1. 개요
- 토비의 스프링 책에 나온 계산기 예제 코드에 대해 템플릿/콜백 패턴을 적용한다.
- 패턴을 도출해내는 과정을 이해하기 위함이다.
2. 템플릿/콜백 패턴이란?
- 전략 패턴에 사용되는 인터페이스 구현체 클래스 대신 익명 내부 클래스가 사용되는 패턴이다. (전략패턴 + 익명 내부 클래스)
- 코드 내에 고정된 부분(템플릿)과 변경되는 부분이 있을 때 고정된 부분은 클래스 또는 메서드로 분리하여 템플릿 역할을 갖게하고, 변경되는 부분은 콜백(익명 클래스의 메서드)으로 처리한다.
- 콜백으로 처리하는 이유는 변경되는 부분이 여러 클래스에서 재사용되는게 아닌 특정 클래스의 메서드 내에서 한번만 사용되기 때문이다. 만약, 여러 클래스에서 사용된다면 템플릿/콜백 메서드보다는 전략 패턴을 사용하는게 더 유리하다.
3. 템플릿/콜백 패턴 적용
3.1. 예제코드
public class Calculator{
public Integer calcSum(String path) throws IOException {
BufferedReader br = new BufferedReader(new FileReader(path));
Integer sum = 0;
String line = null;
while((line = br.readLine()) != null){
sum += Integer.valueOf(line);
}
br.close();
return sum;
}
}- path 경로에 있는 txt 파일을 읽어 각 라인에 적혀있는 숫자들을 연산하는 예제이다.
3.2. 코드 분석 및 템플릿 설계
- 코드를 분석하여 어떤 전략을 사용해 템플릿을 설계할지 생각해본다. 일단 예제의 목적 자체가 템플릿/콜백 패턴 구현이므로 이에 초점을 맞추었다. 현재 'calcSum' 이라는 더하기 연산 처리 메서드만 있지만 곱하기, 나누기, 빼기의 메서드가 추가된다고 가정하고 분석하였다.
아래 사항들을 생각하며 분석하였다.
1) 공통부분과 바뀌는 부분이 있는지
2) 공통부분은 어떤 레벨로 분리할지
3) 바뀌는 부분은 타 클래스 혹은 메서드에서 재사용할 가능성이 있는지
3.3. 분석결과
3.3.1. 공통부분
- path에 대한 BufferedReader를 생성하는 부분
- 반복문을 통해 BufferedReader에서 라인을 읽는 부분
- BufferedReader를 close 하는 부분 (+ try, catch, finally 로 처리)
3.3.2. 바뀌는 부분
- 값을 연산하는 부분
3.3.3. 정리
- 공통 부분은 BufferedReader의 생명주기와 관련있고, Integer형태의 결과값을 리턴하는 부분이므로 다른 클래스에서도 충분히 재사용할 수 있다고 판단. 클래스로 분리한다.
- 더하기, 빼기, 곱하기, 나누기 연산은 메서드마다 유연하게 바뀌어야 하므로 템플릿/메서드 패턴보다는 전략패턴을 고려하였으나, 각 연산 처리는 다른 클래스에서 재사용되지 않고, Calculator 클래스에 생성될 메서드에 한번만 사용될 것이기 때문에 일회성 성격을 지닌 내부 익명 클래스로 구현한다. 익명 클래스는 콜백 오브젝트 역할을 수행할 것이며, 이를 통해 템플릿/콜백 패턴을 적용한다.
3.4. 1차 코드수정
3.4.1. Calculator2.java
public class Calculator2 {
// 공통 부분을 구현한 Template 클래스
private BufferedReaderTemplate bufferedReaderTemplate;
// 외부로부터 DI받기위한 수정자 메서드
public void setBufferedReaderTemplate(BufferedReaderTemplate bufferedReaderTemplate){
this.bufferedReaderTemplate = bufferedReaderTemplate;
}
// 더하기 메서드
public Integer calcSum(String path) throws IOException {
// Template의 withCalculatorCallback 를 호출 시 CalculatorCallback에 대한 내부 익명클래스 구현 및 전달
return bufferedReaderTemplate.withCalculatorCallback(path, new CalculatorCallback() {
@Override
public Integer calculate(String line, Integer value) {
return value + Integer.valueOf(line);
}
});
}
// 곱하기 메서드
public Integer calcMultiply(String path) throws IOException {
// Template의 withCalculatorCallback 를 호출 시 람다식을 활용하여 내부 익명클래스 구현 및 전달
return bufferedReaderTemplate.withCalculatorCallback(path, (line, value) -> value * Integer.valueOf(line));
}
}- 여러 클래스에서 공통으로 사용될 여지가 있는 BufferedReaderTemplate은 외부(ObjFactory.java)로부터 DI 받는다.
- 메서드 호출 시 템플릿/콜백 패턴이 적용된 bufferedReaderTemplate.withCalculatorCallback() 메서드를 호출하며, 이때 두번째 파라미터인 CalculatorCallback() 인터페이스에 대한 구현체를 내부 익명클래스로 구현한다.
- 곱하기 메서드는 람다식을 사용하여 간단하게 구현했다. 사실상 더하기 메서드와 동일하다.
3.4.2. BufferedReaderTemplate.java
public class BufferedReaderTemplate {
// CalculatorCallback을 함께 받는 메서드 정의
public Integer withCalculatorCallback(String path, CalculatorCallback callback) throws IOException {
BufferedReader br = null ;
try{
br = new BufferedReader(new FileReader(path));
String line;
Integer res = 0;
while((line = br.readLine()) != null) {
res = callback.call(line, res); // 콜백 오프젝트의 call 메서드 호출
}
return res;
}catch(FileNotFoundException e){
e.printStackTrace();
throw e;
}finally {
if(br != null){
br.close();
}
}
}
}- CalculatorCallback 구현체를 파라미터로 받는 withCalculatorCallback 메서드를 구현하였다. 만약 계산기가 아닌 다른 목적으로 이 클래스를 사용한다면 그에 맞게 메서드를 만들수 있으므로 확장성이 보장된다.
- 중간 부분에 callback.call(line,res); 구문을 통해 콜백 오프젝트의 call 메서드를 호출하여 연산 처리가 되도록 하였다.
3.4.3. CalculatorCallback.java
public interface CalculatorCallback {
public Integer call(String line, Integer value);
}- 템플릿에 사용될 콜백 오브젝트를 정의하였다. 목적은 파라미터로 들어온 line의 값과 value 의 값을 목적에 맞게 연산하기 위함이다.
3.4.4. ObjFactory.java
@Configuration
public class ObjFactory {
@Bean
public Calculator2 calculator2(){
Calculator2 calculator2 = new Calculator2();
calculator2.setBufferedReaderTemplate(bufferedReaderTemplate());
return calculator2;
}
@Bean
public BufferedReaderTemplate bufferedReaderTemplate(){
return new BufferedReaderTemplate();
}
}- DI 처리를 위한 Factory 클래스이다. BufferedReaderTemplate Bean을 만들고 Calculator2에 DI 하고있다.
3.5. 1차 테스트
- Junit 코드 작성 후 테스트를 진행하였다. DI 정보는 ApplicationContext에서 읽어와 멤버필드에 넣어주었다.
- numbers.txt 파일은 test 패키지의 resource 경로에 넣어두고, getResource().getPath() 메서드를 통해 파일 경로를 읽어 멤버필드에 넣어주었다.
- numbers.txt 파일 내용은 아래와 같다.
number.txt
1
2
3
4
5
3.5.1. 테스트 코드
public class PracticeCalculatorTest {
private Calculator2 calculator;
private String filePath;
@BeforeEach
void setUp(){
ApplicationContext applicationContext = new AnnotationConfigApplicationContext(ObjFactory.class);
this.calculator = applicationContext.getBean("calculator2", Calculator2.class);
this.filePath = getClass().getResource("/numbers.txt").getPath();
}
@Test
public void sumOfNumbers() throws IOException {
int sum = calculator.calcSum(filePath);
assertThat(sum).isEqualTo(15);
}
@Test
public void multiplyOfNumbers() throws IOException {
int sum = calculator.calcMultiply(filePath);
assertThat(sum).isEqualTo(120);
}
}
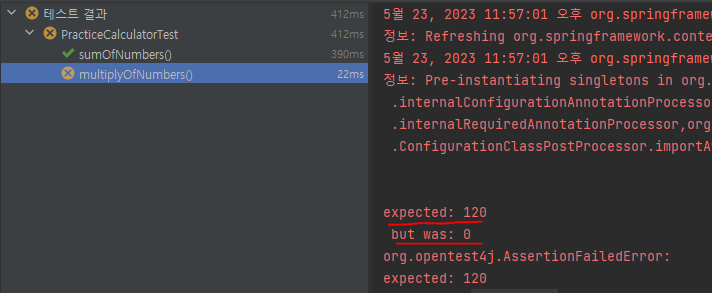
3.5.5. 테스트 결과
- 더하기는 문제가 없으나, 곱하기에서 실패한다. 원인은 템플릿 메서드인 withCalculatorCallback에 있었다. 최초 res 값이 0일 경우 어떤 값을 곱해도 0이 나오기 때문이다. 곱하기일 경우 변하는 값에 최초 res값이 있다는 사실을 놓쳤다.
3.6. 2차 코드수정
- 최초 res 값을 처리할 부분을 생각해보자. 최초 값을 CalculatorCallback의 파라미터로 넣는 방법이 있고, withCalculatorCallback의 파라미터로 넣는 방법이 있다.
- CalculatorCallback는 String 형태로 들어온 line 값과 두번째 파라미터인 현재 결과 값을 연산하는 메서드이다. 만약 이 부분에 최초 응답 값이 있을 경우 분기하는 로직이 들어갈 것으로 예상되기에 withCalculatorCallback 메서드의 파라미터로 넘기는 방법을 선택했다.
3.6.1. Calculator2.java
public class Calculator2 {
private BufferedReaderTemplate bufferedReaderTemplate;
public void setBufferedReaderTemplate(BufferedReaderTemplate bufferedReaderTemplate){
this.bufferedReaderTemplate = bufferedReaderTemplate;
}
public Integer calcSum(String path) throws IOException {
return bufferedReaderTemplate.withCalculatorCallback(path, new CalculatorCallback() {
@Override
public Integer call(String line, Integer value) {
return value + Integer.valueOf(line);
}
},0); // 최초 값인 0 추가
}
public Integer calcMultiply(String path) throws IOException {
// 최초 값인 1 추가
return bufferedReaderTemplate.withCalculatorCallback(path, (line, value) -> value * Integer.valueOf(line),1);
}
}- withCalculatorCallback에 최초 값에 대한 파라미터를 전달하였다. 더하기는 0, 곱하기는 1이다.
3.6.2. BufferedReaderTemplate.java
public class BufferedReaderTemplate {
// initVal 추가
public Integer withCalculatorCallback(String path, CalculatorCallback callback, Integer initVal) throws IOException {
BufferedReader br = null ;
try{
br = new BufferedReader(new FileReader(path));
String line;
Integer res = initVal; // initVal을 res값에 대입
while((line = br.readLine()) != null) {
res = callback.call(line, res);
}
return res;
}catch(FileNotFoundException e){
e.printStackTrace();
throw e;
}finally {
if(br != null){
br.close();
}
}
}
}- 메서드에 대한 시그니처를 수정하고, res = initVal을 넣어 최초 값을 설정해주었다.
3.7. 2차 테스트
3.7.1. 테스트 결과
- 더하기와 곱하기 테스트가 성공함을 확인할 수 있다.

4. 회고
토비의 스프링 3장 템플릿 부분 중 템플릿/콜백 패턴의 사용을 도출해내는 과정이 잘 이해되지 않아 코드 분석 및 적용 패턴 도출 과정을 근거와 함께 생각해보며 구현해보았다. 패턴 적용이 완료된 코드를 한번 작성해본터라 그 코드를 따라가는 느낌도 없지않아 있었지만, 코드를 분석하고, 패턴을 사용하는 근거를 생각하는 과정을 통해 템플릿/패턴을 사용하는 이유를 보다 잘 이해하게 되었다.
스프링에서 제공하는 많은 클래스들은 이러한 패턴들의 조합으로 이루어져있다고 한다. 여러 패턴들을 소비해보고 그 원리를 이해하려고 노력하는 게 스프링을 제대로 사용하는 것이 아닐까라는 생각이 문뜩 드는 하루였다. ㅎㅎ

'백엔드 > JAVA' 카테고리의 다른 글
| [Java] @Transactional 너 누구야 / 전파속성 / 동작과정 (2) | 2023.08.02 |
|---|---|
| [JAVA] Reflection / 개념 / 예제 / 단점 / DI 프레임워크 구현 (3) | 2023.07.18 |
| [Java] JWT 개념 정리 (0) | 2023.03.20 |
| [Java] WHOIS OpenAPI를 사용한 해외 IP 차단 기능 구현 (2) (2) | 2022.02.18 |
| [Java] WHOIS OpenAPI를 사용한 해외 IP 차단 기능 구현 (1) (0) | 2022.02.13 |