게 된다.
때문에 스프링 공부와 함께 개발자 본인의 객체지향 설계와 개발 능력을 키워야 비로소 복잡한 엔터프라이즈 시스템을 잘 개발할 수 있다는 점을 잊지 말자.
브라우저가 웹 서버에 접속하여 받아온 정적 컨텐츠 (html, 이미지, js 등)를 메모리 또는 디스크에 저장해 놓는 것을 말한다. 이후 HTTP 요청을 할 경우 해당 리소스가 캐시에 있는지 확인하고 이를 재사용함으로써 응답시간과 네트워크 대역폭을 줄일 수 있다.
웹 캐시의 장점
1. 불필요한 네트워크 통신을 줄인다.
클라이언트가 서버에게 문서를 요청할 때, 서버는 해당 문서를 클라이언트에게 전송하게 된다. 재차 똑같은 문서를 요청할 경우 똑같이 전송하게 된다.
캐시를 이용하면, 첫번째 응답은 브라우저 캐시에 보관되고, 클라이언트가 똑같은 문서를 요청할 경우 캐시된 사본이 이에대한 응답으로 사용될 수 있기 때문에, 중복해서 트래픽을 주고받는 네트워크 통신을 줄일 수 있다.
2. 네트워크 병목을 줄여준다.
많은 네트워크가 원격 서버보다 로컬 네트워크에 더 넓은 대역폭을 제공한다. WAN 보다 LAN이 구성이 더 쉽고, 거리도 가까우며, 비용도 적게들기 때문이다. 만약 클라이언트가 빠른 LAN에 있는 캐시로부터 사본을 가져온다면, 캐싱 성능을 대폭 개선할 수 있다.
빠른 LAN을 통한 문서 조회
예를들어 샌프란시스코 지사에 있는 사용자는 애틀랜타 본사로부터 문서를 받는데 30초가 걸릴 수 있다. 만약 이 문서가 샌프란시스코의 사무실에 캐시되어 있다면, 로컬 사용자는 같은 문서를 이더넷 접속, 즉 LAN을 통해 1초 미만으로 가져올 수 있을 것이다.
3. 거리로 인한 네트워크 지연을 줄여준다.
대역폭이 문제가 되지 않더라도, 거리가 문제될 수 있다. 만약 보스턴과 샌프란시스코 사이에 네트워크 통신을 한다면 그 거리는 4,400 킬로미터이고, 신호의 속도를 빛의 속도(300,000 킬로미터 / 초)로 가정하면 편도는 약 15ms, 왕복은 30ms 가 걸린다.
만약 웹페이지가 20개의 작은 이미지를 포함하고 있다면, 이 속도에 비례하여 통신 시간이 소요된다. 추가 커넥션에 의한 병렬처리가 이 속도를 줄일 수 있지만, 이보다 더 떨어진 거리거나, 훨씬 더 복잡한 웹페이지일 경우 거리로 인한 속도 지연은 무시할 수 없다.
캐시는 이러한 거리를 수천 킬로미터에서 수십 미터로 줄일 수 있다.
4. 갑작스런 요청 쇄도(Flash Crowds)에 대처 가능하다.
원 서버로의 요청을 줄이기때문에 갑작스런 요청 쇄도 (Flash Crowds) 에 대처할 수 있다.
적중과 부적중 (cache hit, cache miss)
캐시에 요청이 도착했을 때, 그에 대응하는 사본이 있다면 이를 이용해 요청이 처리될 수 있다. 이를 캐시 적중(cache hit)라고 하고, 대응하는 사본이 없다면 원 서버로 요청이 전달된다. 이를 캐시 부적중(cache miss)라고 한다.
웹 캐시 체감하기
1. 기본 셋팅
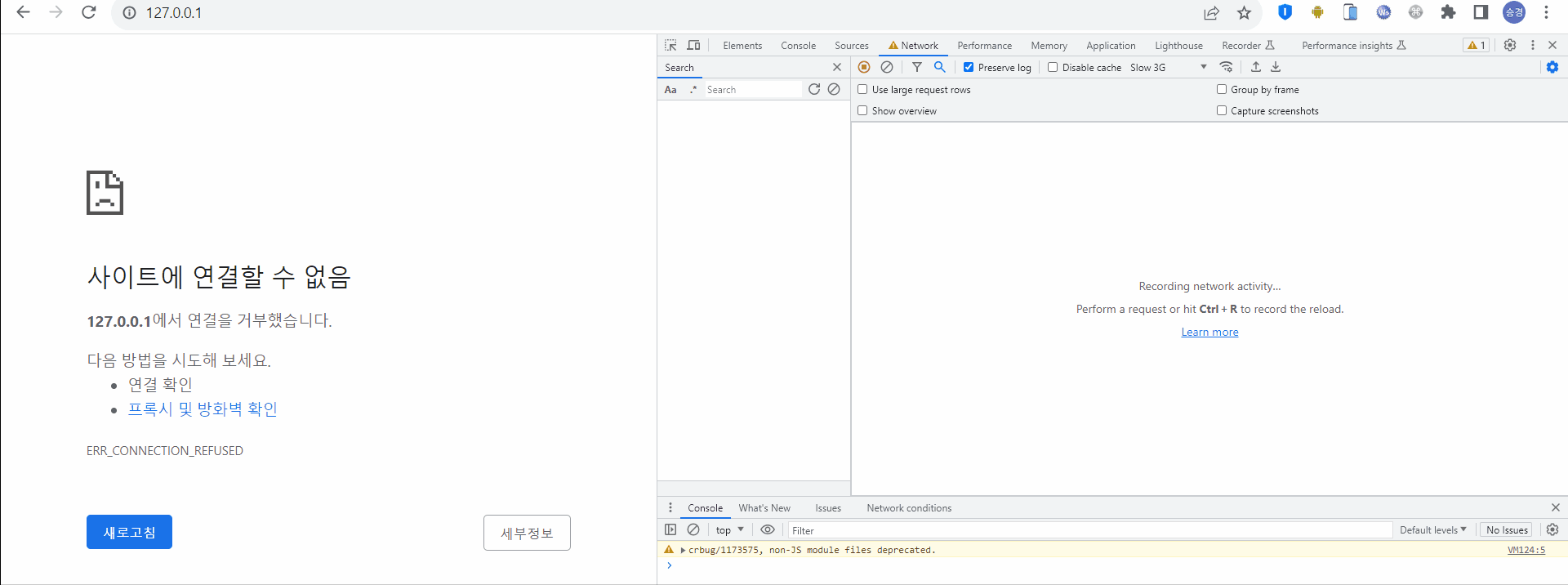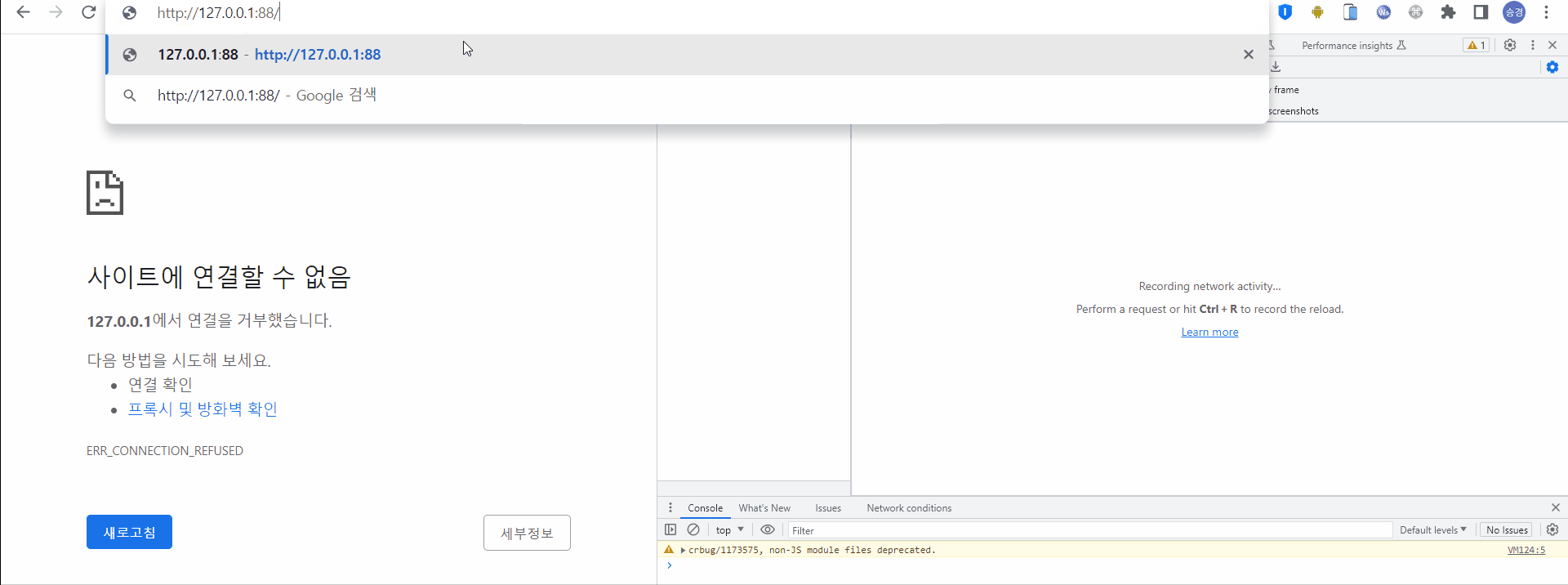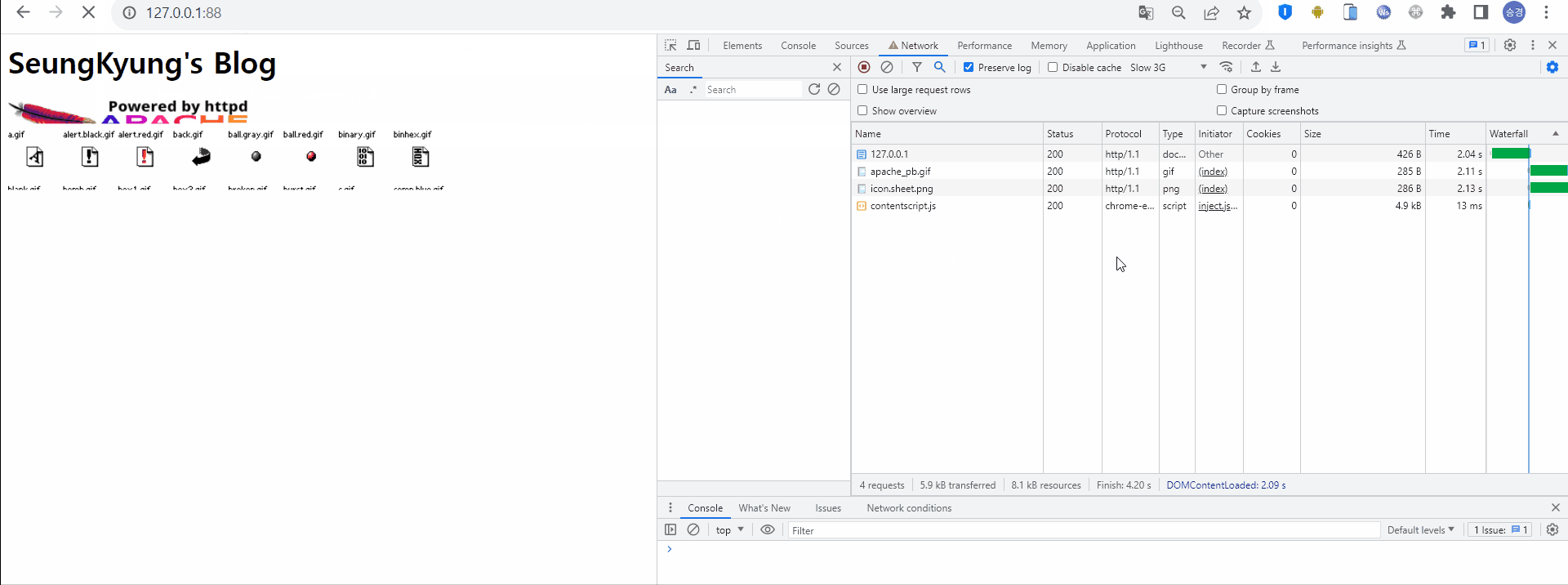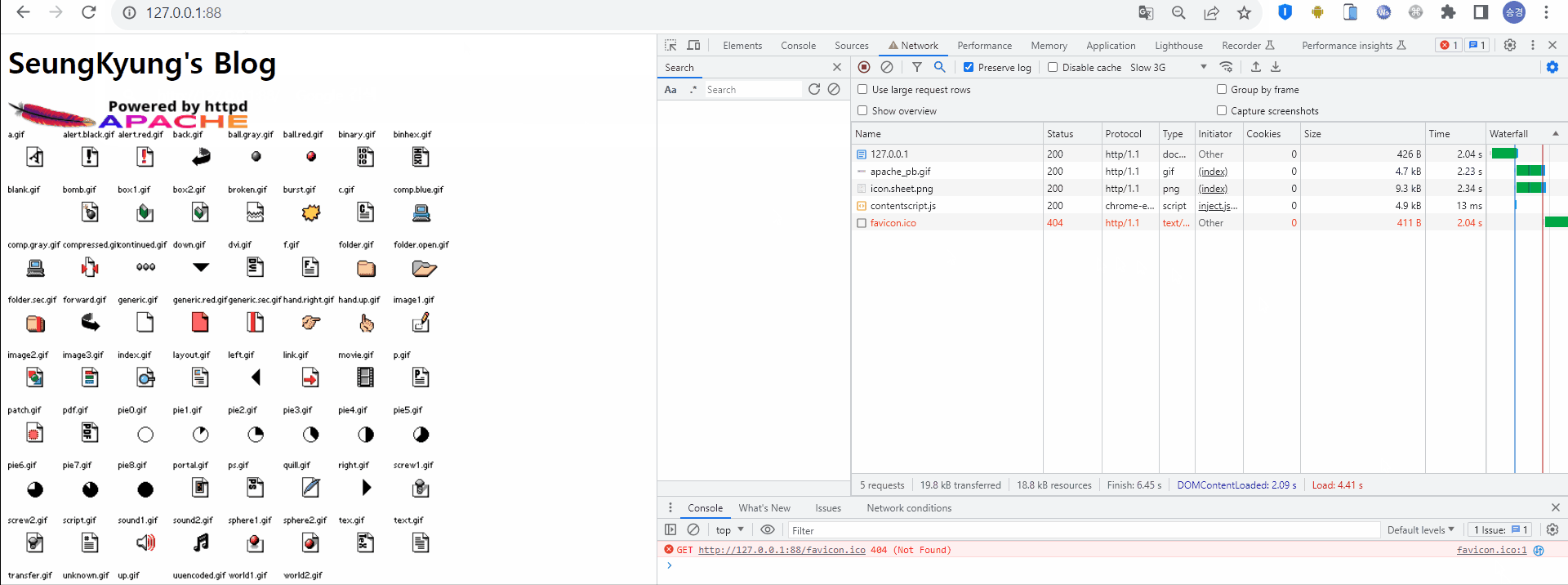
실제로 웹 캐시를 적용했을때와 그렇지 않았을 때의 차이를 비교해보자. 테스트 환경으로는 웹서버인 Apache 2.4 버전을 사용했으며, 보다 확실하게 체감하기 위해 Network 속도를 Slow 3G로 설정하였다. 이는 크롬 개발자 도구에서 설정 가능하다.
Network 속도 설정
1. 웹 캐시로부터 읽어오지 않은 응답
1) 최초 HTTP 통신
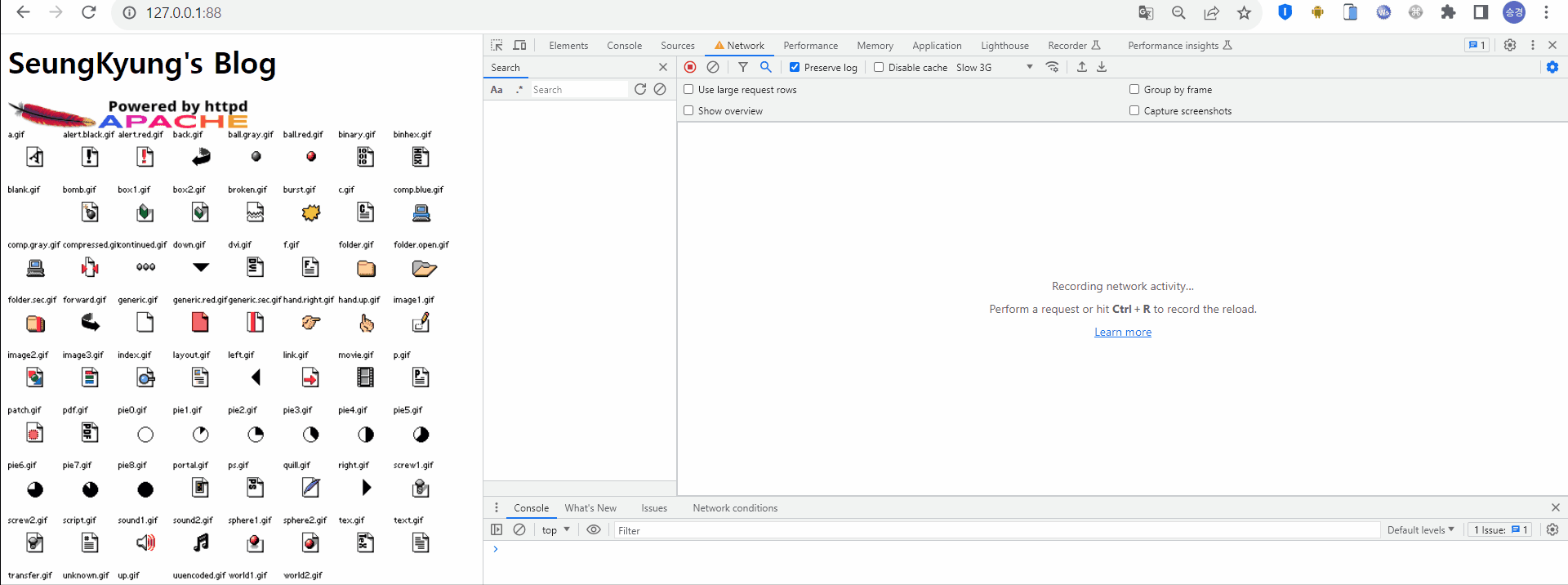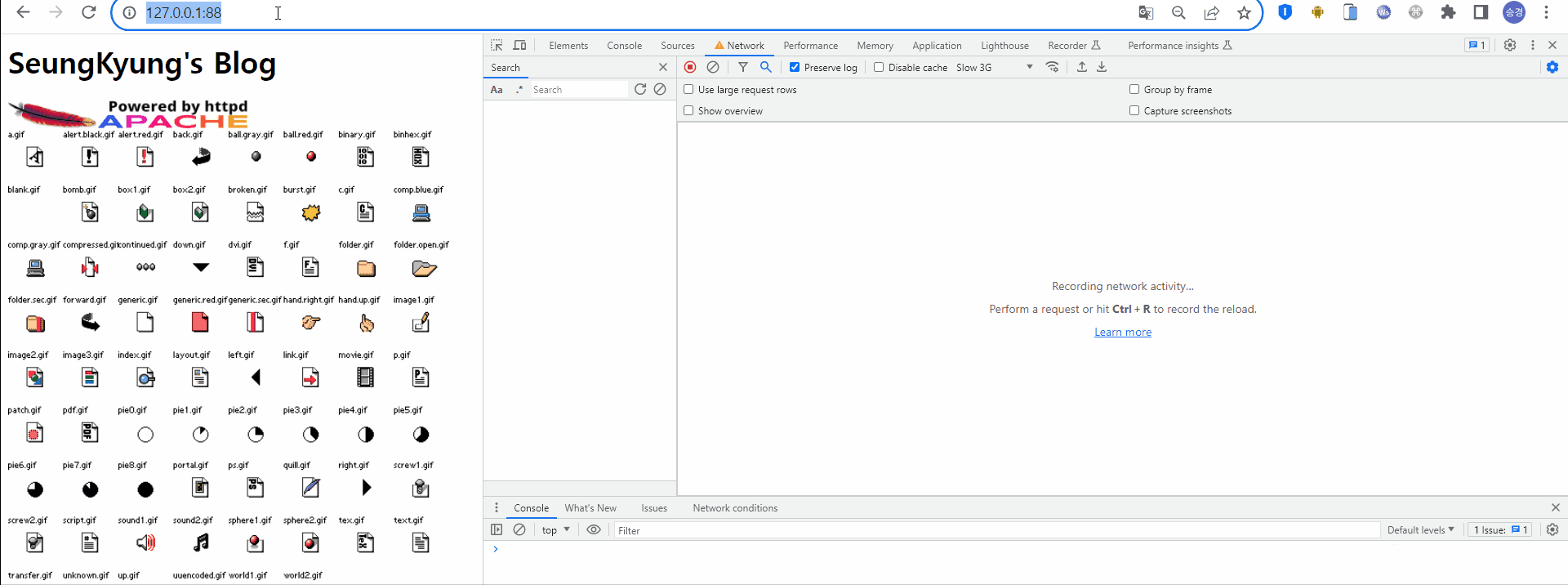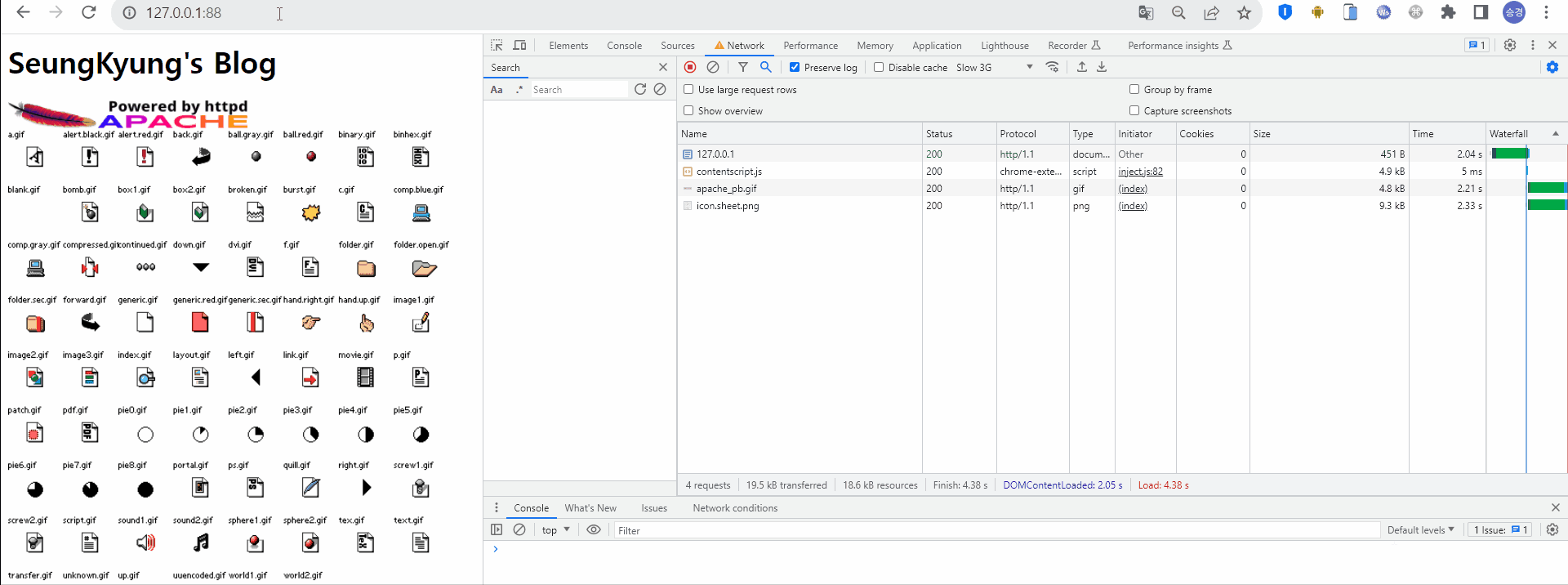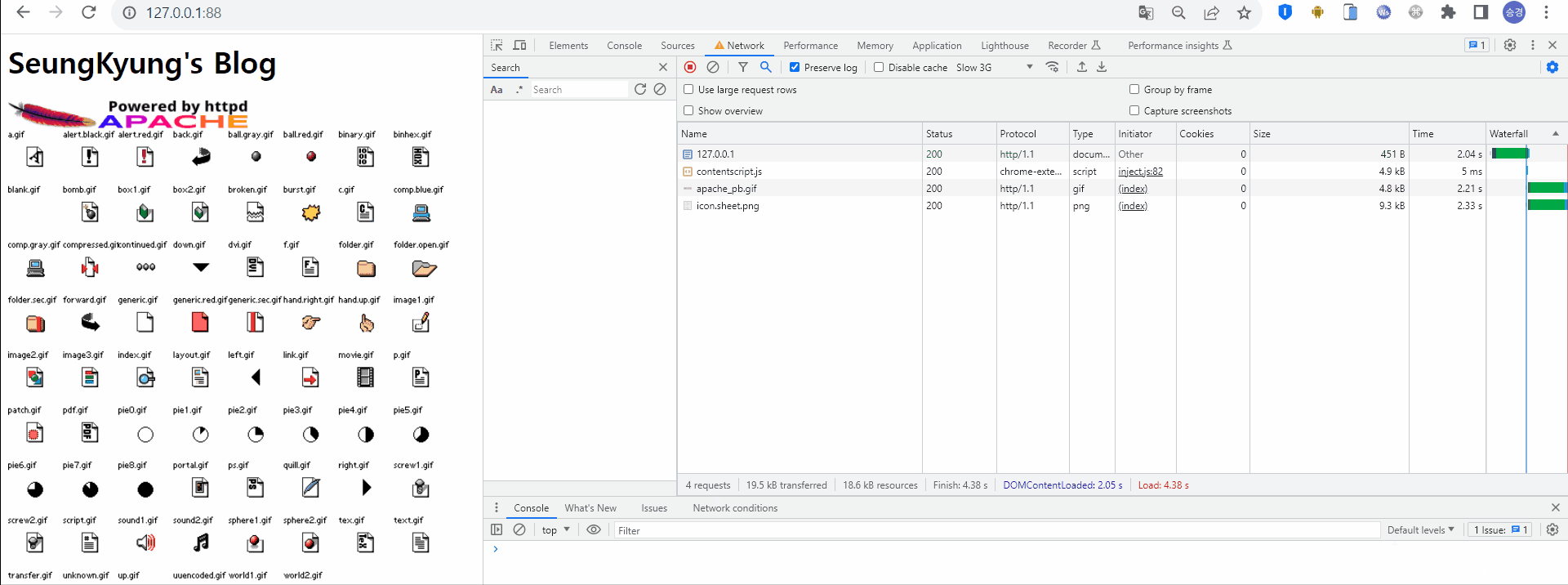
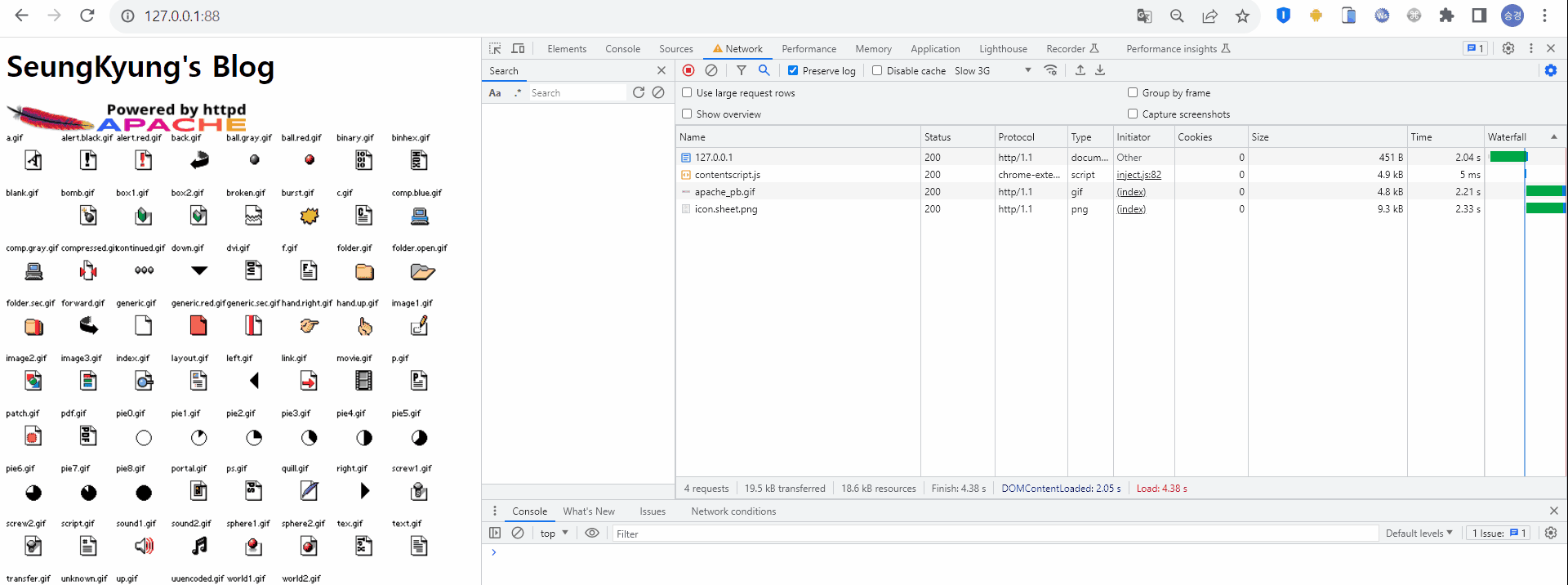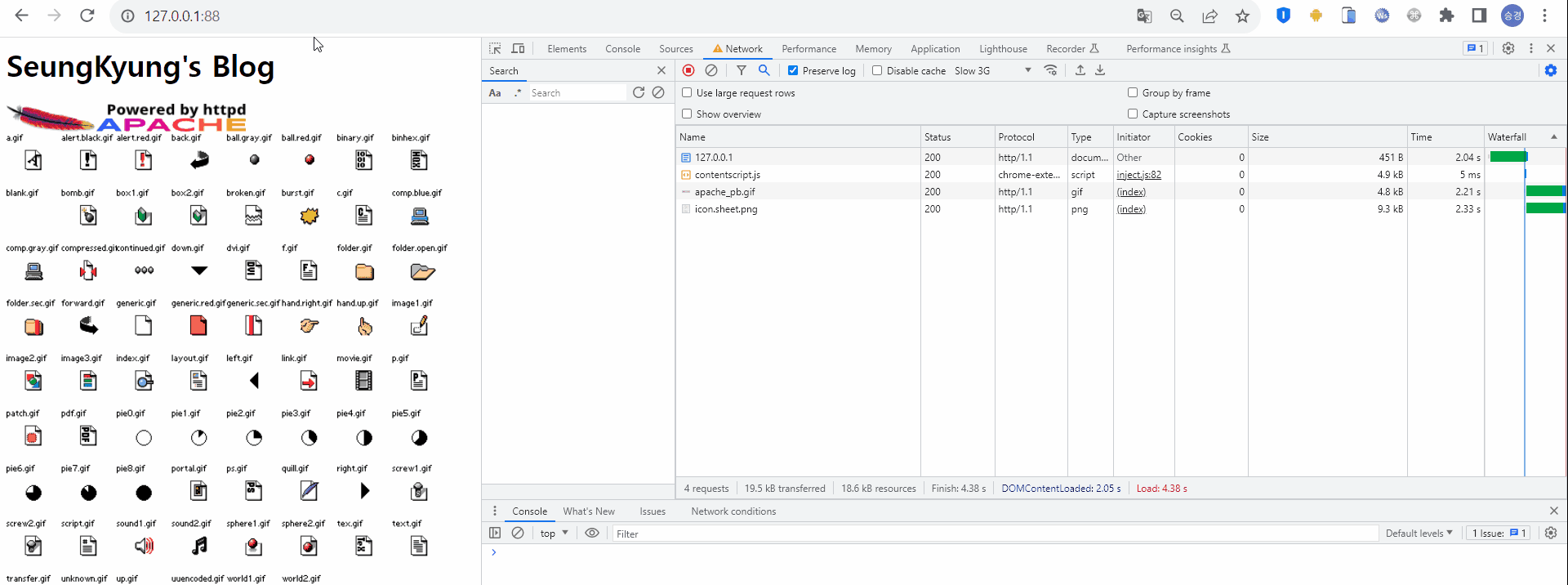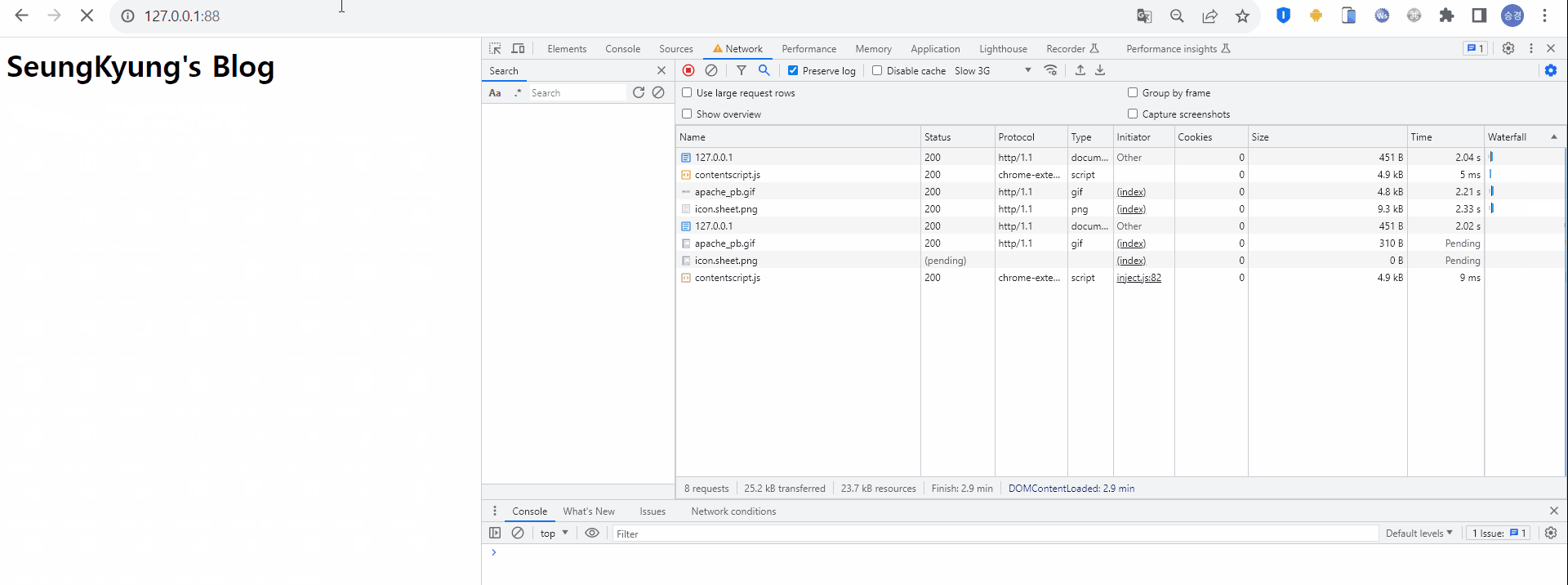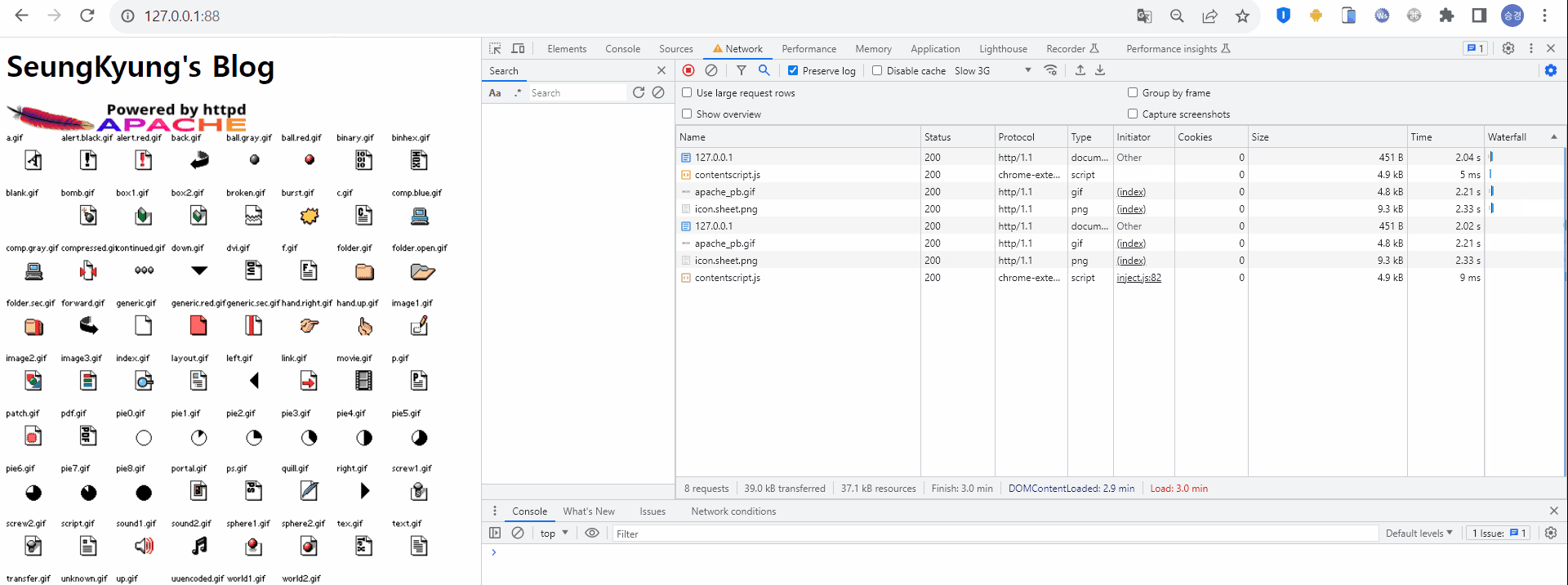
최초 웹서버 접속 시 HTML 형태의 응답을 받고, HTML 내에 존재하는 정적 리소스를 로딩하기 위해 서버로 요청하고 있다. 이때 해당 리소스의 Size는 5~20 kb, Time은 약 2초 정도 걸렸다.
캐시를 적용하지 않았을 때의 첫번째 HTTP 통신
2) 두번째 HTTP 통신
이후 동일 URI로 재요청 한다. 마찬가지로 HTML 형태의 응답을 받고, HTML 내에 존재하는 정적 리소스를 로딩하기 위해 다시 서버로 요청하고 있다. Size와 Time 모두 이 전 요청과 동일하다. 이를 통해 정적데이터가 필요할 때마다 서버로 요청한다는 것을 알 수 있다.
캐시를 적용하지 않았을 때의 두번째 HTTP 통신
2. 웹 캐시로부터 읽어온 응답
1) 최초 HTTP 통신
최초 웹서버 접속 시 HTML 형태의 응답을 받고, HTML 내에 존재하는 정적 리소스를 읽어오기 위해 서버로 요청하고 있다. 이때 해당 리소스의 Size는 5~20 kb, Time은 약 2초 정도 걸렸다.
캐시를 적용했을 때의 첫번째 HTTP 통신
2) 두번째 HTTP 통신
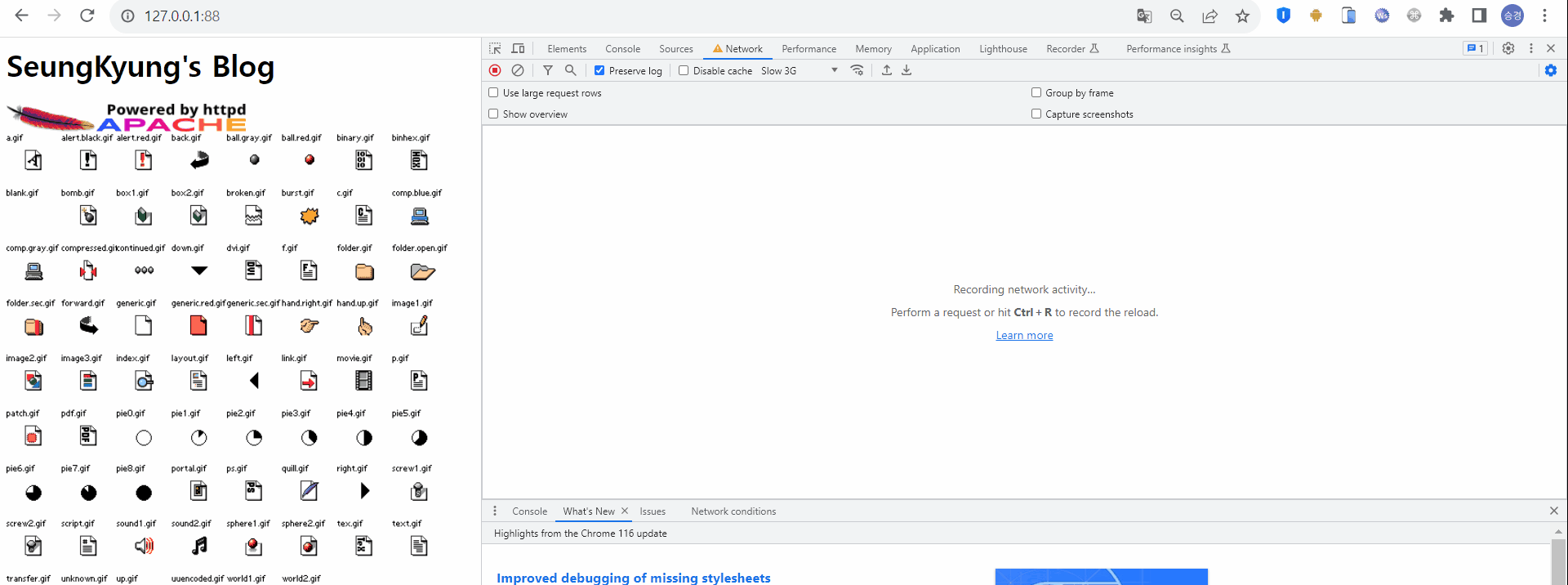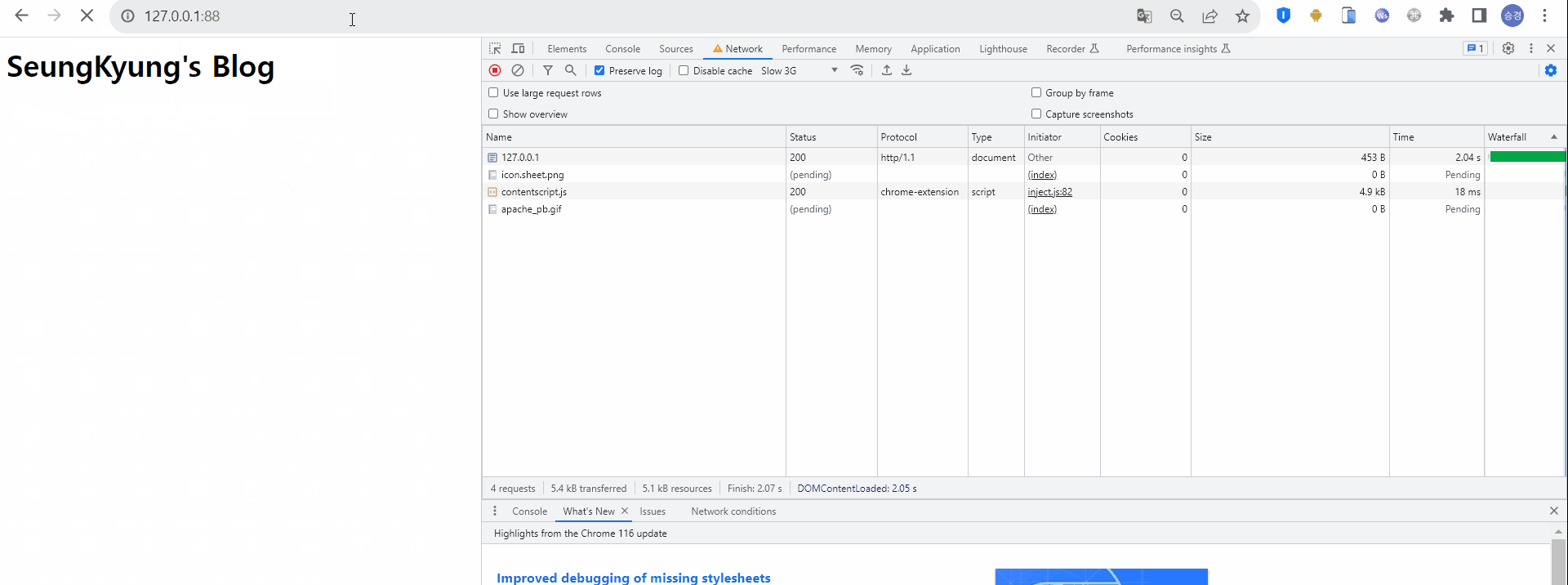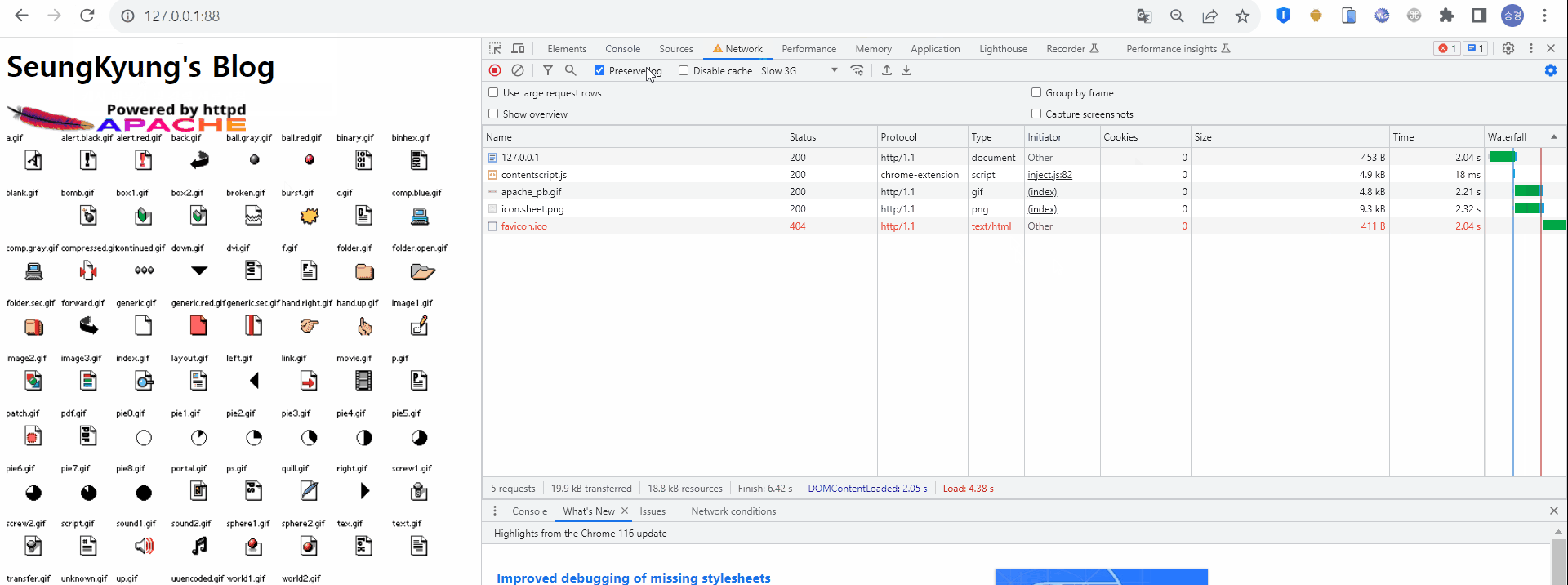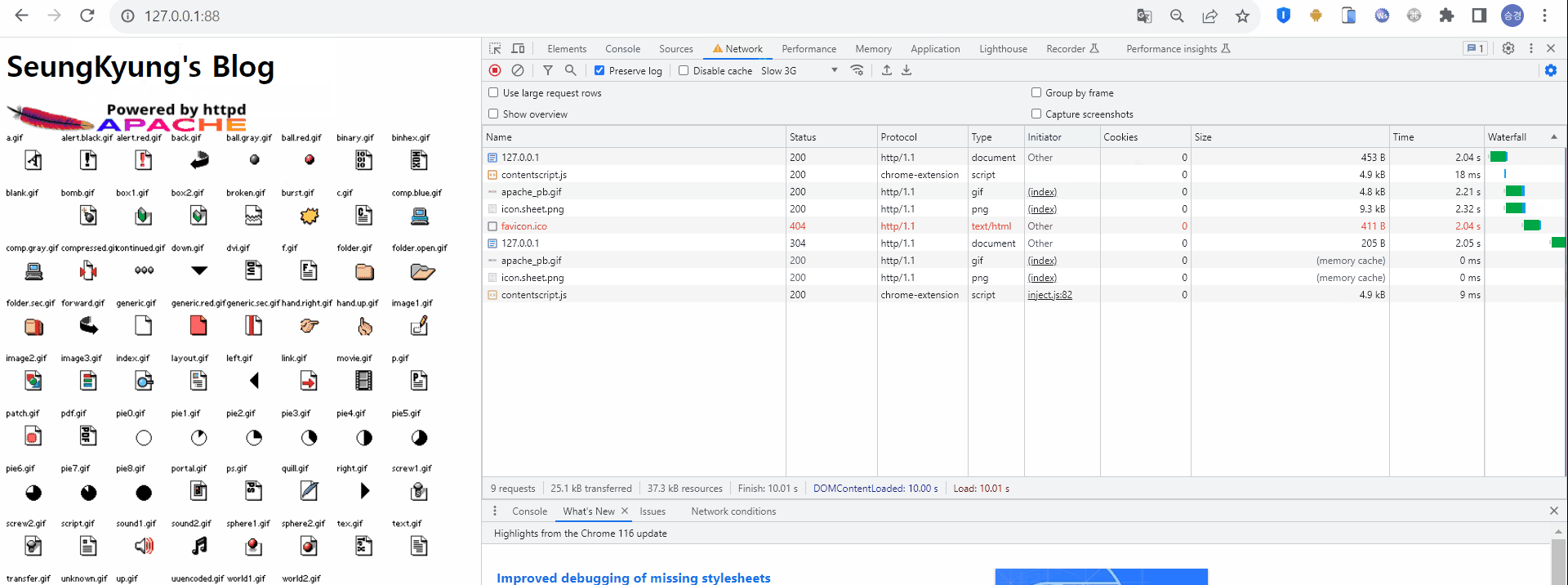
이후 동일 URI로 재요청 한다. 마찬가지로 HTML 형태의 응답을 받고, HTML 내에 존재하는 정적 리소스를 읽고 있다. 그런데 다른점이 있다. Size에 memory cache 가 적혀있고, Time은 0ms이다. 해당 리소스를 서버가 아닌 memory에서 조회했다는 것을 알 수 있다. 이를 통해 정적데이터가 캐시에 저장되어 있을 경우 캐시에서 로드한다는 것을 알 수 있다.
캐시 옵션 설정하기
캐시는 Cache-Control이라는 HTTP Header로 설정할 수 있다. 먼저 해당 옵션을 살펴보자.
1. Cache-Control
설정 값
내용
no-store
캐시에 리소스를 저장하지 않는다.
no-cache
캐시 만료기간에 상관하지 않고 항상 원 서버에게 리소스의 재검사를 요청한다.
must-revalidate
캐시 만료기간이 지났을 경우에만 원 서버에게 리소스의 재검사 요청한다.
public
해당 리소스를 캐시 서버에 저장한다.
private
해당 리소스를 캐시 서버에 저장하지 않는다. 개인정보성 리소스이거나 보안이 필요한 리소스의 경우 이 옵션을 사용한다.
max-age
캐시의 만료기간(초단위)을 설정한다.
※ 재검사가 뭔가요?
재검사(Revalidation)는 신선도 검사라고도 하며, 캐시가 갖고 있는 사본이 최신 데이터인지를 서버를 통해 검사하는 작업을 말한다. 최신 데이터인 경우 304 Not Modifed 응답을 받게 되는데, 이는 '캐시에 있는 사본 데이터가 최신이며, 수정되지 않았다'라는 뜻을 의미한다. 이 경우 클라이언트는 해당 리소스를 캐시로부터 로드하게 된다.
2. Apache httpd.conf 설정
Apache 웹서버의 httpd.conf를 통해 설정할 수 있다. 필자의 경우 캐시의 만료기간을 10초로 설정하기 위해 아래 구문을 최하단에 넣어주었다. 서버를 재시작하여 설정을 적용하고 서버로 요청을 보내보자.
Header Set Cache-Control "max-age=10"
만료기간 10초가 지나기 전에 다시 요청할 경우 캐시 메모리에 저장된 리소스를 가져옴을 확인할 수 있다.
max-age=10 에 대한 테스트
3. HTTP Status 304
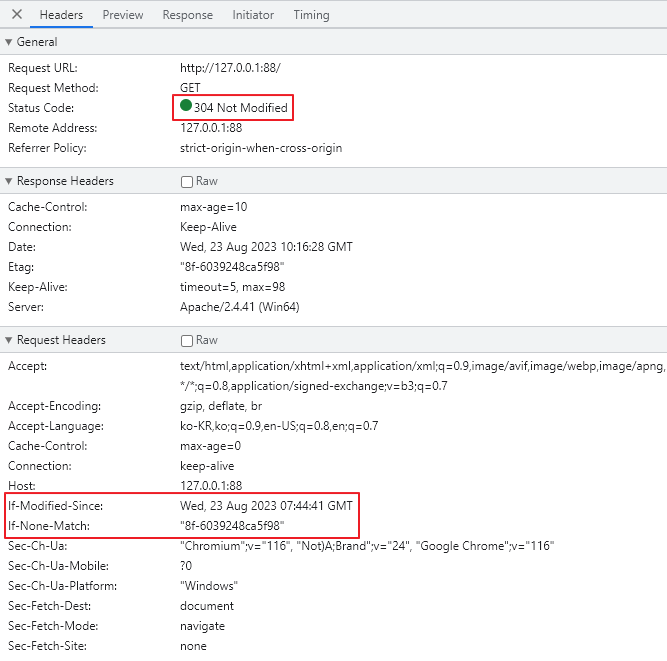
캐시의 만료기간인 10초가 지나자 재검사를 진행했고, 서버의 리소스가 바뀌지 않아 304 상태코드를 리턴받고 있다. 그럼 재검증은 HTTP 메시지의 어떤 값을 통해 확인할 수 있는걸까?
200 > 304 StatusCode
요청 응답 데이터
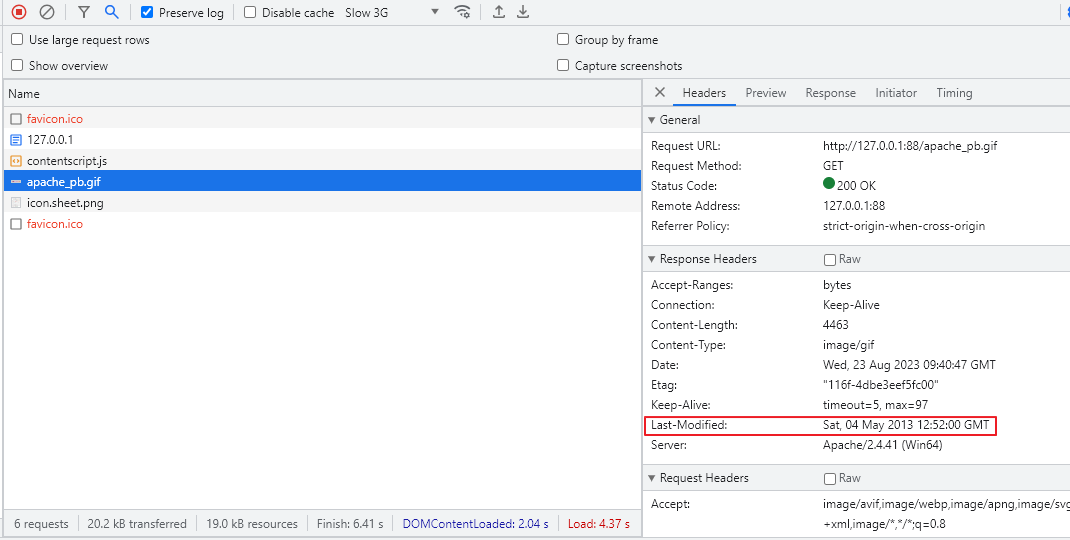
서버를 통해 리소스를 응답받으면 Response Header에 해당 리소스의 마지막 수정날짜가 들어간다. 아래 이미지를 보면 Last-Modified 헤더에 Sat, 04 May 2013 12:52:00 GMT로 되어있다.
HttpResponse - Last-Modified
이를 우리나라 시간으로 환산하면 2013년 5월 4일 21시 52분인데, 실제 서버에 있는 리소스의 마지막 수정날짜이다.
apache_pb.gif 파일 정보
이 후 서버로 리소스 요청을 보낼 때 요청 헤더의 If-Modified-Since 에 리소스의 마지막 수정날짜를 보낸다. 서버는 이 값과 실제 수정 날짜를 비교하여 일치하지 않을 경우, 즉 리소스가 변경된 경우에 200 코드와 함께 해당 리소스를 내려준다.
리소스가 변경되지 않았을 땐 304를, 리소스가 삭제되었다면 404를 응답한다.
캐시 포톨로지
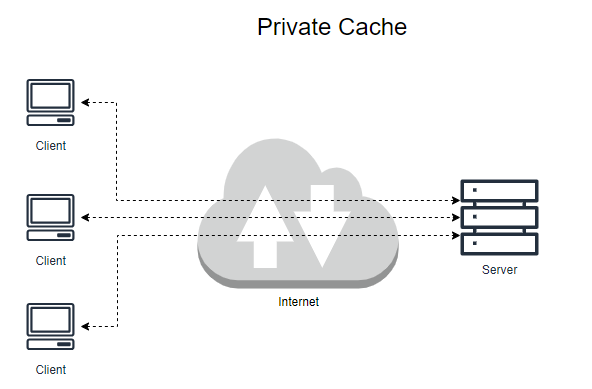
캐시는 한 명의 사용자에게만 할당될 수 있고, 수천 명의 사용자에게 공유될 수도 있다. 한명에게만 할당된 캐시를 전용 캐시, private cache라 하고, 여러 사용자가 공유하는 캐시는 공용 캐시, public cache 라고 한다.
private cache의 대표적인 예는 방금 설명했던 브라우저 캐시이다. 웹 브라우저는 개인 전용 캐시를 내장하고 있으며 컴퓨터의 디스크 및 메모리에 캐시해놓고 사용한다.
Private cache
public cache의 대표적인 예는 프락시 캐시라고 불리는 프락시 서버이다. 각각 다른 사용자들의 요청에 대해 공유된 사본을 제공할 수 있어 private cache보다 네트워크 트래픽을 줄일 수 있다.
Public cache
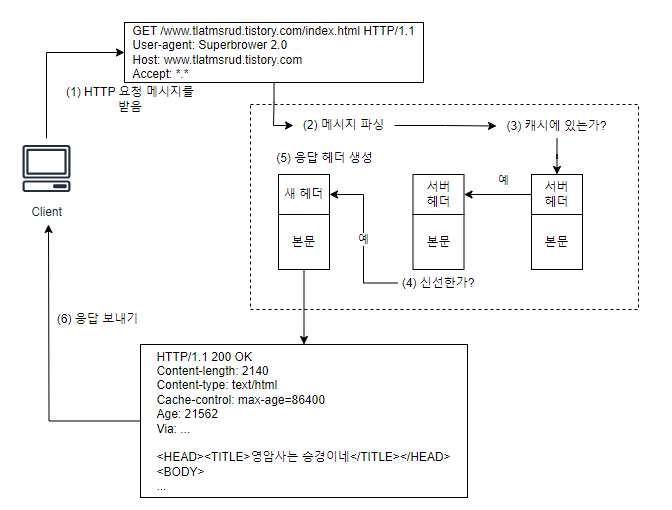
캐시 처리 단계
웹 캐시의 기본적인 동작은 총 일곱 단계로 나뉘어져 있다.
캐시 처리 단계
1. 요청 받기
먼저 캐시는 네트워크 커넥션에서의 활동을 감지하고, 들어오는 데이터를 읽어들인다. 즉, 서버로 요청하기 전 캐시에서 선 작업이 진행된다. (캐시는 HTTP의 응용계층에서 처리된다.)
2. 파싱
캐시는 요청 메시지를 여러 부분으로 파싱하여 헤더 부분을 조작하기 쉬운 자료구조에 담는다. 이는 캐싱 소프트웨어가 헤더 필드를 처리하고 조작하기 쉽게 만들어준다.
3. 검색
캐시는 URL을 알아내고 그에 해당하는 로컬 사본이 있는지 검사한다. 만약 문서를 로컬에서 가져올 수 없다면, 그것을 원 서버를 통해 가져오거나 실패를 반환한다.
4. 신선도 검사
HTTP는 캐시가 일정 기간 동안 서버 문서의 사본을 보유할 수 있도록 해준다. 이 기간동안 문서는 신선하다고 간주되고 캐시는 서버와의 접촉 없이 이 문서를 제공할 수 있다. 하지만 max-age를 넘을 정도로 너무 오래 갖고 있다면, 그 객체는 신선하지 않은 것으로 간주되며, 캐시는 그 문서를 제공하기 전 문서에 어떤 변경이 있었는지 검사하기 위해 서버와 통신하여 재검사 작업을 진행한다.
5. 응답 생성
캐시는 캐시된 응답을 원 서버에서 온 것처럼 보이게 하고 싶기 때문에, 캐시된 서버 응답 헤더를 토대로 응답 헤더를 새로 생성한다.
6. 전송
응답 헤더가 준비되면, 캐시는 응답을 클라이언트에게 돌려준다.
7. 로깅
대부분의 캐시는 로그 파일과 캐시 사용에 대한 통계를 유지한다. 각 캐시 트랜잭션이 완료된 후, 캐지 적중과 부적중 횟수에 대한 통계를 갱신하고, 로그파일에 요청 종류, URL 그리고 무엇이 일어났는지를 알려주는 항목을 추가한다.
올해 6월부터 코로나 위기 단계가 하향 조정됨에 따라 7일 격리였던 격리 수준이 5일로 완화되었다. :) 어떤 단계에 따라 격리 수준 변경되고 있는데 우리가 사용하는 DB, 트랜잭션에도 격리 수준이란게 존재한다. 트랜잭션 격리수준이란 무엇인지 차근차근 이해해보자.
제공 : 질병관리청
2. 트랜잭션 격리수준이란?
2.1. 정의
트랜잭션 격리수준이란 동시에 여러 트랜잭션이 처리될 때, 트랜잭션끼리 얼마나 고립(격리)되어 있는가에 대한 수준을 말한다.
2.2. 트랜잭션은 원래 격리된거 아닌가?
트랜잭션의 성질 중 격리성(Isolation)이 있다. 격리성이란 트랜잭션 수행 시 다른 트랜잭션이 끼어들이 못하도록 보장하는 것을 말한다. 이는 '트랜잭션은 서로 완전히 격리되어 있으니 다른 트랜잭션이 끼어들지 못합니다. 땅땅땅!' 이 아니다. 격리성을 강화시킨다면 다른 트랜잭션이 끼어들지 못하게 보장할 수 있고, 약화시킨다면 다른 트랜잭션도 중간에 끼어들 수 있다는 의미이다. 코로나처럼 7일간 무조건 집콕일수도 있고, 5일간 집콕 권고일수도 있다.
그럼 이렇게 격리수준을 나눈 이유는 뭘까? 먼저 트랜잭션의 성질을 살펴보자.
2.3. 트랜잭션 ACID
1) Atomicity (원자성)
한 트랜잭션의 연산은 모두 성공하거나, 모두 실패해야한다. 예를들어 돈을 이체할 때 보내는 쪽에서 돈을 빼오는 작업만 성공하고, 받는 쪽에 돈을 넣는 작업은 실패하면 안된다.
2) Consistency (일관성, 정합성)
트랜잭션 처리 후에도 데이터의 상태는 일관되어야 한다. '모든 계좌 정보에는 계좌 번호가 있어야 한다.'라는 제약 조건 즉, 상태가 걸려있을 때, 계좌번호를 삭제하거나 계좌번호가 없는 상태로 계좌정보를 추가하려 한다면 '모든 계좌 정보에는 계좌 번호가 있어야 한다' 에서 '모든 계좌 정보에는 계좌 번호가 없어도 된다' 라는 상태로 변경되게 된다. 때문에 상태를 변화시키는 트랜잭션은 실패하는것이다.
3) Isolation (격리성)
트랜잭션 수행 시 다른 트랜잭션의 연산이 끼어들이 못하도록 보장한다. 하나의 트랜잭션이 다른 트랜잭션에게 영향을 주지 않도록 격리되어 수행되어야한다.
4) Durability (지속성)
성공적으로 수행된 트랜잭션은 영원히 반영되어야 한다. 중간에 DB에 오류가 발생해도 다시 복구되어야 한다. 즉, 트랜잭션에 대한 로그가 반드시 남아야한다는 의미하기도 한다.
2.4. 트랜잭션의 Isolation
여기서 격리성을 따져보자. 트랜잭션 수행 중간에 다른 트랜잭션이 끼어들수 없다면 어떻게될까? 모든 트랜잭션은 순차적으로 처리될 것이고, 데이터의 정확성은 보장될 것이다. 속도는 어떨까? 트랜잭션이 많아질수록 처리를 기다리는 트랜잭션은 쌓여간다. 앞에 있는 트랜잭션이 기다리는 시간만큼 대기 시간은 늘어난다. 결국 트랜잭션이 처리되는 속도가 느려지게 되고, 어플리케이션 운용에 심각한 문제가 발생할 수 있다.
결국 준수한 처리 속도를 위해서는 트랜잭션의 완전한 격리가 아닌 완화된 수준의 격리가 필요하다. 이처럼 속도와 데이터 정확성에 대한 트레이드 오프를 고려하여 트랜잭션의 격리성 수준을 나눈것이 바로 트랜잭션의 격리수준이다.
3. 트랜잭션 격리수준 단계
3.1. DBMS마다 다른 격리수준
트랜잭션 격리수준은 총 4단계로 Uncommitted Read, Committed Read, Repeatable Read, Serializable 로 구성된다. DBMS 마다 격리 수준에 대한 내용이 다를 수 있으니 보다 정확하게 알기 위해서는 공식 문서를 확인해야 한다. 필자는 MySQL 에서 제공하는 격리수준을 기준으로 하였으며, 필요에 따라서는 타 DBMS에서의 격리수준도 비교 분석하였다. 참고로 MySQL의 기본 격리수준은 Repeatable Read 이다.
먼저 격리수준이 가장 낮은 Uncommitted Read부터 알아보자.
3.2. Uncommitted Read (커밋되지 않은 읽기)
다른 트랜잭션에서 커밋되지 않은 데이터에 접근할 수 있게 하는 격리 수준이다. 가장 저수준의 격리수준이며, 일반적으로 사용하지 않는 격리수준이다.
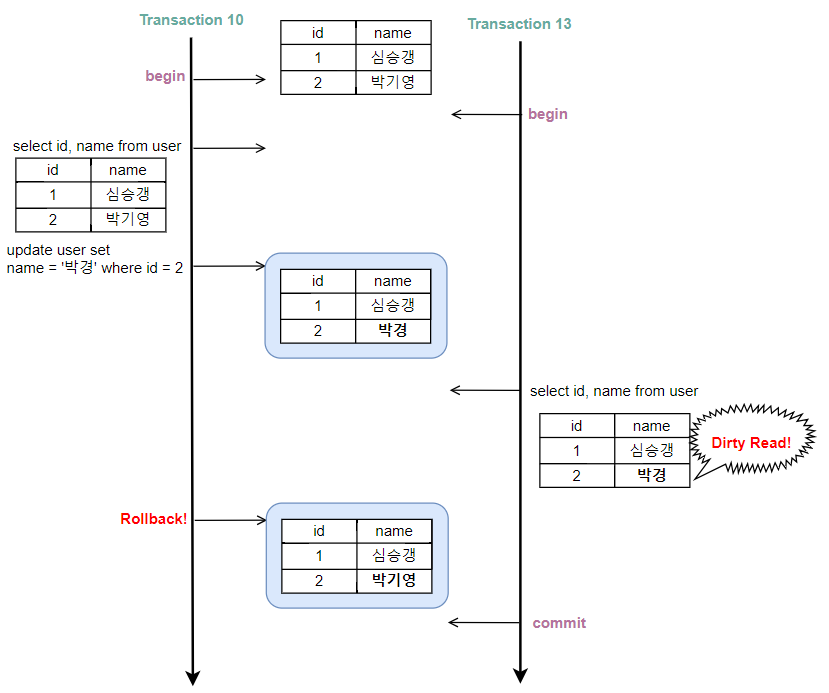
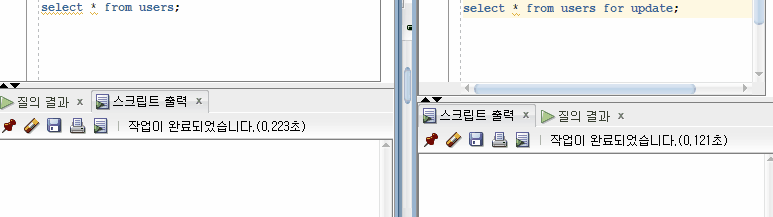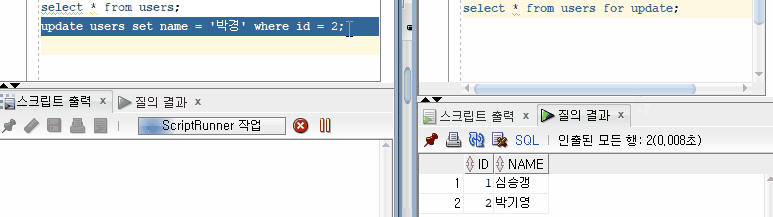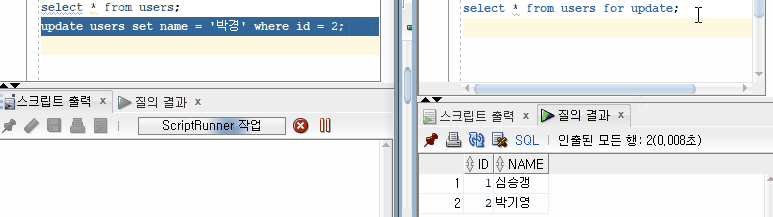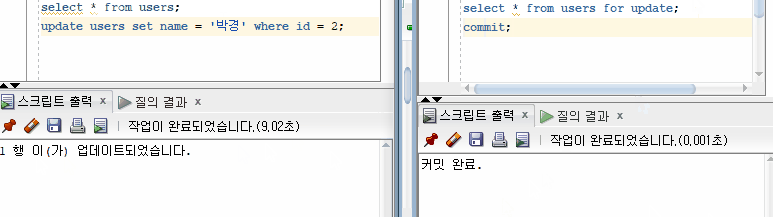
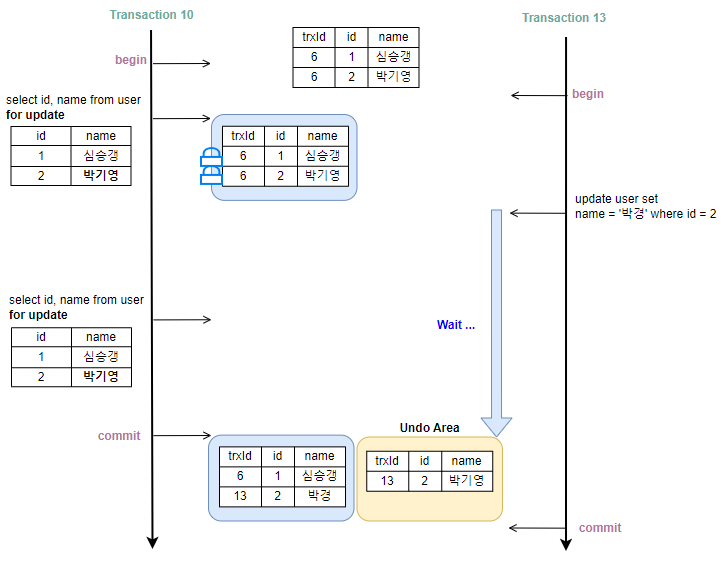
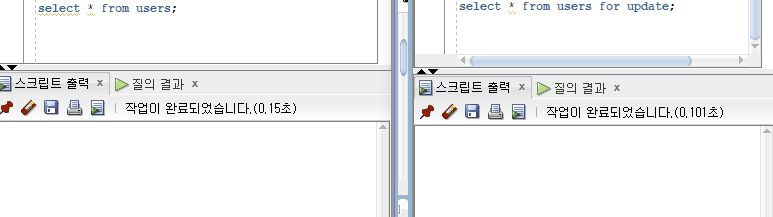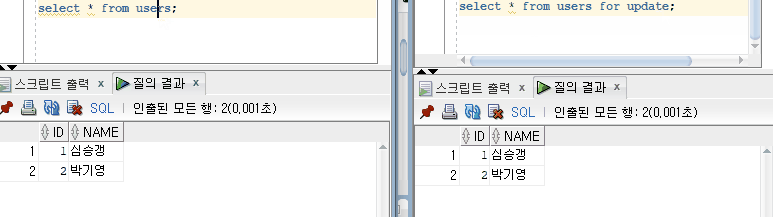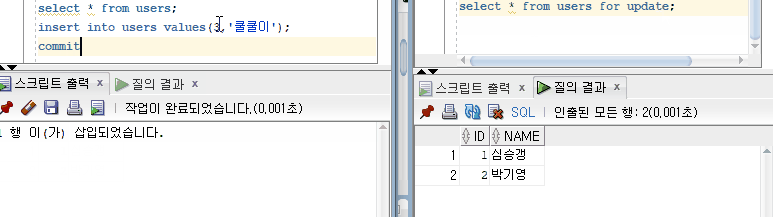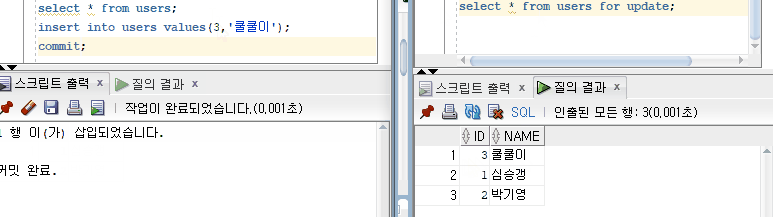
10번 트랜잭션이 '박기영'이라는 데이터를 '박경'으로 UPDATE 한 후 Commit 하지 않았을 때 13번 트랜잭션에서 접근하여 커밋되지 않은 데이터를 읽을 수 있다.
Uncommitted Read
그런데 13번 트랜잭션이 데이터를 읽은 후 10번 트랜잭션에 문제가 발생하여 롤백된다면 데이터 부정합을 발생시킬 수 있다.
데이터 부정합은 어플리케이션에 치명적인 문제를 야기할 수 있다. 그래서인지 오라클에서는 이 수준을 아예 지원하지 않는다. 이처럼 커밋되지 않는 트랜잭션에 접근하여 부정합을 유발할 수 있는 데이터를 읽는 것을 더티읽기(Dirty Read)라고 한다.
Dirty Read
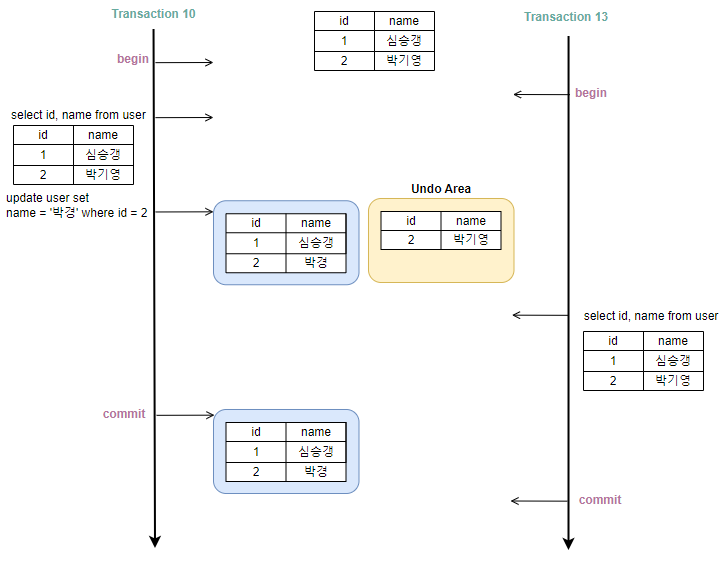
3.2 Committed Read (커밋된 읽기)
다른 트랜잭션에서 커밋된 데이터로만 접근할 수 있게 하는 격리 수준이다. MySQL을 제외하고 대부분 이를 기본 격리수준으로 사용한다.
10번 트랜잭션이 '박기영'이라는 데이터를 '박경'으로 UPDATE 한 후 Commit 하지 않았을 때, 13번 트랜잭션에서 이를 조회할 경우 UPDATE 전 데이터인 '박기영' 이라는 값이 조회된다. Dirty Read 현상은 발생하지 않는다.
그럼 어떻게 Read Committed는 UPDATE 전 값을 조회한걸까? 그 키는 바로 Undo 영역에 있다.
Committed Read
※ Undo 영역
앞서 살펴본 트랜잭션의 성질 중 지속성(Durability)을 보면 다음과 같이 정의되어 있다.
성공적으로 수행된 트랜잭션은 영원히 반영되어야 한다. 중간에 DB에 오류가 발생해도, 다시 복구되어야 한다. 즉, 트랜잭션에 대한 로그가 반드시 남아야한다는 성질을 의미하기도 한다.
트랜잭션에 대한 로그가 반드시 남아있어야 한다. 즉, 복구는 로그를 기반으로 처리된다. 이 로그는 크게 두 가지가 있다. 오류에 의한 복구에 사용되는 Redo Log와 트랜잭션 롤백을 위해 사용되는 Undo Log이다.
다시실행의 뜻을 갖는 Redo는 커밋된 트랜잭션에 대한 정보를 갖고 있고(왜? 복구하려면 다시 실행해줘야하니까), 실행 취소의 뜻을 갖는 Undo는 데이터베이스의 변경이 발생할 경우 변경되기 전 값과 이에 대한 PK 값을 갖고 있다(왜? 롤백하면 다시 되돌려야 하니까)
그런데 Undo 영역이라고 말한 이유는 Undo Log가 Undo Log Buffer 형태로 메모리에 저장되고, 특정 시점에 디스크에 저장된 Undo Log File 에 I/O 작업으로 쓰여지기 때문이다. 추가로 이렇게 단계가 나눠지는 이유는 데이터에 변경사항이 생길때마다 Disk에 I/O 작업을 하는것보다 메모리 입력하고, 읽는것이 속도와 리소스 측면에서 유리하기 때문이다.
정리하면, Undo 영역이란 변경 전 데이터가 저장된 영역이고, Commit 하기 전 데이터를 읽어올 수 있는 이유는 Undo 영역에 있는 데이터를 읽어오기 때문이다.
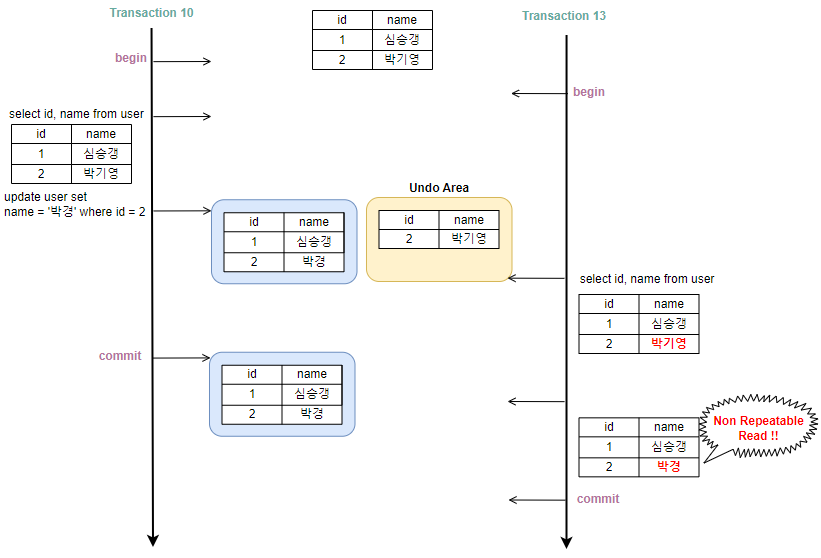
※ Non Repeatable Read(반복 가능하지 않은 읽기) 현상 발생
Committed Read 수준에서는 Non Repeatable Read 현상이 발생한다. 이는 하나의 트랜잭션에서 동일한 SELECT 쿼리를 실행했을 때 다른 결과가 나타나는 것을 말한다.
아래 그림을 보면 13번 트랜잭션이 동일한 SELECT 쿼리를 두 번 실행했을 때 결과가 다른 것을 볼 수 있는데, 10번 트랜잭션이 데이터 UPDATE 후 COMMIT 하기 전, 후에 SELECT 쿼리를 실행했었기 때문이다.
Non Repeatable Read
3.3. Repeatable Read (반복 가능한 읽기)
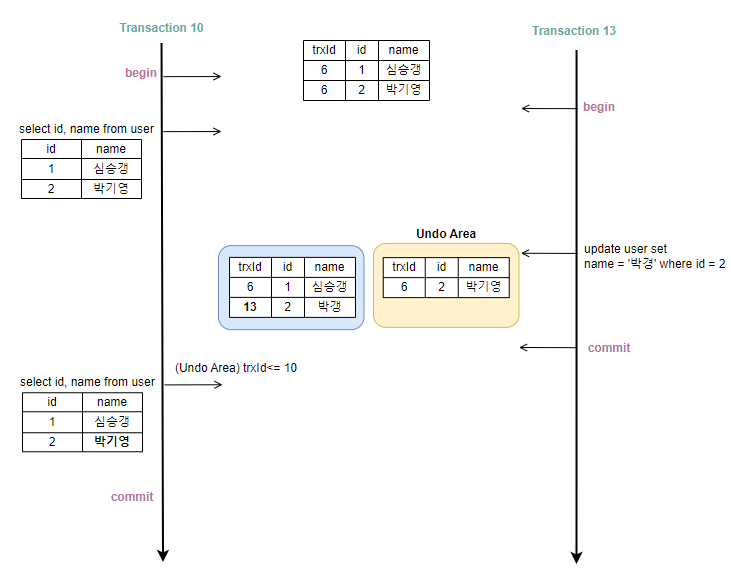
Non Repeatable Read 문제를 해결하는 격리 수준으로, 커밋된 데이터만 읽을 수 있되 자신보다 낮은 트랜잭션 번호를 갖는 트랜잭션에서 커밋한 데이터만 읽을 수 있는 격리수준이다. 이게 가능한 이유는? 그렇다 Undo 로그때문이다. 또한 트랜잭션 ID를 통해 Undo 영역의 데이터를 스냅샷처럼 관리하여 동일한 데이터를 보장하는 것을 MVCC(Multi Version Concurrency Control) 라고 한다.
아래 그림에서 10번 트랜잭션은 10번 보다 작은 트랜잭션에서 커밋한 데이터만 읽을 수 있으므로 13번 트랜잭션에서 변경한 내용은 조회할 수 없다. 같은 SELECT 쿼리가 두 번 실행됐을 때 같은 결과가 조회되므로 Non-Repeatable-Read 현상이 해결됨을 확인할 수 있다.
Repeatable Read
※ Repeatable Read를 지원하지 않는 오라클?!
오라클은 Repeatable Read 수준을 지원하지 않는다. 그럼 Non Repeatable Read 문제를 해결할 수 없을까? 아니다! 해결할 수 있는 방법이 있다. 바로 Exclusive Lock을 사용하는 방법이다.
※ Exclusive Lock (배타적 잠금 / 쓰기 잠금)
Exclusive Lock이란 특정 레코드나 테이블에 대해 다른 트랜잭션에서 읽기, 쓰기 작업을 할 수 없도록 하는 Lock 이다. SELECT ~ FOR UPDATE (업데이트 하려고 조회하는거에요~ 그러니까 다른 트랜잭션에서 접근못하도록 막아주세요~) 구문을 통해 사용할 수 있다.
아래 참고 자료를 보자. SELECT ~ FOR UPDATE 를 사용하여 조회된 레코드에 대해 Exclusive Lock 을 걸면 다른 트랜잭션에서 해당 레코드에 대해 쓰기 작업 시 LOCK이 해제될때까지 대기하는 것을 볼 수 있다.
그런데 이상한 점이 하나 있다. Exclusive Lock은 읽기나 쓰기 작업을 할 수 없도록 한다고 했는데 아래 gif를 보니 다른 트랜잭션에서 SELECT를 통해 읽기 작업을 하고있다. 이건 바로 MVCC 기술을 통해Undo 영역에서 읽어오는 것이다.
Exclusive Lock
이제 이 과정을 그림으로 이해해보자. 10번 트랜잭션이 select id, name, from user for update 를 실행하여 레코드를 조회함과 동시에 Exclusive Lock이 건다. 다른 트랜잭션에서 접근 시 Lock이 풀릴때까지 대기하게 된다. 이후 10번 트랜잭션이 똑같은 쿼리를 실행해도 처음 조회했던 데이터와 같은 데이터가 조회되게 된다. Non-Repeatable Read 문제가 해결된것이다.
Oracle의 Exclusive Lock을 통한 Non Repeatable Read 문제 해결
※ Phantom Read (유령 읽기)
Repeatable Read와 Exclusive Lock 를 통해 Non Repeatable Read 문제를 해결했다. 그런데 새로운 문제가 발생한다. 바로 Phantom Read 현상이다.
Phantom Read는 하나의 트랜잭션 내에서 여러번 실행되는 동일한 SELECT 쿼리에 대해 결과 레코드 수가 달라지는 현상을 말한다. Non Repeatable Read는 레코드의 데이터가 달라지는 것을 의미한다면 Phantom Read는 기존 조회했던 레코드의 데이터는 달라지지 않지만, 새로운 레코드가 나왔다가 사라졌다가 하는 것이다. 마치 유령처럼!! :(
먼저 Exclusive Lock 을 보자. UPDATE, DELETE에 대한 Lock을 걸어 읽기, 쓰기 작업을 막을 수 있었지만, INSERT에 대한 LOCK은 걸 수 없다. 그 이유는 조회된 레코드에 대해서만 Exclusive Lock을 거는 것이지 조회되지 않은 레코드, 즉 나중에 추가할 레코드에 대해서는 Lock을 걸지 않기 때문이다.
이는 Exclusive Lock을 사용해도 다른 트랜잭션에서 INSERT 작업이 가능하다는 뜻이고, 아래와 같이 처음엔 조회되지 않았던 레코드가 조회될 수 있다는 것이다. 마치 유령처럼!! :)
Oracle Exclusive Lock의 Phantom Read 현상
※ MySQL 에서는 발생하지 않는 Phantom Read
InnoDB 엔진을 사용하는 MySQL 에서는 Repeatable Read 수준에서 Phantom Read 현상이 발생하지 않는다. 그 이유는 SELECT ~ FOR UPDATE를 통해 Lock을 걸때 Exclusive Lock이 아닌 Next Key Lock 방식을 사용하기 때문이다.
※ Next Key Lock
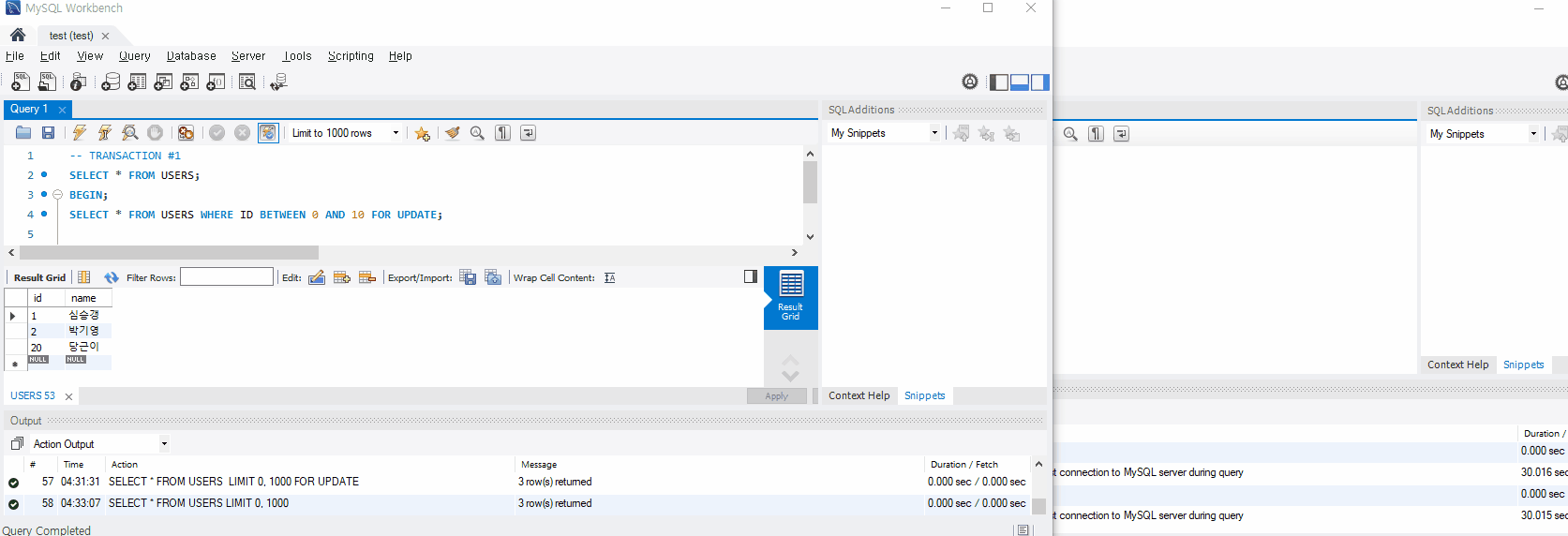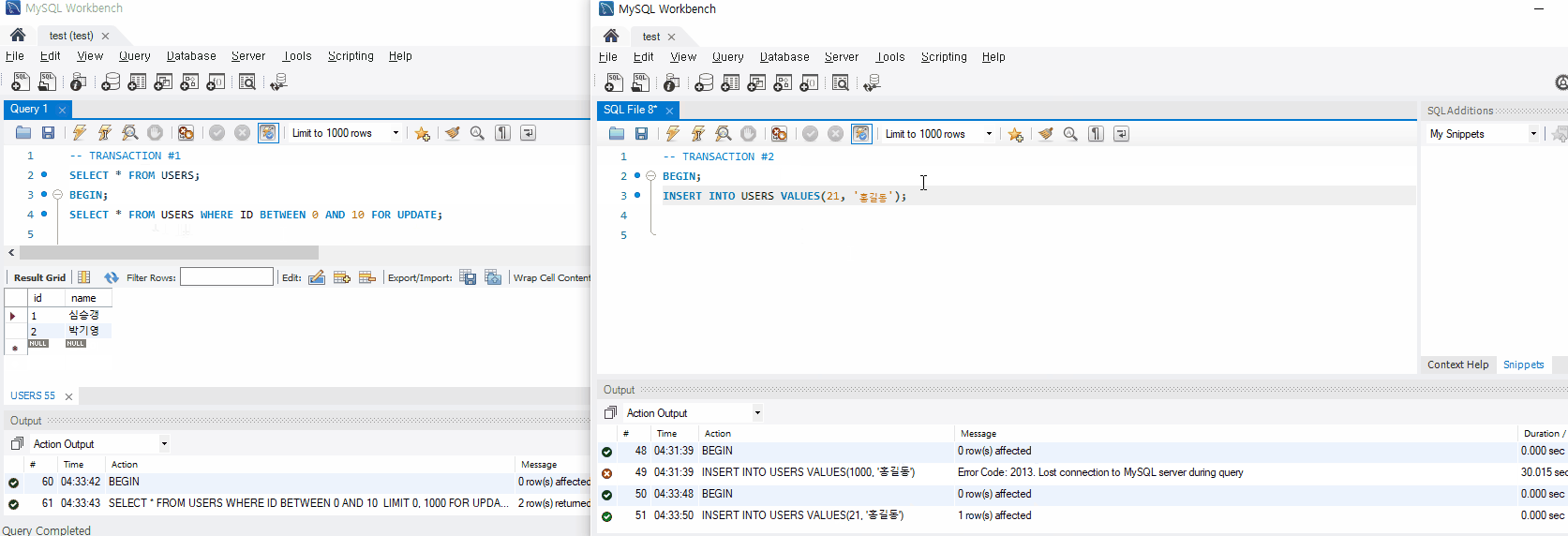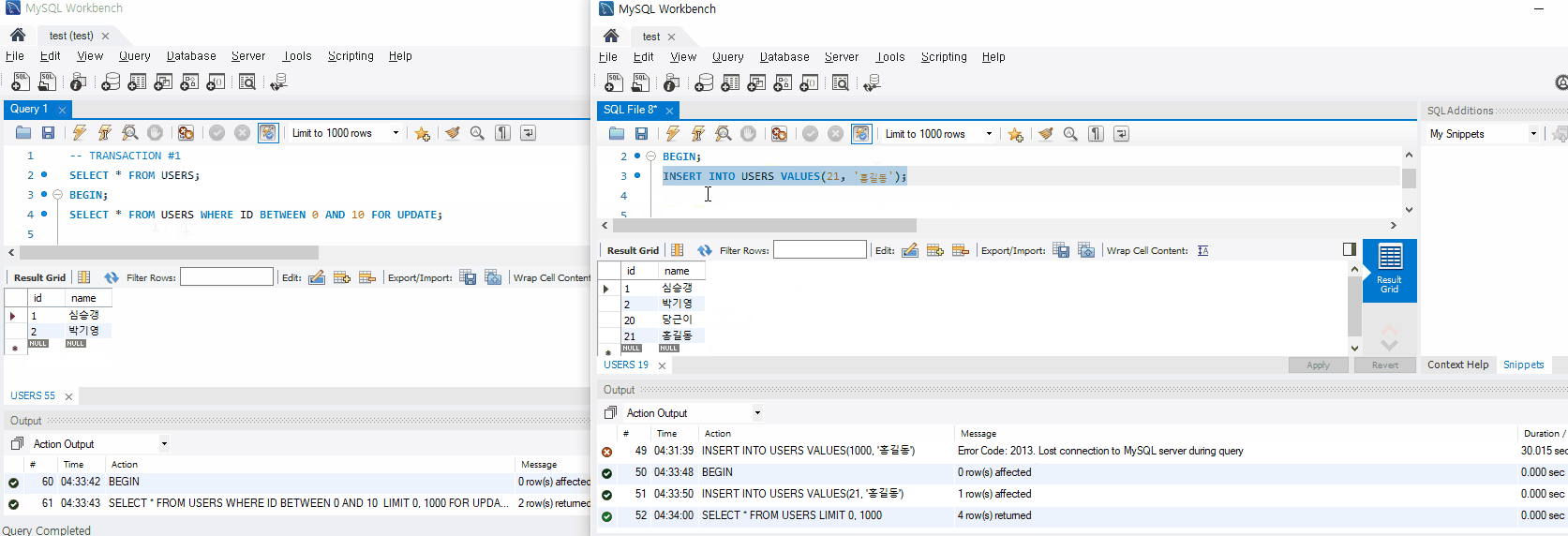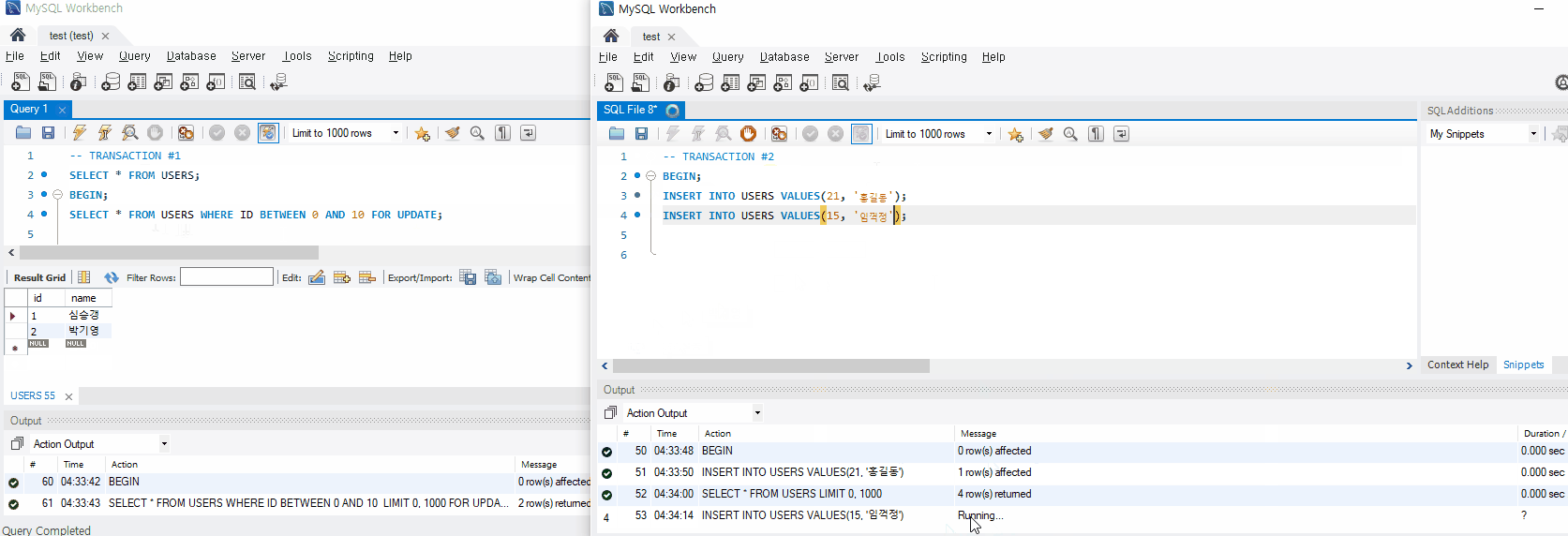
Next Key Lock은 조회된 레코드에 대한 Lock 뿐 아니라 실행 쿼리에 대한 범위에 설정되는 Lock이다. 즉, Next Key Lock은 Record Lock, Gap Lock 이 조합된 Lock 이다.
예를 들어 SELECT * FROM USERS WHERE ID BETWEEN 0 AND 10 FOR UPDATE쿼리를 실행시키면, 조회된 레코드에 대한 Record Lock과,0 < ID <=10 에 해당하는 범위에 해당하는 Gap Lock이 걸린다. 이뿐 아니다! 마지막으로 조회된 레코드의 Index인 ID에 대해 그 다음 존재하는 ID 까지의 범위를 Gap Lock으로 설정한다. 만약 아래와 같이 2 이후 ID가 20인 레코드가 있다면 2 ~ 20 까지 Gap Lock을 건다.
때문에 다른 트랜잭션에서 SELECT 쿼리를 통해 정해진 GAP에 해당하는 데이터를 INSERT 시도할 경우 Gap Lock으로 인해 대기상태에 들어가기 되고, 이는 기존 트랜잭션의 여러 동일 SELECT 쿼리에 대한 동일성이 보장되게 된다.
ID
NAME
1
심승갱
2
박기영
20
홍길동
Mysql Next Key Lock
참고로 SELECT * FROM USERS FOR UPDATE 쿼리를 실행한다면 조회된 모든 레코드에 대한 Lock과 모든 범위에 대한 GAP LOCK이 걸리게 된다.
3.4. Serializable
가장 고수준의 격리수준으로 트랜잭션을 무조건 순차적으로 진행시킨다. 트랜잭션이 끼어들 수 없으니 데이터의 부정합 문제는 발생하지 않으나, 동시 처리가 불가능하여 처리 속도가 느려진다.
트랜잭션이 중간에 끼어들 수 없는 이유는 SELECT 쿼리 실행 시 Shared Lock(공유 잠금)을, INSERT, UPDATE, DELETE 쿼리 실행 시 Exclusive Lock (MySQL의 경우 Nexy Key Lock)을 걸어버리기 때문이다.
※ Shared Lock
Shared Lock이란 다른 트랜잭션에서의 읽기 작업은 허용하지만, 쓰기 작업은 불가능하도록 한다. SELECT ~ FOR SHARE 문법을 통해 사용하는데, 키 포인트는 이 Lock의 경우 동시에 Exclusive Lock을 허용하지 않는다는 것이다.
SELECT 쿼리를 실행하면 Shared Lock이 걸리게 되고, 다른 트랜잭션에서 UPDATE, DELETE, INSERT와 같은 쿼리 실행 시Exclusive Lock, Next Key Lock을 얻어오려고 할텐데 Shared Lock 은 이를 허용하지 않아 대기 상태가 된다. 이러한 원리에 의해 트랜잭션들이 중간에 끼어들 수 없고 순차적으로 되는것이다.
4. 회고
처음엔 트랜잭션의 격리 수준에 따라 트랜잭션 내에서 실행한 쿼리들이 어떻게 동작하는지만 이해하고 넘어가려 했지만, 이를 이해하기 위해서는 Commit, Rollback의 내부 동작 부터 시작해 Undo Log, Undo Log Buffer와 File, Cache Miss, Hit, MVCC, Lock 등.. DB에 대한 전반적인 흐름과 개념들을 알아야 했다. 또한 DBMS 마다 격리 수준의 내용이 달라지다보니 이를 비교 분석해야 했다.
먼저 영상을 통해 기본 개념들을 학습했고, 여러 블로그 글들을 참고하여 정리해나갔다. chat gpt를 통해 이해한 내용을 검증하기도 했다. (근데 이녀석이 자꾸... 말을 바꾸네...??) 잘못된 내용을 바로잡을때마다 쓰고, 지우고를 반복했다. 그림을 갈아 엎어야할때는 마음이 너무 아팠지만, 그때 나사가 빠진(?) 부분이나 이해가 필요한 부분들을 시각적으로 찾을 수 있어서 매우 유익했다.
이 글은 필자가 이해한 내용을 정리한거라 틀린 내용이 있을 수 있다. 독자분들께서 읽고 수정이 필요한 부분이나 추가 정보가 있다면 꼭! 댓글로 부탁드린다! :)
토비의 스프링을 공부하다가 SQL 쿼리 정보를 담은 XML 파일을 언마샬링하여 객체로 만들고, 이를 DAO 로직에 적용하는 부분이 있었다. 이때 사용했던 마샬링과 언마샬링에 대해 포스팅한다.
2. 마샬링
2.1. 마샬링이 뭔가요?
마샬링이란 객체나 특정 형태의 데이터를 저장 및 전송 가능한 데이터 형태로 변환하는 과정을 말한다.
언마샬링은 변환했던 데이터를 원래대로 복구하는 과정을 말한다.
2.2. 개념이 잘 와닿지 않아요
데이터를 다른 형태로 변환한다는 개념이 너무 추상적이라 그런지 마샬링의 개념이 잘 이해가 되지 않았다. 그래서 데이터 형태를 변환하는 다른 개념들을 함께 찾아보고, 비교하면서 개념을 이해해보기로 했다.
2.3. 여러가지 변환 과정
찾아보니 인코딩, 디코딩, 파싱과 같은 친숙한 용어들이 보였다. 마샬링도 이와 비슷한 맥락의 개념이라고 생각하니 이해가 훨씬 쉬웠다.
- 마샬링 / 언마샬링
객체나 특정 형태의 데이터를 저장 및 전송 가능한 데이터 형태로 변환하는 과정이다. 예를 들어, 네트워크 통신에서 객체를 전송하기 위해 바이트 스트림으로 변환하는 것이 마샬링이고, 받은 데이터 스트림을 다시 객체로 변환하는 것이 언마샬링이다.
- 인코딩 / 디코딩
데이터를 특정 형식이나 표현 방식으로 변환하는 과정이다. 예를 들어, 텍스트를 UTF-8이나 Base64 형식으로 변환하는 것이 인코딩이고, 원래의 텍스트로 변환하는 것이 디코딩이다.
- 파싱
웹, 문자열, 파일 등으로부터 정보를 추출하여, 원하는 데이터 구조나 객체로 변환하는 과정이다. 예를 들어, 특정 웹페이지의 HTML 문자열을 로드하여 필요한 데이터만을 추출한 후 객체 형태로 저장하는 것이 파싱이다.
- 정규화 / 비정규화
데이터베이스에서 데이터를 효과적으로 저장하거나 조회하기 위해 테이블 구조를 변환하는 과정이다.
- 직렬화 / 역직렬화
객체나 데이터 구조를 연속적인 바이트 스트림으로 변환하는 과정이다. 웹에서는 그 의미가 확장되어 Json 데이터를 객체로 변환하거나, 객체를 Json 데이터로 변환하는 것을 의미한다. 네트워크를 통한 데이터 전송이나 파일 저장 등에 사용된다.
직렬화는 마샬링과 비슷한 개념을 갖고 있는데, 직렬화는 연속적인 바이트 스트림으로의 변환을, 마샬링은 특정 통신 프로토콜이나 파일 포맷에 맞게 데이터를 변환하는 것에 초점을 둠으로써 마샬링이 직렬화보다 더 큰 범위의 과정을 의미한다. 즉, 직렬화는 마샬링이라고 할 수 있지만, 마샬링은 꼭! 직렬화다! 라고 할 순 없다.
3. 마샬링, 어디에 쓰이는데?
필자의 경우 마샬링이라는 용어를 2년차에 처음 접했다. 특정 설정 정보들을 DB에 저장하고, 이 데이터를 통해 XML 파일로 변환하는 방식을 알아보라는 윗분의 요청이 있었고, 이때 마샬링이라는 개념이 XML에만 국한된 것으로 이해했다. 하지만 앞서 내용을 보다시피 아주 포괄적인 개념임을 알 수 있다.
그렇다면, 전송 가능한 데이터 형태로 변환하는 것은 어플리케이션 개발을 함에 있어 꼭 들어가야하는 과정 중 하나인데, 왜 빨리 접하지 못했고, 마샬링이란 기술을 사용한 기억이 없을까? 그 이유는 대부분 프레임워크 내부에서 마샬링이 진행되기 때문이다.
3.1 @RequestBody와 @ResponseBody
Controller 클래스를 작성한다면, 요청은 @RequestBody를 통해 Json 형식의 데이터를 객체로 변환하여 사용하고, 응답은 @ResponseBody를 통해 객체 형태의 데이터를 Json 형식으로 변환하여 내려준다.
이러한 어노테이션을 사용하면 내부적으로 MappingJackson2HttpMessageConverter에 의해 객체와 Json간 변환 과정을 거치게 된다. 웹에서는 이러한 변환 과정을 직렬화, 역직렬화라고 하며, 이는 곧 마샬링, 언마샬링이라고도 할 수 있다.
3.2. Mybatis
전세계적으로 데이터 처리를 위해 JPA를 사용하고 있지만, 우리나라에서 만큼은 Mybatis도 꽤 많이 사용한다고 한다. 필자도 현업에서 JPA 사용을 안하고 Mybatis만을 사용했다. Mybatis는 SQL 쿼리를 자바 코드와 분리하여 개발자가 비지니스 로직에만 집중할 수 있도록 한다. 이때 사용되는 쿼리 정보들은 XML 파일로 관리한다.
포스팅했던 트랜잭션 기능 구현 내용을 정리하면, 어드바이스에는 트랜잭션 기능을, 포인트컷에는 타겟 설정을 하고, 이 둘을 갖는 객체인 어드바이저와 어드바이저 빈을 스캔하는 자동 프록시 생성 객체를 빈으로 등록하여 구현한다.
어찌됐던 아래와 같이 트랜잭션을 시작하고, 타겟 메서드를 실행하고, 트랜잭션을 Commit 또는 Rollback한 후 트랜잭션을 종료하게 된다.
스프링 AOP를 통한 트랜잭션 적용
이와 같이 트랜잭션 기능을 부여하려면 AOP 기반의 여러 설정들이 필요한데, 이러한 설정들과 상호작용하여 트랜잭션 기능을 제공받게 하는 것이 바로 @Transactional 이다.
2. @Transactional 선언만 해줬을 뿐인데??
이 어노테이션을 메서드, 클래스, 인터페이스에 선언만 하면 타겟 메서드 호출 시 기본 속성을 갖는 트랜잭션이 시작된다. 4 가지 속성이 있으며 전파속성, 격리수준 속성, 제한시간 속성, 읽기전용 속성이다.
2.1. 전파 속성
트랜잭션이 어떻게 전파되는지를 정의하는 속성이다. 예를들어 AClass, BClass에 @Transactional을 선언하고, AClass의 메서드 내부에서 BClass의 메서드가 실행된다고 가정해보자. 이때 트랜잭션은 어떻게 전파될까? AClass의 메서드 호출 시 트랜잭션이 시작되고, BClass의 메서드 호출 시 새로운 트랜잭션이 시작될까?
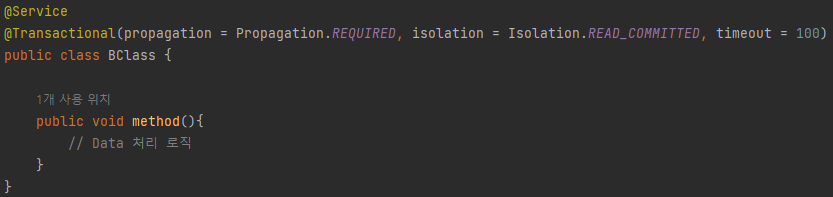
아니다. @Transactional을 선언하게 되면 기본 전파 방식인 PROPAGATION_REQUIRED 방식을 사용하게 되어 BClass의 메서드는 자신에게 전파된 트랜잭션에 참여하게 된다.
반대로 다른 전파 속성으로 설정한다면, 트랜잭션에 참여하지 않거나, 새로운 트랜잭션을 생성하도록 할 수 도있다.
@Service
@Transactional
public class AClass {
private final BClass bClass;
public AClass(BClass bClass){
this.bClass = bClass;
}
public void method(){
// Data 처리 로직
bClass.method();
// Data 처리 로직
}
}
..
@Service
@Transactional
public class BClass {
public void method(){
// Data 처리 로직
}
}
2.2. 전파속성의 종류
일반적으로 사용되는 3가지의 전파 속성이다.
1) PROPAGATION_REQUIRED
가장 많이 사용되는 트랜잭션 전파 속성이다. 진행 중인 트랜잭션이 없으면 새로 시작하고, 있으면 이에 참여한다. 이 방식을 사용할 경우 AClass.method와 BClass.method는 하나의 작업 단위 즉, 하나의 트랜잭션으로 구성되게 되고, 두 메서드가 종료되기 전에 내부에서 예외 (정확히는 런타임 예외)가 발생한다면 둘다 롤백된다.
PROPAGATION_REQUIRED 전파 속성
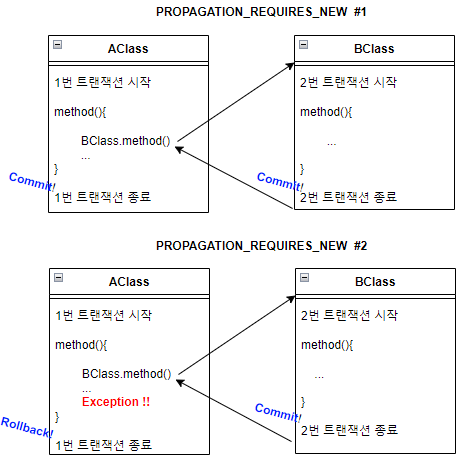
2) PROPAGATION_REQUIRES_NEW
NEW ! 항상 새로운 트랜잭션을 시작한다. 진행 중인 트랜잭션이 있건 없건 새로운 트랜잭션을 생성하고 시작한다. 이 방식을 사용할 경우 BClass의 method 실행 시 1번 트랜잭션과 독립되어 동작하는 2번 트랜잭션이 생성된다.
BClass의 method가 정상적으로 호출 및 종료되면 2번 트랜잭션은 Commit 되므로, 이후 AClass의 method에서 예외가 발생한다 한들 BClass의 Commit된 내용은 Rollback되지 않는다.
PROPAGATION_REQUIRES_NEW 전파 속성
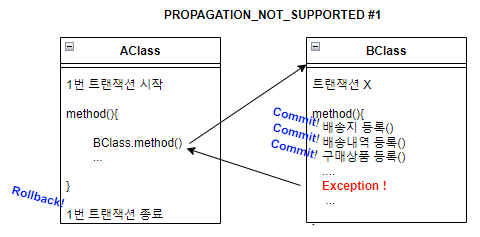
3) PROPAGATION_NOT_SUPPORTED
전파 지원 안해줘!진행 중인 트랜잭션이 있건 없건 트랜잭션 없이 동작하도록 한다. 트랜잭션이 없으니 트랜잭션 전파 지원도 없다는 뜻으로 해석했다. 이 방식을 사용할 경우 DB Connection이 발생할 때마다 트랜잭션 없이 DB 연산이 수행되고 BClass 내부에서 Exception이 발생한다 하더라도, 그 전에 Commit 됐던 내용은 Rollback 되지 않는다.
이와 별개로 AClass는 호출했던 BClass 메서드에서 발생한 예외로 인해 Rollback 된다.
PROPAGATION_NOT_SUPPORTED 전파속성
2.3. 격리수준
트랜잭션 격리 수준은 DB에서 동시에 여러 트랜잭션이 처리될 때, 특정 트랜잭션이 다른 트랜잭션에서 변경하거나 조회하는 데이터를 어느정도까지 허용할거냐를 결정하는 것이다.
격리 수준은 SERIALIZABLE, REPEATABLE READ, READ COMMITED, READ UNCOMMITED 가 있고, 기본적으로 DB 설정에 따르지만 트랜잭션 레벨에서도 설정이 가능하다. 이 내용은 매우 중요하기 때문에 따로 포스팅하도록 하겠다.
2.4. 제한시간
트랜잭션에 대한 제한시간을 설정할 수 있다. 기본 설정은 제한시간이 없는 것이다.
2.5. 읽기전용
트랜잭션에서 읽기 작업만 수행할 수 있도록 제한하는 것이다. 만약 Update, Delete, Insert와 같이 데이터를 조작하는 행위를 할 경우 예외가 발생한다.
3. 어드바이스와 포인트컷
@Transactional은 특정 메서드(포인트컷)에 특정 속성(어드바이스)을 갖는 트랜잭션을 생성하고 시작하도록 한다. 그럼 어디선가 @Transactional 을 포인트컷으로 지정하고, @Transactional에 속성 값에 설정한 트랜잭션 속성을 가져다가 어드바이스에서 트랜잭션 생성 시 사용해야 한다. 이 기능을 하는 클래스들이 뭔지 알아보자.
@Transactional을 통한 속성 설정
3.1. 포인트컷
@Transactional이 선언된 타입 혹은 메서드에 대해서만 대상으로 선정하는 포인트컷이 필요한데, 이 기능을 하는 포인트컷이 바로 TransactionAttributeSourcePointcut 이다.
이 클래스는 @Transactional 붙은 타입 혹은 메서드를 찾아 포인트 컷의 선정 결과로 돌려준다. @Transactional의 속성을 통해 트랜잭션의 속성도 정의하지만 포인트컷의 선정 대상으로도 사용된다.
3.2. 어드바이스
@Transactional에 속성 값을 읽어 트랜잭션을 생성하는 어드바이스가 필요한데, 이 기능을 하는 어드바이스가 바로 TransactionInterceptor 이다. 정확히는 트랜잭션 매니저와 트랜잭션 속성 두가지를 설정하는데, 트랜잭션 속성은 AnnotationTransactionAttributeSource 라는 클래스에게 요청하면, 해당 클래스에서 @Transactional 에 입력된 속성을 읽어온다.
3.3. 어드바이저
이 포인트컷과 어드바이스를 갖고 있는 어드바이저는 BeanFactoryTransactionAttributeSourceAdvisor 로 어플리케이션 실행 시 자동으로 빈으로 등록된다.
4. @Transactional 선언만 해줬을 뿐인데!!
정리하면, @Transactional 선언만 해주면 아래와 같은 매커니즘에 따라 동작하게 된다.
1) 어플리케이션 시작 시 TransactionAttributeSourcePointcut 포인트컷과 TransactionInterceptor 어드바이스를 갖는 BeanFactoryTransactionAttributeSourceAdvisor어드바이저가 빈으로 등록된다.
2) 빈 후처리기가 트랜잭션 기능을 부여하는 어드바이저 빈을 조회한다.
3) 어드바이저의 포인트 컷을 통해 @Transactional이 붙은 Bean 을 선정하고 프록시로 생성한다.
4. 생성한 프록시에 어드바이저를 연결한다.
5. 완성된 프록시를 스프링 컨테이너에게 전달한다.
6. 스프링 컨테이너는 전달받은 프록시를 빈으로 등록하고 사용한다.
7. 추후 해당 프록시 빈이 호출될 경우 트랜잭션 속성에 따른 트랜잭션 부가기능이 수행된다.
restdocs를 사용하여 JUnit 테스트 코드에서 REST API에 대한 명세 파일을 생성 도중 특정 케이스에서만 Form parameters with the following names were not documented: [_csrf] 에러가 발생하였다.
_csrf 에 대한 SnippetException
2. 오류내용
_csrf 라는 이름을 가진 매개변수가 formParameters에 정의되지 않았고, 최종적으로 문서화 되지않았다는 오류였다. 즉, 요청 파라미터에는 _csrf 값이 있는데, formParameters에는 정의하지 않아 발생했다.
테스트의 HttpServletRequest 정보
3. 코드
@Test
@TestMemberAuth
@DisplayName("운동 상태정보 수정")
void updateExecStatusToW() throws Exception{
mockMvc.perform(
patch("/api/member/exec-status")
.header("Authorization", "Bearer JWT_ACCESS_TOKEN")
.param("status", ExecStatus.W.name())
.with(csrf()))
.andExpect(status().isNoContent())
.andDo(document(
"updateExecStatus"
, requestHeaders(
headerWithName("Authorization").description("JWT_ACCESS_TOKEN"))
, formParameters(
parameterWithName("status").description("헬스 상태 (W : 준비중, H : 헬스중, I : 부상으로 쉬는중"))
)
);
}
* with(csrf()) 구문이 포함되어 있는 이유
with(csrf()) 는 MockHttpServletRequest에 CSRF 토큰 값을 추가하는 메서드이다. SpringSecurity 옵션을 통해 csrf 토큰 사용을 disable 처리했는데, mockMvc를 사용할 경우 기본적으로 csrf 토큰이 사용되도록 동작하기 때문이다. 이를 해결하기 위해 해당 구문을 사용하고 있었다.
5. 원인 분석
5.1. [ formParameters() + _csrf ] 케이스 예외 발생
예외가 발생하는 케이스는 Paramters에 _csrf 값이 들어가고, form 으로 전송되는 Parameters 에 대한 문서화 메서드인formParameters() 를 사용하는 케이스였다. Paramters에 _csrf가 들어가고 있는데 formParameters에는 이에 대한 명세를 하지 않았기 때문에 발생했다.
반대로 Json 형태의 요청 값을 문서화 시킬 경우 requestFields() 메서드를 사용하는데 이는 Parameters가 아닌 Body에 있는 값을 기준으로 매핑하기 때문에 _csrf 관련 에러가 발생하지 않았던 것이다.
application/form 타입의 요청에 대한 MockHttpServletRequest 정보application.json 타입의 요청에 대한 MockHttpServletRequest 정보
6. 해결
6.1. csrf 토큰을 헤더로!
알려진 해결방안은 테스트 전용 SecurityConfig 설정 파일을 만들어서 csrf에 대해 disable 처리하고, MockMvc 테스트 마다 생성한 설정파일을 Configuration 파일로 로드하는 코드를 추가하면 된다고 하는데, _csrf 값을 요청 파라미터가아닌 헤더로 받으면 되지 않을까라는 생각이 들었다.
클라이언트에서 CSRF 토큰 값을 서버로 전송하는 방법은 요청 헤더에 토큰 값을 넣거나요청 파라미터에 토큰 값을 넣는 것이며, 요청 헤더의 경우 X-CSRF-TOKEN, 요청 파라미터의 경우 _csrf 라는 키 값에 넣으면 된다.
with(csrf())를 사용할 경우 요청 파라미터에 csrf 토큰 값이 포함되어 들어가고 있는데, 이를 요청 헤더로 이동시키면 Paramters의 _csrf 값을 제거될 것이고, 에러도 해결될 것 같았다.
곧장 csrf() 의 내부코드를 보니 아래와 같이 asHeader 값이 true일 경우 토큰 값을 헤더에, 그 외에는 Paramter에 설정하는 것을 확인할 수 있었다. 기본값은 false 였기에 Paramter로 토큰이 전송되고 있었다.
csrf()에 메서드에 대한 csrf 설정 부분
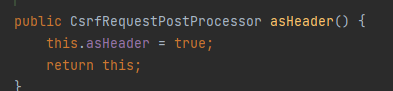
asHeader만 true로 설정해주는 메서드인 asHeader()도 곧바로 찾을 수 있었다. 바로 적용해보았다.
asHeader를 true로 설정하는 asHeader() 메서드
6.2. 적용 및 테스트
기존 csrf() 메서드에 체인 메서드 형태로 asHeader() 메서드만 추가해줬다. 테스트 결과 예외는 해결되었으며, 요청 값을 확인해보면 csrf 토큰 값이 Headers로 요청되는 것을 확인할 수 있다.
@Test
@TestMemberAuth
@DisplayName("운동 상태정보 수정")
void updateExecStatusToW() throws Exception{
mockMvc.perform(
patch("/api/member/exec-status")
.header("Authorization", "Bearer JWT_ACCESS_TOKEN")
.param("status", ExecStatus.W.name())
.with(csrf().asHeader())) // asHeader() 추가
.andExpect(status().isNoContent())
.andDo(document(
"updateExecStatus"
, requestHeaders(
headerWithName("Authorization").description("JWT_ACCESS_TOKEN"))
, formParameters(
parameterWithName("status").description("헬스 상태 (W : 준비중, H : 헬스중, I : 부상으로 쉬는중"))
)
);
}
예외 메시지를 보니 DTO 객체를 직렬화하는 과정에서 필드에 존재하는 `java.time.LocalDateTime` 의 데이터 타입을 지원되지 않아 처리할 수 없다는 오류였다.
3.1. 갑자기 웬 직렬화?
@RestController 또는 @ResponseBody 어노테이션을 사용할 경우 리턴 값이 Json 스트링 형식으로 변환되어 응답되는데, 이때 내부 MessageConverter에 정의된 ObjectMapper에 의해 데이터가 직렬화된다. (직렬화 : Object to Json)
반대로 @RequestBody 어노테이션을 사용할 경우 요청 Json 데이터를 Object로 변환하는데, 이때는 역직렬화 기술이 사용된다.
3.2. 잘못잡은 포인트
내부 MessageConverter에서 직렬화 도중 발생한 예외인줄 알았으나, 테스트 코드의 objectMapper를 사용하여 응답 값을 검증하는 부분에서 발생했던 것이었다. ^^;;
private final ObjectMapper objectMapper = new ObjectMapper();
...
@Test
@TestMemberAuth
@DisplayName("채팅방 ID에 대한 채팅내역 조회")
void getChatHistory() throws Exception {
mockMvc.perform(
get("/api/chatting/history/{roomId}",CHATTING_ROOM_ID_FOR_LOGIN_MEMBER_AND_VALID_MEMBER))
.andExpect(status().isOk())
.andExpect(content().string(objectMapper.writeValueAsString(CHATTING_HISTORY_DTO))); // 예외발생 부분
}
4. 해결
테스트 코드에서 objectMapper를 생성한 이후 아래 설정을 추가하였다.
objectMapper = new ObjectMapper();
objectMapper.registerModule(new JavaTimeModule());
objectMapper.configure(SerializationFeature.WRITE_DATES_AS_TIMESTAMPS, false);
위 설정은 ObjectMapper에 JavaTimeMoule을 등록한 후, 날짜와 시간을 타임스탬프로 직렬화하지 않도록 한다.
참고로 예외 메시지에서 jackson-datatype-jsr310 의존을 추가하라고 하는데, spring-boot-starter-web 에 의존하는 경우 종속관계인 jackson-datatype-jsr310 도 자동 의존하는 것을 확인할 수 있었다.
AOP는 말 그대로 Aspect(관점) Oriented(지향) Programming(프로그래밍). 관점 지향적인 프로그래밍이다. 풀어 말하면 어떤 로직에 대해 핵심 기능과 부가 기능이라는 관점으로 나누어 모듈화하는 프로그래밍 기법을 말한다. 토비의 스프링에도 비슷하게 정의되어 있어 가져와봤다.
AOP란 어플리케이션의 핵심적인 기능에서 부가적인 기능을 분리해서 애스펙트라는 독특한 모듈로 만들어서 설계하고 개발하는 방법이다.
예를들어 @Transactional을 사용하지 않고 DB 데이터 처리를 하는 특정 메서드에 대한 트랜잭션 기능을 부여한다면, 아래와 같은 코드를 구현할 수 있다.
public void upgradeLevels() {
TransactionStatus status = transactionManager.getTransaction(
new DefaultTransactionDefinition()
);
try{
userService.upgradeLevels(); // 핵심기능
transactionManager.commit(status);
}catch(Exception e){
transactionManager.rollback(status);
}
}
현재는 upgradeLevels() 메서드에 대해서만 트랜잭션을 적용하였으나 다른 메서드에도 적용해야한다면 아래와 같이 많은 중복코드가 생길것이다.
public void upgradeLevels() {
TransactionStatus status = transactionManager.getTransaction(
new DefaultTransactionDefinition()
);
try{
userService.upgradeLevels();
transactionManager.commit(status);
}catch(Exception e){
transactionManager.rollback(status);
}
}
public void saveUserInfo() {
TransactionStatus status = transactionManager.getTransaction(
new DefaultTransactionDefinition()
);
try{
userService.saveUserInfo();
transactionManager.commit(status);
}catch(Exception e){
transactionManager.rollback(status);
}
}
...
public void update() {
TransactionStatus status = transactionManager.getTransaction(
new DefaultTransactionDefinition()
);
try{
userService.update();
transactionManager.commit(status);
}catch(Exception e){
transactionManager.rollback(status);
}
}
...
중복을 없애려면 어떻게 해야할까? 중복되는 트랜잭션 로직을 분리하고, 다른 클래스에서도 재사용할 수 있도록 모듈화 해야한다. 이 말은 UserService의 메서드와 트랜잭션 로직을 각각 핵심기능과 부가기능으로 분리하고, 부가기능을 모듈화 해야 한다는 것인데. 이렇게 접근하는 프로그래밍 방식이 AOP, 관점 지향 프로그래밍이라고 할 수 있다.
2.2. AOP 용어
AOP 사용 시 자주 사용되는 용어들이 있다. 이 중에서도 스프링 AOP에서 주로 사용되는 Advice, Pointcut, Advisor는 꼭 숙지하자.
Target
부가 기능을 부여할 대상이다. 핵심기능을 담은 클래스일 수도 있지만 경우에 따라 다른 부가기능을 제공하는 프록시 오브젝트일 수도 있다.
Advice
타겟에게 제공할 부가 기능을 담은 모듈이다. 어드바이스는 오브젝트로 정의하기도 하지만 메서드 레벨에서 정의할 수도 있다
JoinPoint
어드바이스가 적용될 수 있는 위치를 말한다. 스프링 AOP에서 조인포인트는 메서드의 실행단계 뿐이다. 타깃 오브젝트가 구현한 인터페이스의 모든 메서드는 조인 포인트가 된다.
Pointcut
어드바이스를 적용할 조인 포인트를 선별하는 작업 또는 그 기능을 정의한 모듈을 말한다. 스프링 AOP의 조인포인트는 메서드의 실행이므로 스프링의 포인트컷은 메서드를 선정하는 기능을 갖고 있다. 그래서 포인트컷 표현식에서도 메서드의 시그니처를 비교하는 방법을 주로 사용한다. 메서드는 클래스 안에 존재하는 것이기 때문에 메서드 선정이란 결국 클래스를 선정하고 그 안의 메서드를 선정하는 과정을 거치게 된다.
Advisor
어드바이저와 포인트컷을 하나씩 갖고 있는 오브젝트이다. 어드바이저는 어떤 기능(어드바이스)을 어디에(포인트컷) 전달할 것인가를 알고 있는 AOP의 가장 기본이 되는 모듈이다. 어드바이저는 스프링 AOP에서만 사용되는 용어이고, 일반적인 AOP에서는 사용되지 않는다.
예를 들어서 살펴보면 좀 더 쉬운데요. MemberService의 hello()라는 메소드 실행 전,후에 hello랑 bye를 출력하는 일을 한다고 가정해보죠. 이때 MemberService 빈이 타겟, "hello() 메소드 실행 전,후"가 포인트컷, "메소드 실행 전,후"라는게 조인포인트, "hello랑 bye를 출력하는 일"이 Advice입니다. 포인트컷과 조인포인트가 많이 햇갈릴텐데 조인포인트가 메타적인 정보라고 생각하시면 되고 포인트컷이 좀 더 구체적인 적용 지점이라고 생각하시면 됩니다.
- 인프런 문의사항 답변 내용 (답변자 : 백기선님)
3. 빈 후처리기를 통한 AOP
스프링에서는 AOP를 위한 다양한 모듈을 제공한다. 일단 빈 후처리기를 활용하여 AOP를 적용해보도록 하겠다.
3.1. 빈 후처리기가 뭔가요?
BeanPostProcessor 인터페이스를 구현한 클래스로 빈을 생성한 후 후처리 기능을 하는 클래스이다.
스프링의 대표적인 빈 후처리기는 DefaultAdvisorAutoProxyCreator로 등록된 빈 중에서 Advisor 인터페이스를 구현한 클래스에 대한 자동 프록시 생성 후처리기이다.
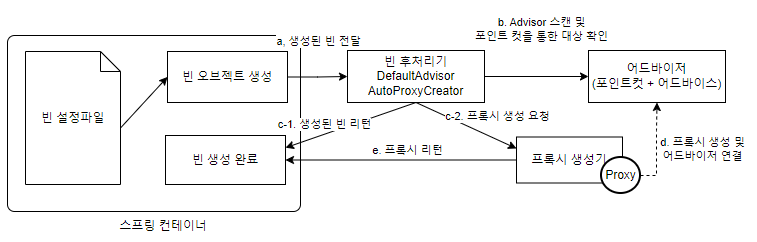
이를 활용하면 스프링이 생성하는 빈 오브젝트 중 일부를 프록시로 포장하고, 프록시를 빈으로 대신 등록할 수도 있다. 그림과 함께 동작과정을 이해해보자.
3.2. DefaultAdvisorAutoProxyCreator 동작과정
DefaultAdvisorAutoProxyCreator 동작과정
1) 어플리케이션이 시작되면 빈 설정파일을 읽어 빈 오브젝트를 생성한다.
2) BeanPostProcessor 인터페이스를 구현한 클래스(DefaultAdvisorAutoProxyCreator)가 빈으로 등록되어 있다면 생성된 빈을 여기로 전달한다.
3) DefaultAdvisorAutoProxyCreator는 생성된 빈 중에서 Advisor 인터페이스를 구현한 클래스가 있는지 스캔한다.
4) Advisor 인터페이스를 구현한 클래스가 있다면 Advisor의 포인트 컷을 통해 프록시를 적용할지 선별한다.
5) Advisor가 없거나 포인트 컷 선별이 되지 않았다면 전달받은 빈을 그대로 스프링 컨테이너에게 전달하고, 선별됐다면 프록시 생성기 역할을 하는 객체에서 프록시 생성 요청을 한다.
6) 프록시 생성기는 프록시를 생성하고 프록시에 어드바이저를 연결한다.
7) 완성된 프록시를 스프링 컨테이너에게 전달한다.
8) 스프링 컨테이너는 빈 후처리기가 돌려준 오브젝트를 빈으로 등록하고 사용한다.
3.3. DefaultAdvisorAutoProxyCreator 예제
UserService 인터페이스에 대한 구현체 클래스는 UserServiceImpl은 DB 데이터 처리를 하는 IUserDao와 비지니스 로직을 담당하는 UserLevelUpgradePolicy를 DI받는다.
UserServiceImpl 메서드 실행 도중 예외가 발생할 경우 모든 트랜잭션을 rollback하기 위해 트랜잭션 처리를 하는 부가기능을 빈 후처리기를 통해 구현해보도록 하자. 매커니즘을 이해하는 것에 초점을 맞췄기 때문에 부가적인 코드는 첨부하지 않도록 하겠다.
1) UserService
public interface UserService {
void upgradeLevels();
void add(User user);
}
2) UserServiceImpl
public class UserServiceImpl implements UserService {
private IUserDao userDao;
private UserLevelUpgradePolicy userLevelUpgradePolicy;
public void setUserDao(IUserDao userDao){
this.userDao = userDao;
}
public void setUserLevelUpgradePolicy(UserLevelUpgradePolicy userLevelUpgradePolicy){
this.userLevelUpgradePolicy = userLevelUpgradePolicy;
}
public void upgradeLevels() {
List<User> users = userDao.getAll(); // DB /
for(User user : users) {
if (userLevelUpgradePolicy.canUpgradeLevel(user)) {
userLevelUpgradePolicy.upgradeLevel(user);
}
}
}
public void add(User user) {
if(user.getLevel() == null){
user.setLevel(Level.BASIC);
}
userDao.add(user);
}
}
3.3.1. 빈 후처리기 등록
DefaultAdvisorAutoProxyCreator를 빈으로 등록하면 된다. xml 설정을 통해 빈을 등록하였다.
<bean class ="org.springframework.aop.framework.autoproxy.DefaultAdvisorAutoProxyCreator"></bean>
3.3.2. 포인트컷 정의
DefaultAdvisorAutoProxyCreator는 등록된 빈 중에서 Advisor 인터페이스를 구현한 클래스를 모두 찾는다. 구현 클래스를 생성하기 전, Advisor에 필요한 포인트컷과 어드바이스를 준비해야 한다. 먼저 포인트컷을 생성하였다.
public class NameMatchClassMethodPointcut extends NameMatchMethodPointcut {
public void setMappedClassName(String mappedClassName){
this.setClassFilter(new SimpleClassFilter(mappedClassName));
}
static class SimpleClassFilter implements ClassFilter {
String mappedName;
private SimpleClassFilter(String mappedName){
this.mappedName = mappedName;
}
public boolean matches(Class<?> clazz){
return PatternMatchUtils.simpleMatch(mappedName,
clazz.getSimpleName());
}
}
}
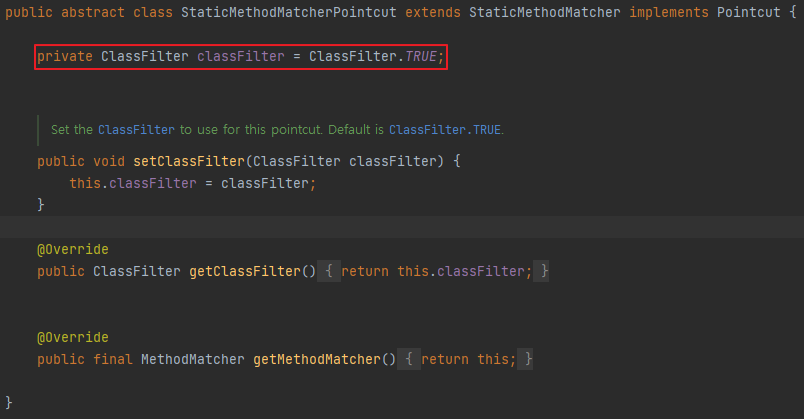
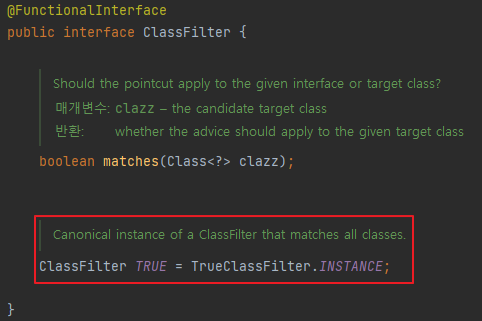
포인트컷은 NameCatchMethodPointcut을 내부 익명 클래스 방식으로 확장해서 만들었다. 이름에서 알 수 있듯이 메서드 선별 기능을 가진 포인트컷인데, 클래스에 대해서는 필터링 기능이 없는게 아닌 모든 클래스를 다 허용한는 기본 클래스 필터가 적용되어 있다. 때문이 이 클래스 필터를 재정의 하였다.
StaticMethodMatcherPointcut 의 기본 classFilterTrueClassFilter.INSTANCE
Canonical instance of a ClassFilter that matches all classes : 모든 클래스와 일치하는 ClassFilter의 정식 인스턴스
주석을 보면 알 수 있듯이 기본 클래스 필터인 TrueClassFilter.INSTANCE는 모든 클래스와 일치시킨다.
3.3.3. 어드바이스 정의
이제 부가기능을 포함하는 어드바이스를 정의해보겠다. MethodInterceptor 인터페이스를 구현하면 된다. invoke 메서드에 부가기능 및 타겟 오브젝트 호출 로직을 넣어준다.
public class TransactionAdvice implements MethodInterceptor {
private PlatformTransactionManager transactionManager;
public void setTransactionManager(PlatformTransactionManager transactionManager){
this.transactionManager = transactionManager;
}
@Override
public Object invoke(MethodInvocation invocation) throws Throwable {
TransactionStatus status = transactionManager
.getTransaction(new DefaultTransactionDefinition());
try{
Object ret = invocation.proceed(); //타겟 메서드 실행
transactionManager.commit(status);
return ret;
} catch (RuntimeException e){
transactionManager.rollback(status);
throw e;
}
}
}
3.3.4. 어드바이저 등록
어드바이저는 스프링에서 제공하는 DefaultPointcutAdvisor를 사용한다.
앞서 DefaultAdvisorAutoProxyCreator는 등록된 빈 중에서 Advisor 인터페이스를 구현한 클래스를 모두 찾는다고 했는데 DefaultPointcutAdvisor 클래스가 Advisor 인터페이스의 구현체 클래스 중 하나이다.
어드바이저 등록은 'XML을 통한 빈 설정' 부분에 기재하였다.
3.3.5. XML을 통한 빈 설정
이제 작업한 내용을 바탕으로 스프링 빈 설정을 한다. 어드바이저에 대한 자동 프록시 생성 후처리기인 DefaultAdvisorAutoProxyCreator 빈을 등록하고, 스캔할 어드바이저로 DefaultPointcutAdvisor 타입의 transactionAdvisor 빈을 등록한다. 생성 시 필요한 어드바이스와 포인트컷도 마찬가지로 빈으로 등록해줬다.
필자는 클래스 이름의 suffix가 ServiceImpl인 클래스, 메서드 이름의 prefix가 upgrade 인 메서드에 대해 포인트컷을 설정하기 위해 mappedClassName엔 "*ServiceImpl"를, mappedName엔 "upgrade*" 를 설정해주었다.
...
<bean id = "userService" class = "org.example.user.service.UserServiceImpl">
<property name="userDao" ref = "userDao"></property>
<property name="userLevelUpgradePolicy" ref = "defaultUserLevelUpgradePolicy"></property>
</bean>
...
<!-- 빈 후처리기 등록 -->
<bean class ="org.springframework.aop.framework.autoproxy.DefaultAdvisorAutoProxyCreator"/>
<!-- 어드바이스 설정 -->
<bean id = "transactionAdvice" class = "org.example.proxy.TransactionAdvice">
<property name="transactionManager" ref = "transactionManager"></property>
</bean>
<!-- 포인트컷 설정 -->
<bean id = "transactionPointcut" class = "org.example.proxy.NameMatchClassMethodPointcut">
<property name="mappedClassName" value = "*ServiceImpl"/>
<property name="mappedName" value = "upgrade*"/>
</bean>
<!-- 어드바이저 (어드바이스 + 포인트컷) 설정 -->
<bean id = "transactionAdvisor" class = "org.springframework.aop.support.DefaultPointcutAdvisor">
<property name="advice" ref = "transactionAdvice"></property>
<property name="pointcut" ref ="transactionPointcut"></property>
</bean>
...
3.3.6. 테스트
게시글에 누락시킨 클래스들이 많아 테스트 케이스를 이해하기 힘든 관계로 간단히 설명하자면, 모든 유저들에 대해 정해진 조건을 만족할 경우 다음 레벨로 업그레이드하는 UserService의 upgradeLevels()를 메서드를 테스트하며, 메서드 실행 도중 예외발생 시 트랜잭션이 적용되는지 확인하기 위함이다.
테스트를 위해 upgradeLevels 내부에서 실행되는 UserLevelUpgradePolicy의 upgradeLevel() 메서드에 대해 예외가 발생하도록 Stubbing 처리하였다.
test2 유저의 경우 SIVER로 업그레이드 됐었으나, 커밋 전 예외 발생으로 인해 BASIC 레벨로 롤백되는지 확인하는 케이스를 진행하였고, 트랜잭션이 적용되어 테스트가 성공함을 확인하였다.
public class UserServiceTest {
@Autowired
private UserService userService;
@SpyBean
private IUserDao userDao;
@SpyBean
private DefaultUserLevelUpgradePolicy userLevelUpgradePolicy;
private final List<User> users = Arrays.asList(
new User("test1","테스터1","pw1", Level.BASIC, 49, 0, "tlatmsrud@naver.com"),
new User("test2","테스터2","pw2", Level.BASIC, 50, 0, "tlatmsrud@naver.com"),
new User("test3","테스터3","pw3", Level.SILVER, 60, 29, "tlatmsrud@naver.com"),
new User("test4","테스터4","pw4", Level.SILVER, 60, 30, "tlatmsrud@naver.com"),
new User("test5","테스터5","pw5", Level.GOLD, 100, 100, "tlatmsrud@naver.com")
);
@BeforeEach
void setUp(){
// 모든 유저 조회 시 미리 정의한 유저 텍스처 조회
given(userDao.getAll()).willReturn(users);
// 4번째 유저에 대한 업그레이드 메서드 실행 시 예외 발생
willThrow(new RuntimeException()).given(userLevelUpgradePolicy).upgradeLevel(users.get(3));
}
@Test
void upgradeAllOrNothing(){
// 테이블 데이터 초기화
userDao.deleteAll();
// 테이블에 유저 정보 insert
users.forEach(user -> userDao.add(user));
// 유저 레벨 업그레이드 메서드 실행 및 예외 발생 여부 확인 (setUp 메서드에 4번째 유저 업그레이드 처리 시 예외 발생하도록 스터빙 추가)
assertThatThrownBy(() -> userService.upgradeLevels())
.isInstanceOf(RuntimeException.class);
// DB
assertThat(userDao.get("test1").getLevel()).isEqualTo(Level.BASIC);
assertThat(userDao.get("test2").getLevel()).isEqualTo(Level.BASIC);
assertThat(userDao.get("test3").getLevel()).isEqualTo(Level.SILVER);
assertThat(userDao.get("test4").getLevel()).isEqualTo(Level.SILVER);
assertThat(userDao.get("test5").getLevel()).isEqualTo(Level.GOLD);
System.out.println(userService.getClass().getName()); //com.sun.proxy.$Proxy50
}
}
추가적으로 Autowired한 userService의 클래스 타입은 자동 프록시 생성 빈 후처리기에 의해 Proxy 객체가 생성된 관계로 UserServiceImpl가 아닌 Proxy임을 확인할 수 있었다.
포인트컷과 일치하여 생성된 프록시 빈
만약 포인트컷에 선별되지 않도록 mappedName 혹은 mappedClassName을 변경한다면 프록시를 생성하지 않고 아래와 같이 UserServiceImpl 타입으로 출력되는 것도 확인할 수 있었다.
포인트컷과 일치하지 않아 그대로 리턴된 빈
4. 세밀한 포인트컷
4.1. 리플렉션 API 활용?!
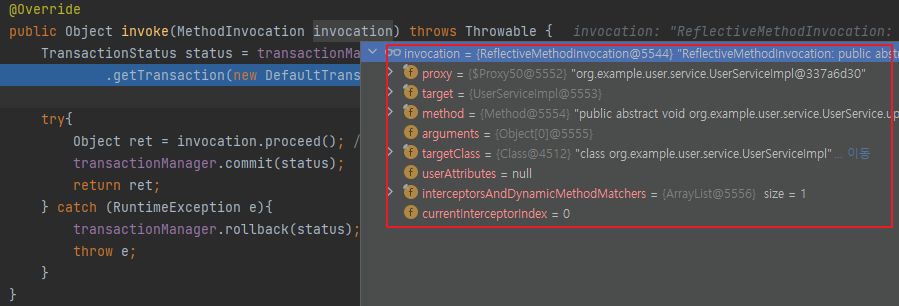
예제에서는 단순히 클래스나 메서드의 이름으로만 포인트컷을 지정했는데, 더 세밀하고 복잡한 기준을 적용해 포인트컷을 지정할 수도 있다. 바로 리플렉션 API를 활용하는 것이다. 어차피 TransactionAdvice의 invoke 메서드 파라미터인 MethodInvocation도 리플렉션이 적용된 파라미터이기 때문에 메서드나 클래스, 리턴 값 등 대부분의 정보를 얻을 수 있기 때문이다.
invoke 메서드의 invocation 파라미터
하지만 리플렉션 API를 사용하면 코드가 지저분해지고 포인트컷 비교 정보가 달라질때마다 해당 로직을 수정해야한다. 이에 스프링은 표현식을 통해 간단하게 포인트컷의 클래스와 메서드를 선별할 수 있도록 하는 방법을 제공하는데 이를 포인트컷 표현식이라고 한다.
4.2. 포인트컷 표현식
포인트컷 표현식을 지원하는 포인트컷을 적용하려면 포인트컷 빈으로 AspectExpressionPointcut 클래스를 사용하면 된다.
4.3. 포인트컷 표현식 문법
포인트컷 표현식은 포인트컷 지시자를 이용하여 작성하며 대표적으로 execution()이 있다. 메서드의 풀 시그니처를 문자열로 비교하는 개념이며, 문법은 아래와 같다. 참고로 괄호([ ])안은 생략 가능하다.
포인트컷 표현식
예를들어 execution("* org.test.service.*ServiceImpl.upgrade*(..)) 는 모든 접근제한자 및 리턴타입을 갖고, ServiceImpl로 끝나는 클래스 명을 갖고, 메서드명이 upgrade로 시작하는 모든 메서드 시그니처를 의미한다.
4.4. AspectExpressionPointcut 적용해보기
포인트컷 표현식 사용을 위한 의존성을 추가하고, xml에 설정했던 포인트컷 빈을 수정해보자.
1) 의존성 추가
implementation 'org.aspectj:aspectjtools:1.9.19'
2) xml 설정 변경
<bean id = "transactionPointcut" class = "org.springframework.aop.aspectj.AspectJExpressionPointcut">
<property name="expression" value = "execution(* org.example.user.service.*ServiceImpl.upgrade*(..))"/>
</bean>
기존엔 포인트컷에 대한 클래스를 생성해주었지만, AspectJExpressionPointcut을 사용하니 그럴 필요가 없게 되었다. 테스트 코드를 실행해보면 테스트가 성공하는 것을 확인할 수 있다.
4.5. 스프링 AOP 정리
스프링의 AOP를 적용하려면 최소한 네 가지 빈을 등록해야 한다.
* 자동 프록시 생성기
스프링의 DefaultAdvisorAutoProxyCreator 클래스를 빈으로 등록한다. 빈으로 등록된 어드바이저를 이용해서 프록시를 자동으로 생성하는 기능을 담당한다.
* 어드바이스
부가기능을 구현할 클래스를 빈으로 등록한다. TransactionAdvice는 AOP 관련 빈 중 유일하게 직접 구현한 클래스이다.
* 포인트컷
스프링의 AspectJExpressionPointcut을 빈으로 등록하고 포인트컷 표현식을 넣어주면 된다.
* 어드바이저
스프링의 DefaultPointcutAdvisor를 빈으로 등록한다. 어드바이스와 포인트컷을 참조하는 것 외에는 기능이 없다. 자동 프록시 생성기에 의해 검색되어 사용된다.
5. AOP 네임스페이스
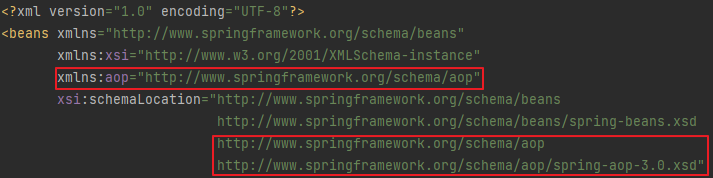
포인트컷 표현식을 사용하니 어드바이스를 제외하고는 모두 스프링에서 제공하는 클래스를 사용하고 있다. 스프링에서는 이렇게 AOP를 위해 기계적으로 적용해야하는 빈들을 간편하게 등록하는 방법을 제공한다. 바로 aop 스키마를 이용하는 것이다.
aop 스키마를 사용하려면 bean xml 설정파일에 aop 네임 스페이스 선언을 추가해줘야 한다.
aop 네임스페이스 추가
이를 추가하면 빈 후처리기, 포인트컷, 어드바이저가 자동으로 등록되므로 xml 설정에서 제거할 수 있다. 이제 aop 네임 스페이스를 사용하여 bean 설정 xml을 아래와 같이 작성할 수 있다. 단위 테스트를 통해 트랜잭션이 적용됨을 확인할 수 있었다.
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:aop="http://www.springframework.org/schema/aop"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/aop
http://www.springframework.org/schema/aop/spring-aop-3.0.xsd"
>
...
<!-- 빈 후처리기, 포인트컷, 어드바이저 빈 생성 코드 제거
<bean class ="org.springframework.aop.framework.autoproxy.DefaultAdvisorAutoProxyCreator"/>
<bean id = "transactionPointcut" class = "org.example.proxy.NameMatchClassMethodPointcut">
<property name="mappedClassName" value = "*ServiceImpl"/>
<property name="mappedName" value = "upgrade*"/>
</bean>
<bean id = "transactionAdvisor" class = "org.springframework.aop.support.DefaultPointcutAdvisor">
<property name="advice" ref = "transactionAdvice"></property>
<property name="pointcut" ref ="transactionPointcut"></property>
</bean>
-->
<bean id = "transactionAdvice" class = "org.example.proxy.TransactionAdvice">
<property name="transactionManager" ref = "transactionManager"></property>
</bean>
<aop:config>
<aop:advisor advice-ref="transactionAdvice"
pointcut="execution(* org.example.user.service.*ServiceImpl.upgrade*(..))"></aop:advisor>
</aop:config>
</beans>