똑같은 기능의 객체를 매번 사용하기보다는 객체 하나를 재사용하는 편이 낫다. 실제로 Boolean.valueOf() 는 호출할 때마다 객체를 생성하지 않고 내부에 캐싱된 객체를 사용한다.
Boolean.valueOf("true");
우리는 문자열을 초기화할때 매번 new 생성자를 통해 생성하지 않는다. 하나의 String 인스턴스를 사용한다. 이 경우 JVM의 String pool이라는 문자열 풀에서 캐싱하게 되고, 재사용하게 된다.
String a = "abc";
String b = "abc";
System.out.println(a == b); // String Pool에서 조회 : true
String c = new String("abc");
String d = new String("abc");
System.out.println(c == d); // Heap 메모리에 새로 생성된 객체를 조회 : false
들어온 문자열이 로마 숫자인지를 체크하는 메서드이다. 보면 String.matches() 메서드가 호출되는데 내부에서 입력받은 문자열를 통해 Pattern 인스턴스를 생성한다. Pattern은 인스턴스 생성 비용이 높다. 즉, 이 메서드를 호출할 때마다 비용이 비싼 인스턴스를 생성 후 한번만 사용하고 버리는 것이다.
String.matches()Pattern.compile()
이를 개선하기 위해 Pattern 인스턴스를 캐싱해두고 재사용하는 코드로 변경하였다. 책에서는 실제 속도를 비교해보니 개선 전에 비해 6.5 배의 성능 향상을 가져왔다고 한다.
private static final Pattern ROMAN = Pattern.compile("^(?=.)M*(C[MD]|D?C{0,3})(X[CL]|L?X{0,3})(I[XV]|V?I{0,3})$");
static boolean isRomanNumber(String s){
return ROMAN.matcher(s).matches();
}
2.2. 오토박싱 거둬내기
오토박싱은 프리미티브 타입과 레퍼런스 타입을 섞어 쓸때 상호 변환해주는 기술이다. 코드에서 Long 타입의 sum과 long 타입의 i를 연산하는 과정에서 오토박싱이 발생하여 연산 결과를 Long 인스턴스로 생성하게 된다. Integer.MAX_VALUE가 '2의 31승 -1' 이므로, 이 만큼의 Long 인스턴스가 새로 생성되는 것이다. 실행 시간은 6초가 걸렸다.
Long sum = 0L;
long start = System.currentTimeMillis();
for(long i = 0; i <= Integer.MAX_VALUE; i++){
sum += i;
}
System.out.println(sum);
System.out.println(System.currentTimeMillis() - start);
불필요한 Long 인스턴스의 생성을 막으려면 오토박싱을 거둬내면 되며, sum의 타입을 Long에서 long으로 바꿔주면 된다. 수정 후 실행 시간 0.6초가 걸렸다. 오토박싱이 적용된 코드보다 약 10배 빨라졌다.
public static void main(String[] args) {
long sum = 0L; // 수정
long start = System.currentTimeMillis();
for(long i = 0; i <= Integer.MAX_VALUE; i++){
sum += i;
}
System.out.println(sum);
System.out.println(System.currentTimeMillis() - start);
}
3. 혼란을 야기할 수 있는 재사용
객체가 불변이라면 재사용해도 안전하다. 이러한 특성을 살려 자바의 기본 라이브러리에서 많이 활용하고 있는데 만약 개발자가 이런 활용 사실을 인지하지 못할 경우 오히려 혼란을 야기할 수 있다.
3.1. 어댑터
어댑터는 실제 작업은 뒷단 객체에 위임하고, 자신은 제2의 인터페이스 역할을 해주는 객체이다. 예를들어 Map 인터페이스의 keySet 메서드는 Map 안의 키를 전부 담은 어댑터를 반환한다. 다시말하면 키를 가진 객체를 새로 생성하는게 아닌 내부 객체를 재사용하여 키 정보를 반환하는 것이다.
앞서 keySet 메서드는 키 정보를 내부에서 가져온다고 했지만, 필자의 경우 키를 담은 객체를 생성하여 반환하는 줄 알았다. 만약 필자와 같이 keySet의 어댑터 특성을 몰랐다면 keySet() 메서드를 활용해 두개의 키 셋을 구하고 이를 각각 활용해야 하는 상황에서 아래와 같은 결과에 대해 혼란을 느낄 수 있을 것이다.
조슈아 블로크의 'Effective Java' 책을 읽고 제멋대로 정리한 내용입니다. :)
1. 개요
많은 클래스가 하나 이상의 자원에 의존한다. 가령 맞춤법 검사기는 사전에 의존하는데, 이런 클래스를 정적 유틸리티 클래스나 싱글톤 클래스 구현한 모습을 드물지 않게 볼 수 있다.
1) 정적 유틸리티 클래스로 구현한 예
public class SpellChecker {
// 의존 객체 생성
private static final KoreaDictionary dictionary = new KoreaDictionary();
private SpellChecker(){} // 외부 객체 생성 방지
public static boolean isValid(String word){
...
}
public static List<String> suggestions(String typo){
...
}
}
2) 싱글톤 클래스로 구현한 예
public class SpellChecker {
// 의존 객체 생성
private final KoreaDictionary dictionary = new KoreaDictionary();
// 싱글턴 패턴을 사용해 생성한 인스턴스
public static SpellChecker INSTANCE = new SpellChecker();
private SpellChecker(){
}
public static boolean isValid(String word){
...
}
public static List<String> suggestions(String typo){
...
}
}
2. 위 방식의 문제
두 방식 모두 한국어 사전만 사용한다면 큰 문제가 되지 않지만 다른 종류의 사전을 사용해야한다면 변경이 필요할 때마다 의존 객체 생성 부분 코드를 수정해야한다.
3. 수정자 메서드를 통한 문제 해결?
수정자 메서드를 추가하여 의존객체를 변경하는 방법이 있다. 이를 사용하면 사전의 종류가 바뀌는 건 맞지만, 멀티쓰레드 환경에서는 변경되는 상태 값을 공유하면 안되므로 사용해선 안된다.
그렇다면 이러한 클래스는 어떻게 구현해야할까? 바로 생성자를 통해 의존 객체를 주입해야한다.
4. 생성자를 통한 의존 객체 주입
public class SpellChecker {
private final Dictionary dictionary;
// 생성자를 통한 의존 객체 주입
public SpellChecker(Dictionary dictionary){
this.dictionary = dictionary;
}
public static boolean isValid(String word){
...
}
public static List<String> suggestions(String typo){
...
}
}
생성자를 통해 객체를 생성할 때만 의존 객체를 주입하고 있다. 의존 객체는 불변성을 갖게 되어 멀티 쓰레드 환경에서도 안심하고 사용할 수 있다.
KoreaDictionary 클래스 대신 Dictionary 인터페이스를 사용하고, KoreaDictionary와 같은 여러 사전 클래스들이 Dictionary 인터페이스를 구현하도록 했다. 만약 영어사전에 대한 맞춤법 검사 기능을 제공해야한다면 Dictionary 인터페이스를 구현한 EnglishDictionary 클래스를 만들고, 이를 외부에서 생성자를 통해 주입하면 된다. 이로써 의존 객체가 바뀌더라도 SpellChecker의 코드는 변경할 필요가 없게 되었다.
이렇게 의존성을 외부로부터 주입받는 패턴을 의존 객체 주입 패턴이라고 하며 이 패턴의 변형으로 자바 8에서 등장한 Supplier<T> 인터페이스가 있다. 한정적 와일드 카드 타입을 사용해 팩터리의 타입 매개변수를 제한하여 사용할 수 있으며, 클라이언트에서는 해당 타입의 하위 타입을 포함하여 무엇이든 생성할 수 있는 팩터리를 넘길 수 있다.
public class SpellChecker {
...
public SpellChecker(Supplier <? extends Dictionary> factory){
this.dictionary = factory.get();
}
...
}
SpellChecker spellChecker = new SpellChecker(() -> new KoreaDictionary());
※ 개방 폐쇄 원칙
SpellChecker의 맞춤법 검사 기능이 영어까지 '확장' 되었지만, SpellChecker의 코드 '변경'은 일어나지 않는다. 이처럼 '확장'에는 열려있고, '변경'에는 닫혀있는 것을 '개방 폐쇄 원칙' 이라고 한다.
5. 정리
클래스가 하나 이상의 객체에 의존한다면 확장성을 고려하여 싱글턴과 정적 유틸리티 클래스 형태로 사용하지 않는 것이 좋다. 의존 객체는 내부에서 직접 생성하지 말고 생성자 혹은 정적 팩터리 메서드를 통해 넘겨주는 것이 좋다. 의존 객체 주입은 변경에 대한 유연성, 재사용성, 테스트 용이성을 제공한다.
조슈아 블로크의 'Effective Java' 책을 읽고 제멋대로 정리한 내용입니다. :)
1. 개요
필자는 클래스를 정의할 때 매개변수가 많으면 Builder를, 매개변수가 많이 없으면 생성자 메서드를 사용한다. Setter 메서드는 존재 자체로 객체의 상태 변경 가능성을 열어두기 때문에 사용을 지양하고 있으며, 상태 변경이 필요할 경우 Setter 대신 다른 Update와 같이 다른 네이밍을 사용하여 '비지니스적으로 필요한 상태변경이 있을 수 있다' 라는 것을 암시해주었다.
이번 아이템에서는 필자가 알고있는 내용을 다시한번 정리했고, 빌더를 사용하는 이유와, Setter보다 어떤면에서 더 효율적인지를 이해하게 되었다.
2. 자바 빈즈 패턴
2.1. 자바 빈즈 패턴이란?
자바 빈즈 패턴이란 기본 생성자로 객체를 만든 후, Setter 메서드를 호출해 원하는 매개변수의 값을 결정하는 방식이다. 인스턴스를 만들기 쉽고, 사용법도 매우 간단하지만 이 방식은 객체가 완전히 생성되기 전까지는 일관성이 무너진 상태에 놓인다는 매우 심각한 단점을 갖고 있다.
public class NutritionFact {
private int servingSize;
private int servings;
private int calories;
private int fat;
private int sodium;
private int carbohydrate;
public void setServingSize(int servingSize) {this.servingSize = servingSize;}
public void setServings(int servings) {this.servings = servings;}
public void setCalories(int calories) {this.calories = calories;}
public void setFat(int fat) {this.fat = fat;}
public void setSodium(int sodium) {this.sodium = sodium;}
public void setCarbohydrate(int carbohydrate) {this.carbohydrate = carbohydrate;}
}
2.2. 일관성이 뭔가요?
일관성(Consistency)이란 객체의 상태가 프로그램 실행 도중 항상 유효한 상태를 유지해야 한다는 원칙을 말한다. 즉, 객체 내부 상태가 항상 유효한 상태로 일관되게 유지되어야 한다는 뜻이다.
즉, 객체의 상태 값이 할당이 되지 않거나, 할당이 되더라도 유효한 상태가 아닌 것이다. 후자의 경우 은행 계좌 잔고를 예로 들 수 있는데, 잔고는 항상 0 이상의 값으로 일관되게 유지되어야 한다. 이를 위해 아래와 같이 유효성 검사 역할을 하는 비지니스 로직을 넣기도 한다. 이처럼 객체의 상태를 유효한 상태로 일관성 있게 유지하는 것이다.
public class BankAccount{
private double balance;
public BankAccount(double initialBalance) {
this.balance = initialBalance;
}
public void deposit(double amount) {
if (amount > 0) {
balance += amount;
}
}
// 출금 시 balance에 대한 일관성 유지를 위해 유효성 검사하는 로직이 추가됨
public boolean withdraw(double amount) {
if (amount > 0 && amount <= balance) {
balance -= amount;
return true;
}
return false;
}
...
}
2.3. 자바 빈즈 패턴은 왜 일관성이 무너지나요?
그럼 자바 빈즈 패턴을 사용할 경우 객체가 완전히 생성되기 전까지는 일관성이 무너진 상태. 즉, 유효하지 않은 상태가 되는 이유는 뭘까? 필수적으로 설정되어야할 객체의 상태 값이 설정되지 않을 수 있기 때문이다. 이를 책에서는 '객체가 완전히 생성되기 전' 이라고 표현하고 있다.
예를들어 객체를 생성한 후 실수로 setServings()을 호출하지 않는다면 servings를 사용하는 어떤 비지니스 로직이 있을 때 예상치 못한 버그가 발생할 수 있다. 컴파일 단계에서 에러가 나는것도 아니기에 이를 사전에 인지하지 못한다면 버그를 찾기 힘들 수 있다. 참고로 아래 예제에서는 예외 또한 발생하지 않는다. int의 경우 기본 값인 0이 설정되기 때문이다. 이 모든 건 단순 Setter 메서드 호출 누락으로 인해 발생했다.
NutritionFact nutritionFact = new NutritionFact();
//nutritionFact.setServings(20); 실수로 누락
nutritionFact.setServingSize(1);
nutritionFact.setCalories(1);
nutritionFact.setFat(10);
nutritionFact.setCarbohydrate(10);
nutritionFact.setSodium(10);
...
int servings = nutritionFact.getServings();
if(servings >= 10){
// 1회 제공량이 10개 이상일 경우에 대한 비지니스 로직
}
그렇다면 위 단점을 극복하는 방법은 뭘까? 바로 일관성을 보장하는 빌더 패턴을 사용하는 것이다.
3. 빌더 패턴
빌더 패턴은 객체를 생성하는 과정을 보다 유연하게 하기 위한 디자인 패턴 중 하나로, Builder라는 내부 클래스를 통해 객체를 생성하는 방법이다.
NutritionFacts 의 생성자 메서드를 보면 알 수 있듯이 Builder를 통해서만 객체를 생성하고 있고, Builder의 생성자 메서드를 통해 servings나 servingSize와 같은 필수 값을 받도록 설정한다. 나머지 값은 체이닝 메서드 설정하도록 하고 있다.
public class NutritionFacts {
private final int servingSize;
private final int servings;
private final int calories;
private final int fat;
private final int sodium;
private final int carbohydrate;
public static class Builder{
// 필수 매개변수는 final
private final int servings;
// 선택 매개변수는 기본값으로 초기화
private int servingSize;
private int calories = 0;
private int fat = 0;
private int sodium = 0;
private int carbohydrate = 0;
public Builder(int servings){
this.servings = servings;
}
public Builder servingSize(int val){
servingSize = val;
return this;
}
public Builder calories(int val){
calories = val;
return this;
}
public Builder fat(int val){
fat = val;
return this;
}
public Builder sodium(int val){
sodium = val;
return this;
}
public Builder carbohydrate(int val){
carbohydrate = val;
return this;
}
public NutritionFacts build(){
return new NutritionFacts(this);
}
}
private NutritionFacts(Builder builder){
servingSize = builder.servingSize;
servings = builder.servings;
calories = builder.calories;
fat = builder.fat;
sodium = builder.sodium;
carbohydrate = builder.carbohydrate;
}
}
여기서 생성된 NutritionFacts 객체는 필수 값인 servings 값이 없을 수 없다. 누락시킬 경우 컴파일 단계에서 에러가 발생하기 때문이다. 즉, Builder를 통해 생성한 인스턴스는 일관성이 보장되는 것이다.
필수 값인 servings를 설정하지 않았을때 에러 발생
4. 자바 빈즈 패턴 + 명시적 생성자
그럼 자비 빈즈 패턴에서 명시적 생성자를 통해 필수 값을 설정하면 되지 않을까? 그래도 된다. 이 경우 필수 값에 대한 일관성을 보장할 수 있다.
public class NutritionFact {
private int servingSize;
private int servings;
private int calories = 0;
private int fat = 0;
private int sodium = 0;
private int carbohydrate = 0;
public NutritionFact(int servingSize, int servings, int calories, int fat, int sodium, int carbohydrate){
this.servingSize = servingSize;
this.servings = servings;
this.calories = calories;
this.fat = fat;
this.sodium = sodium;
this.carbohydrate = carbohydrate;
}
...
}
그리고 사용 시 아래처럼 생성자 메서드의 파라미터의 순서에 맞게 값을 입력하기만 하면 된다. 그런데 문제가 있다. 이것만 봐서는 어떤 파라미터가 객체의 멤버필드에 매핑되는지 바로 알 수 없다. 직접 생성자 메서드를 확인해야하고, 순서를 일일이 세어야 하는 수고가 필요하다.
NutritionFact nutritionFact = new NutritionFact(10, 10,1,1,1,1);
이에 반해 빌더 패턴은 체인 메서드를 통해 설정하기 때문에 어떤 멤버필드에 값을 설정하는지 바로 알 수 있어 가독성을 향상시킨다. 또한 Setter 메서드가 없으니 중간에 객체의 상태가 변경되지 않음을 보장한다. 즉, 안전한 객체가 되는것이다.
new NutritionFacts.Builder(10)
.calories(100)
.sodium(10)
.carbohydrate(10)
.servingSize(10)
.fat(1)
.build();
5. 정리
생성자나 정적 팩터리가 처리해야 할 매개변수가 많다면 빌더 패턴을 선택하는 게 더 낫다. 매개변수 중 다수가 필수가 아니거나 같은 타입이면 특히 더 그렇다. 빌더는 클라이언트 코드를 읽고 쓰기가 훨씬 간결하고, 자바빈즈보다 훨씬 안전하다.
조슈아 블로크의 'Effective Java' 책을 읽고 제멋대로 정리한 내용입니다. :)
1. 개요
인스턴스를 생성할 때 생성자를 많이 사용하는데, '정적 팩터리 메서드'를 사용하기도 한다. 책에서는 정적 팩터리 메서드 사용을 권장하고 있는데, 과연 어떤 장점을 갖고 있길래 이를 권장하는 것일까?
2. 정적 팩터리 메서드가 뭔가요?
자바에서의 '팩터리'는 '인스턴스를 만드는 공장' 을 의미한다. 즉, 정적 팩터리 메서드란 인스턴스를 만드는 역할을 하는 Static 메서드이다. 아래와 같이 말이다.
public class User {
private String name;
// 접근 제한자를 private 로 하여 외부 호출을 막음.
private User(String name){
this.name = name;
}
// 유저 인스턴스를 생성하는 정적 팩터리 메서드
public static User from(String name){
return new User(name);
}
}
정적 팩터리 메서드 안에서 생성자를 호출하고 있고, 생성자는 private로 하여 외부 호출을 막고있다. public 생성자를 사용했을때보다 코드가 늘어나고 복잡해진것 같은데, 과연 어떤 장점을 갖고 있길래 생성자보다 정적 팩터리 메서드 방식을 권장하는 걸까?
3. 장점
3.1. 이름을 지정함으로써 가독성을 증가시킨다.
생성자는 이름이 없다. 굳이 따지자면 클래스 명이다. 이에 반해 정적 팩터리 메서드는 이름을 지정할수 있다. 이름과 대학 입학년도를 갖는 Student 클래스로 예를들어 설명하겠다. 멤버필드인 name은 학생 이름, admissionYear는 입학년도이다.
1) public 생성자 사용
public class Student {
private String name;
private int admissionYear;
public Student(String name){
LocalDate now = LocalDate.now();
this.name = name;
this.admissionYear = now.getYear();
}
public Student(String name, int admissionYear){
this.name = name;
this.admissionYear = admissionYear;
}
}
class Main{
public static void main(String[] args) {
Student student1 = new Student("김철수");
Student student2 = new Student("곽영희", 2020);
}
}
2) 정적 팩터리 메서드 사용
public class Student {
private String name;
private int admissionYear;
private Student(String name, int admissionYear) {
this.name = name;
this.admissionYear = admissionYear;
}
public static Student createFreshman(String name) {
LocalDate now = LocalDate.now();
return new Student(name, now.getYear());
}
public static Student createOfAdmissionYear(String name, int year) {
return new Student(name, year);
}
}
class Main{
public static void main(String[] args) {
Student student1 = Student.createFreshman("김철수");
Student student2 = Student.createOfAdmissionYear("곽영희", 2020);
}
}
먼저 생성자의 신입생과 재학생에 대한 학생 인스턴스를 생성할 때 시그니처가 다른 public 생성자를 호출하고 있다.
여기서 중요한 점은 메인 메서드에서 이를 사용할 때 public 생성자의 시그니처만 봐서는 어떤 특성을 갖는 인스턴스를 생성하는지 알 수 없다. 직접 생성자 코드를 봐야 알 수 있다.
반면 정적 팩터리 메서드를 사용한 경우 메서드 명을 통해 생성할 인스턴스의 특성을 묘사할 수 있다. createFreshman은 올해 입학한 학생, createOfAdmissionYear는 특정 년도에 입학한 학생 인스턴스를 생성하고 있다. Student라는 생성자 명만 덩그러니 있는것보다 특성을 묘사할 수 있는 메서드 이름을 사용함으로써 가독성을 증가시킨 것이다.
3.2. 인스턴스 재활용을 통한 메모리 효율 증대
인스턴스를 미리 만들어 놓거나, 새로 생성한 인스턴스를 캐싱하여 불필요한 객체 생성을 피할 수 있다. 대표적으로 Boolean.valueOf(boolean) 메서드는 미리 만들어 놓은 인스턴스를 리턴하는 방식으로 사용된다.
만약 생성 비용이 큰 객체가 자주 생성될 경우에 이 방식을 활용한다면 객체 생성 시 사용하게 되는 힙 메모리의 사용율을 줄일 수 있어 메모리 효율적이라고 할 수 있다.
public final class Boolean{
public static final Boolean TRUE = new Boolean(true);
public static final Boolean FALSE = new Boolean(false);
...
public static Boolean valueOf(boolean b) {
return (b ? TRUE : FALSE);
}
}
3.3. 하위 타입 객체 반환을 통한 유연성 증대
Java 8버전부터 인터페이스 내에 정적 팩터리 메서드를 구현할 수 있다. 이를 통해 인터페이스의 구현체 클래스를 메서드마다 자유롭게 지정할 수 있어 인스턴스 생성에 대한 유연성을 제공한다.
아래는 Weapon 인터페이스에 정의한 정적 팩터리 메서드를 통해 Weapon의 구현체 클래스인 Sword, Gun에 대한 인스턴스를 생성하고 있다.
public interface Weapon {
static Weapon createSword(){
return new Sword();
}
static Weapon createGun(){
return new Gun();
}
}
...
public class Main {
public static void main(String[] args) {
Weapon sword = Weapon.createSword();
Weapon gun = Weapon.createGun();
}
}
3.4. 조건에 따른 하위 타입 객체 반환을 통한 유연성 증대
앞에서는 구현체 클래스에 대한 인스턴스 생성을 위해 외부에서 직접 해당 메서드를 호출하고 있다. 만약 요구사항이 바뀌어 직업이 검사일때는 Sword, 스나이퍼일때는 Gun 인스턴스를 생성해야한다면 어떻게 할까? main 메서드에서 직업에 대해 분기 후 검사일때는 createSword() 메서드를, 스나이퍼일때는 createGun() 메서드를 호출할 수도 있지만, 정적 팩터리 메서드 내에서 직업을 파라미터로 받고, 내부 조건문에 따라 무기 인스턴스를 반환할 수도 있다.
public interface Weapon {
static Weapon createFromJob(Job job){
if(job == Job.SNIPER){
return new Gun();
}else{
return new Sword();
}
}
}
...
public class Main {
public static void main(String[] args) {
Weapon sword = Weapon.createFromJob(Job.SWORDS_MAN);
Weapon gun = Weapon.createFromJob(Job.SNIPER);
}
}
3.5. 캡슐화를 통한 코드중복 및 파편화 방지
위 예제를 보면 Weapon 인터페이스에서 무기 생성에 대한 구현부를 캡슐화시키고, 메인 메서드에서는 캡슐화된 메서드를 호출하고 있다. 그렇다면 캡슐화란 무엇이고 목적은 뭘까?
※ 캡슐화
캡슐화란 객체의 속성과 행위를 하나로 묶고, 실제 구현부는 외부로부터 은닉하는 것을 말한다.
환자가 약사에게 독감 진단서를 제출하면 약사는 정해진 재료와 제조 과정을 거쳐 약을 조제한다. 알약을 받는 환자는 여기에 사용된 재료나 제조 과정을 이해할 필요도, 알 필요도 없다. 다만 진단서를 제출할 뿐이다.
자바 코드로 이해하면 약사 객체인 Chemist 클래스를 만들고 약을 제조하는 전 과정을 makePill 이라는 약을 조제하는 메서드로 묶는 것이다. 외부 클래스에서 약이 필요하다면 Chemist 클래스에서 해당 메서드를 호출하기만 하면 된다. 호출하는 클래스는 어떤 과정을 거쳐 약이 만들어지는지는 알 필요가 없게 된다.
이처럼 약을 조제하는데 필요한 여러 속성들과 행위를 makePill 이라는 하나의 메서드로 묶고, 이에 대한 구현부는 외부로부터 은닉하여 알 필요가 없게하는 것이 바로 캡슐화이다.
public class Chemist {
public Pill makePill(String 진단서){
// 약을 만드는 방법에 대한 로직
return pill; // 생성된 약
}
}
만약 약사라는 클래스를 통해 해당 로직을 캡슐화를 하지 않는다면 어떤 일이 벌어질까? 약이 필요한 모든 곳에서 약을 조제하는 로직을 구현해야 하며, 아래와 같이 중복코드와 메서드 파편화가 발생하게 된다.
public void hospitalCare(){
// 1. 병원 진료
// 2. 약은 만드는 방법에 대한 로직 >> 코드중복 ! 메서드 파편화!
}
// 병원 진료 내역을 조회한 후 해당 내역에 대한 처방전을 받는 메서드
public void getHospitalCareHistory(){
// 1. 병원 진료 내역 조회
// 2. 약은 만드는 방법에 대한 로직 >> 코드중복 ! 메서드 파편화!
}
이 상태에서 약을 만드는 방법에 대한 로직이 변경되면 어떻게될까? 모든 메서드의 로직을 전부 바꿔야한다. 이때 작은 실수가 발생한다면 심각한 버그가 발생하게 된다. 만약 캡슐화가 되어있다면? 앞서 약사 클래스의 makePill 메서드만 변경해주면 된다.
정리하면 캡슐화는 구현부를 외부로부터 은닉함으로써 책임을 분리하고, 코드의 중복 및 파편화를 예방하고, 유지보수하기 용이한 코드로 만들어주는 유용한 프로그래밍 기법인것이다.
4. 정적 팩터리 메서드 명명 방식
메서드 명은 개발자 마음이지만, 정적 팩터리 메서드 같은 특별한 메서드의 경우 권장하는 명명 방식이 있다.
'자바 엔터프라이즈 개발을 편하게' 해주는 '오픈소스' '경량급' '애플리케이션 프레임워크'
1.1. 애플리케이션 프레임워크
일반적으로 프레임워크는 특정 업무 분야나 한가지 기술에 특화된 목표를 가지고 만들어진다. 스프링은 특정 계층이나, 기술, 업무 분야에 국한되지 않고 애플리케이션 전 영역을 포괄하는 범용적인 프레임워크이다.
1.2. 경량급
스프링 자체가 가볍다는 뜻이 아니다. 개발환경, 빌드, 테스트 과정, 코드 등 매우 무겁고 복잡했던 EJB에 비해 불필요하게 무겁지 않다는 뜻이다.
1.3. 자바 엔터프라이즈 개발을 편하게
IoC/DI, 서비스 추상화, AOP 등을 통해 로우 레벨의 트랜잭션이나 상태관리, 스레딩, 리소스 풀링과 같은 복잡한 로우레벨의 API를 이해하지 못하더라도 아무 문제 없이 애플리케이션 개발을 할 수 있다.
1.4. 오픈소스
스프링은 오픈소스 프로젝트 방식으로 개발되고 있으며, 2009년 세계적인 IT 기업에 합병되었다. 즉, 전문적이고 성공적인 오픈소스 프레임워크이다.
2. 복잡한 엔터프라이즈 시스템?
'자바 엔터프라이즈 개발을 편하게' 라는 부분에서 알 수 있듯이 스프링을 사용하기 전 자바 엔터프라이즈 개발은 불편하고 복잡했다고 한다. 그 이유는 무엇일까?
2.1. 기술적인 복잡함
엔터프라이즈 시스템은 기업과 조직의 업무를 처리해주는 시스템이다. 기업 내 많은 사용자들의 요청을 처리해야 하기에 시스템의 안정성을 고려해야한다. 또한 조직의 업무 처리는 곧, 조직의 핵심 정보 처리이다. 핵심 정보에 대한 보안성도 고려해야 한다. 이 뿐 아니라 업무 자체에도 여러 기술이 사용된다.
정리하면 안정성과 보안성, 업무적인 기술 등, 다양한 기술적인 복잡도를 갖게 된다.
2.2. 비지니스 로직의 복잡함
기업의 핵심 업무는 복잡하고, 한정되어 있지 않다. 처리하는 업무가 많아짐에 따라 비지니스 로직도 늘어나고, 복잡해진다.
2.3. 기술과 비지니스 로직의 복잡함
엔터프라이즈 시스템은 기술적인 복잡함과 비지니스 로직의 복잡함이 얽혀있다. 코드를 담는 하나의 파일 안에 여러 기술이 담긴 코드와 비지니스 로직 코드가 얽혀있다고 생각하면 된다.
3. 스프링의 목적
스프링의 목적은 엔터프라이즈 애플리케이션 개발을 편하게 하는 것이다. 스프링은 이를 위해 기술 부분과 비지니스 로직 부분을 분리하고 사용할 수 있도록 도와준다. OOP와 DI를 통해서 말이다.
사용하는 기술들은 추상화 되어있다. 기술에 대한 로우 레벨의 코드를 이해하고 있지 않아도 사용할 수 있으며, 기술이 변경되어도 비지니스 로직을 수정할 필요가 없게된다.
AOP를 사용하면 트랜잭션과 같은 기술을 담당하는 부분을 비지니스 로직과 아예 분리할 수도 있다.
이처럼 스프링은 엔터프라이즈 애플리케이션 개발을 편하게 하도록 돕는다.
4. 결론
스프링은 객체지향이라는 도구를 극대화해서 애플리케이션 개발을 편하게 할 수 있도록 도울 뿐이다. 객체 지향적인 프로그래밍을 얼마나 잘 하냐에 따라 스프링의 활용도가 달라지게 된다.
때문에 스프링 공부와 함께 개발자 본인의 객체지향 설계와 개발 능력을 키워야 비로소 복잡한 엔터프라이즈 시스템을 잘 개발할 수 있다는 점을 잊지 말자.
AOP는 IoC/DI, 서비스 추상화와 더불어 스프링의 3개 기반 중 하나이며, 이해하기 어려운 기술 중 하나이다. 스프링에 적용된 가장 인기있는 AOP의 적용 대상은 선언적 트랜잭션 기능이다. 서비스 추상화를 적용한 트랜잭션 경계설정 기능을 AOP를 사용해 더욱 깔끔한 코드로 개선함과 동시에 AOP라는 기술을 이해해보도록 하자.
2. 트랜잭션 코드의 분리
현재 트랜잰션 관련 코드는 아래와 같이 UserService에 비지니스 로직과 공존한다. 트랜잭션 경계 설정은 비지니스 로직 전/후에 설정되어야 하므로 틀렸다고 할 순 없지만, 트랜잭션 관련 코드와 비지니스 로직 관련 코드가 함께 존재하므로 리팩토링이 필요해 보인다. 트랜잭션 코드 분리를 통해 리팩토링 해보자.
public void upgradeLevels() {
TransactionStatus status = transactionManager.getTransaction(
new DefaultTransactionDefinition()
); // 트랜잭션 관련 코드
try{
List<User> users = userDao.getAll(); // 비지니스 로직 관련코드
for(User user : users) { // 비지니스 로직 관련코드
if (userLevelUpgradePolicy.canUpgradeLevel(user)) { // 비지니스 로직 관련코드
userLevelUpgradePolicy.upgradeLevel(user); // 비지니스 로직 관련코드
}
}
transactionManager.commit(status); // 트랜잭션 관련 코드
}catch(Exception e){
transactionManager.rollback(status); // 트랜잭션 관련 코드
}
}
2.1. 메서드 분리
트랜잭션 경계 설정의 코드와 비지니스 로직 코드 간에는 서로 주고받는 정보가 없다. 이 메서드에서 시작된 트랜잭션 정보는 트랜잭션 동기화 방법을 통해 DAO가 알아서 사용한다. 즉, 이 두 가지 코드는 성격이 다르고, 주고받는 것도 없는 독립적인 코드이므로 아래와 같이 메서드로 분리할 수 있다.
public void upgradeLevels() {
TransactionStatus status = transactionManager.getTransaction(
new DefaultTransactionDefinition()
);
try{
upgradeLevelsInternal();
transactionManager.commit(status);
}catch(Exception e){
transactionManager.rollback(status);
}
}
private void upgradeLevelsInternal(){
List<User> users = userDao.getAll();
for(User user : users) {
if (userLevelUpgradePolicy.canUpgradeLevel(user)) {
userLevelUpgradePolicy.upgradeLevel(user);
}
}
}
internal 메서드를 만들어 분리하긴 했지만 여전히 트랜잭션을 담당하는 코드가 UserService에 포함되어 있다. 이번에는 트랜잭션 코드를UserService 밖으로 뽑아내보자.
2.2. DI를 통한 트랜잭션 분리
DI를 사용한다는 것은 인터페이스를 도입한 후 런타임에 구현체 클래스를 설정해주어 확장과 변경을 용이하게 하기 위함이다. 현재 클라이언트는 UserServiceTest이며, UserService에 직접 접근하고 있으나 인터페이스를 도입하면 다음과 같은 형태로 구현 가능하다.
인터페이스 도입에 따른 구조
그런데 이 작업의 목표는 트랜잭션 로직을 분리하는 것이다. 이 상태라면 UserServiceImpl에 기존 UserService의 코드가 들어가야 하기에 결국 트랜잭션 로직과 비지니스 로직이 아직도 한 클래스에 들어가 있는 상태이다. 때문에 아래와 같이 트랜잭션 기능을 처리하는 UserService의 구현체 클래스를 새로 생성해야한다.
UserServiceTx 추가에 따른 구조
키포인트는 UserServiceImpl는 비지니스 로직을, UserServiceTx는 트랜잭션 로직을 담당하게 하는 것이다. 그리고 UserServiceTx 에서 UserService의 구현체를 사용하고 있는데, 이때 사용하는 UserService의 구현체를 UserServiceImpl로 설정하는 것이다. 이런 구조를 채택한 이유는 의존관계를 아래와 같이 설정하여 트랜잭션 로직과 비지니스 로직을 분리하기 위함이다. 이제 코드를 수정하자.
새로운 의존관계
2.2.1. UserService.java
public interface UserService {
void upgradeLevels();
void add(User user);
}
UserService 인터페이스를 생성한다.
2.2.2. UserServiceImpl.java
public class UserServiceImpl implements UserService {
private IUserDao userDao;
private UserLevelUpgradePolicy userLevelUpgradePolicy;
public void setUserDao(IUserDao userDao){
this.userDao = userDao;
}
public void setUserLevelUpgradePolicy(UserLevelUpgradePolicy userLevelUpgradePolicy){
this.userLevelUpgradePolicy = userLevelUpgradePolicy;
}
public void upgradeLevels() {
List<User> users = userDao.getAll(); // DB /
for(User user : users) {
if (userLevelUpgradePolicy.canUpgradeLevel(user)) {
userLevelUpgradePolicy.upgradeLevel(user);
}
}
}
public void add(User user) {
if(user.getLevel() == null){
user.setLevel(Level.BASIC);
}
userDao.add(user);
}
}
UserServiceImpl 클래스를 생성한다. 기존 트랜잭션 관련 코드는 UserServiceTx 클래스에 넣을 예정이므로 제거한다. 그와 동시에 트랜잭션과 관련된 멤버필드인 transactionManager도 제거한다.
2.2.3. UserServiceTx.java
public class UserServiceTx implements UserService{
private PlatformTransactionManager transactionManager;
private UserService userService;
public void setTransactionManager(PlatformTransactionManager transactionManager){
this.transactionManager = transactionManager;
}
public void setUserService(UserService userService){
this.userService = userService;
}
@Override
public void upgradeLevels() {
TransactionStatus status = transactionManager.getTransaction(
new DefaultTransactionDefinition()
);
try{
userService.upgradeLevels();
transactionManager.commit(status);
}catch(Exception e){
transactionManager.rollback(status);
}
}
@Override
public void add(User user) {
TransactionStatus status = transactionManager.getTransaction(
new DefaultTransactionDefinition()
);
userService.add(user);
try{
transactionManager.commit(status);
}catch(Exception e){
transactionManager.rollback(status);
}
}
}
UserServiceTx 클래스를 생성한다. 각각의 메서드에 트랜잭션 관련 코드를 넣는다. 그리고 비지니스 로직을 담당하는 UserServiceImpl을 DI받기 위해 UserService에 대한 멤버필드와 수정자 메서드를 추가한다.
2.2.4. application-context.xml
<bean id = "userService" class ="org.example.user.service.UserServiceTx">
<property name="transactionManager" ref = "transactionManager"></property>
<property name="userService" ref = "userServiceImpl"></property>
</bean>
<bean id = "userServiceImpl" class = "org.example.user.service.UserServiceImpl">
<property name="userDao" ref = "userDao"></property>
<property name="userLevelUpgradePolicy" ref = "userLevelUpgradePolicy"></property>
</bean>
이제 DI 정보를 위와같이 수정한다. userService 빈 구현체는 UserServiceTx로 DI하고, UserServiceTx에서 사용하는 userService 멤버필드는 userServiceImpl 빈을 DI한다.
2.2.5. 테스트
이로써 같은 인터페이스에 대한 두 개의 구현체 클래스를 사용하여 비지니스 로직과 트랜잭션 로직을 분리하였다. 이제 작성한 테스트 코드를 위 구조에 맞게 수정한 후 테스트를 통해 확인해보자.
2.3. 트랜잭션 코드 분리의 장점
위와 같은 작업을 통해 얻을 수 있는 장점은 뭘까?
첫째, 비지니스 로직을 담당하는 코드를 작성할 때에는 트랜잭션 로직에 대해 신경쓰지 않아도 된다. 또 트랜잭션 적용이 필요한지도 신경쓰지 않아도 된다. 트랜잭션은 모두 UserServiceTx와 같은 트랜잭션 관련 클래스가 신경쓸 일이다.
둘째, 비지니스 로직에 대한 테스트를 쉽게 만들 수 있다. 이에 대한 내용은 아래에서 더 자세하게 다룬다.
3. 고립된 단위 테스트
가장 편하고 좋은 테스트 방법은 가능한 한 작은 단위로 쪼개서 테스트하는 것이다. 테스트가 실패했을때 원인을 찾기 쉽기 때문이다. 클래스 하나에 대한 테스트와 여러 클래스에 대한 테스트 중 전자가 오류를 찾기 쉽다는건 매우 당연하다.
3.1. 복잡한 의존관계 속의 테스트
UserService를 테스트하기 위해선 아래와 같이 의존하고 있는 클래스인 UserDao, MailSender, PlatformTransactionManager, UserLevelUpgradePolicy를 설정해야 한다. UserServiceTest 클래스는 비지니스 로직인 UserServiceImpl 클래스를 테스트하기 위함이나, 의존 클래스인 UserDao, MailSender, PlatformTransactionManager, UserLevelUpgradePolicy 클래스도 테스트하게 되는 격이다. 왜? 언급한 4개의 클래스 중 한 부분에서 에러가 날 경우 UserServiceTest 의 테스트는 실패하기 때문이다.
이럴때 Mock과 같은 테스트 대역을 사용하여 테스트 대상이나 환경이 다른 클래스에 영향을 받지 않도록 고립시켜야 한다.
3.2. UserServiceImpl 고립
현재 필자의 UserServiceImpl은 UserDao와 UserLevelUpgradePolicy를 의존하고 있다. 때문에 이 두 클래스에 대한 테스트 대역인 Mock을 사용하거나 UserDao의 경우 Fake 대역을 사용하는 방법으로 구성할 수 있다. 필자는 Mockito에서 제공하는 MockBean을 사용하여 구현하였다.
class UserServiceTest {
private final UserServiceImpl userServiceImpl = new UserServiceImpl();
private final IUserDao userDao = mock(IUserDao.class);
private final UserLevelUpgradePolicy userLevelUpgradePolicy = mock(UserLevelUpgradePolicy.class);
private final List<User> users = Arrays.asList(
new User("test1","테스터1","pw1", Level.BASIC, 49, 0, "tlatmsrud@naver.com"),
new User("test2","테스터2","pw2", Level.BASIC, 50, 0, "tlatmsrud@naver.com"),
new User("test3","테스터3","pw3", Level.SILVER, 60, 29, "tlatmsrud@naver.com"),
new User("test4","테스터4","pw4", Level.SILVER, 60, 30, "tlatmsrud@naver.com"),
new User("test5","테스터5","pw5", Level.GOLD, 100, 100, "tlatmsrud@naver.com")
);
@BeforeEach
void setUp(){
userServiceImpl.setUserDao(userDao);
userServiceImpl.setUserLevelUpgradePolicy(userLevelUpgradePolicy);
given(userDao.getAll()).willReturn(users);
willDoNothing().given(userDao).add(any(User.class));
given(userLevelUpgradePolicy.canUpgradeLevel(users.get(0))).willReturn(false);
given(userLevelUpgradePolicy.canUpgradeLevel(users.get(1))).willReturn(true);
given(userLevelUpgradePolicy.canUpgradeLevel(users.get(2))).willReturn(false);
given(userLevelUpgradePolicy.canUpgradeLevel(users.get(3))).willReturn(true);
given(userLevelUpgradePolicy.canUpgradeLevel(users.get(4))).willReturn(false);
given(userLevelUpgradePolicy.upgradeLevel(any(User.class))).will(invocation -> {
User source = invocation.getArgument(0);
return source.getId();
});
}
@Test
@DisplayName("업그레이드 레벨 테스트")
void upgradeLevels(){
userServiceImpl.upgradeLevels();
verify(userDao).getAll();
verify(userLevelUpgradePolicy,times(5)).canUpgradeLevel(any(User.class));
verify(userLevelUpgradePolicy).upgradeLevel(users.get(1));
verify(userLevelUpgradePolicy).upgradeLevel(users.get(3));
}
@Test
@DisplayName("레벨이 할당되지 않은 User 등록")
void addWithNotAssignLevel(){
User user = users.get(0);
user.setLevel(null);
userServiceImpl.add(user);
assertThat(user.getLevel()).isEqualTo(Level.BASIC);
verify(userDao).add(any(User.class));
}
@Test
@DisplayName("레벨이 할당된 User 등록")
void addWithAssignLevel(){
User user = users.get(0);
Level userLevel = user.getLevel();
userServiceImpl.add(user);
assertThat(user.getLevel()).isEqualTo(userLevel);
}
}
given을 통해 Mock에 대한 Stub을 설정하였다. 그리고 userLevelUpgrade가 실제로 이루어졌는지에 대한 테스트코드는 모두 삭제했는데, 그 이유는 해당 테스트는 UserSeviceImpl이 아닌 UserLevelUpgradePolicy에서 이루어져야 하기 때문이다.
4. 단위 테스트와 통합 테스트
4.1. 단위테스트
테스트 대상 클래스를 테스트 대역을 이용해 고립시키는 테스트이다.
4.2. 통합 테스트
두 개 이상의 성격이나 계층이 다른 오브젝트를 연동하여 테스트하거나, 외부 파일, DB 등의 리소스가 참여하는 테스트이다. 스프링 컨텍스트에서 DI된 오브젝트를 테스트하는 것도 통합 테스트이다.
4.3. 테스트 선택 가이드라인
1) 항상 단위 테스트를 먼저 고려한다.
2) 테스트 코드에서의 의존관계는 모두 차단하고 Stubbing이나 목 오브젝트 등의 테스트 대역을 사용하여 테스트한다.
3) 외부 리소스를 사용해야만 가능한 테스트는 통합 테스트로 만든다.
4) DAO의 경우도 Stubbing이나 목 오브젝트로 대처해서 테스트한다.
5) 여러 의존관계를 가지고 동작할 때를 위한 통합 테스트는 필요하다. 다만, 단위 테스트를 충분히 거쳤다면 통합 테스트의 부담은 줄어든다.
6) 가능하면 스프링의 지원 없이 직접 코드 레벨의 DI를 사용하여 단위테스트를 하는게 좋지만 스프링의 설정 자체도 테스트 대상이고, 스프링을 이용해 좀 더 추상적인 레벨에서 테스트를 해야할 경우는 스프링 테스트 컨텍스트 프레임워크를 이용해 통합 테스트를 작성한다.
5. Mockito 프레임워크
목 클래스를 생성할 필요 없이 메서드 호출만으로 테스트용 목 오브젝트를 구현할 수 있는 프레임워크이다. 이를 통해 생성된 목 오브젝트는 아무 기능이 없기때문에 특정 메서드가 호출됐을 때 어떤 값을 리턴해야하는지와 같은 Stub 기능을 추가해야한다. 이를 Stubbing 이라고 한다.
현재 트랜잭션 기술과, UserService, UserDao같은 어플리케이션 로직에 대해 추상화기법이 적용되어 있다. UserDao와 UserService는 각각 User에 대한 데이터 처리, 비지니스 처리에 대한 관심으로 구분되어 있다.
이 둘 모두 전략 패턴이 적용되어 있으며, 낮은 결합도를 갖는다. 결합도가 낮기 때문에 UserDao의 데이터 처리 로직이 바뀌어도 UserService의 코드에는 영향을 주지 않는다. 반대도 마찬가지다.
UserDao는 DB Connection을 생성하는 방법에 대해서도 독립적이다. DataSource 인터페이스와 DI를 통해 추상화된 방식으로 로우레벨의 DB 연결 기술을 사용하기 때문이다. DB 풀링 라이브러리를 사용하든, JDBC의 DriverManager를 사용하든, WAS가 JNDI를 통해 데이터 소스 서비스를 이용하든 상관없이 UserDao 코드에는 영향을 주지 않는다. 즉, UserDao와 DB 연결 기술도 결합도가 낮고, 수직적으로 분리되어 있다는 뜻이다.
이렇게 결합도가 낮은 구조로 만들 수 있는 데에는 스프링의 DI가 중요한 역할을 하고 있다. DI의 가치는 관심, 책임, 성격이 다른 코드를 깔끔하게 분리하는 데 있다. 이제 이러한 내용을 단일 책임원칙이라는 개념과 함께 이해해보자.
2. 단일 책임 원칙
2.1. 단일 책임 원칙이란?
DI의 가치인 '분리'는 객체지향 설계의 원칙 중 하나인 '단일 책임 원칙'으로 설명할 수 있다.
단일 책임 원칙(SRP : Single Responsibility Principle) 객체는 단 하나의 책임만 가져야 한다.
UserService에 JDBC Connection 메서드를 직접 사용했을 때에는 사용자의 레벨 관리와 트랜잭션 관리에 대한 두가지 책임을 갖고 있었다. 단일 책임 원칙을 지키지 못하는 것이다. 이로써 사용자의 레벨 관리 정책이 바뀌거나, 트랜잭션 기술이 JDBC 에서 JTA로 변경될 경우 UserService 클래스의 코드도 반드시 수정되어야 했었다.
추후 트랜잭션 기술에 대한 추상화 기법의 도입하여 트랜잭션 관리 책임을 트랜잭션 매니저에게 위임했다. 이로써 UserService는 단일 책임 원칙을 지키게 됐고, 트랜잭션 기술이 바뀌어도 UserService의 코드는 바뀔 필요가 없게 되었다.
2.2. 단일 책임 원칙의 장점
어떤 변경이 필요할 때 수정 대상이 명확해진다. 트랜잭션 기술이 바뀌면 기술 추상화 계층의 설정만 바꿔주면 되고, 데이터를 가져오는 테이블이 바뀌었다면 데이터 액세스 로직을 담고있는 UserDao만 변경하면 된다. 마찬가지로 레벨 관리 정책이 바뀌면 UserService만 변경하면 된다.
이러한 구조로 만들기 위해 빠지지 않았던게 바로 스프링 DI였다. 인터페이스의 도입과 적절한 DI는 단일 책임 원칙 뿐 아니라 개방 폐쇄 원칙도 잘 지키게 되니 결합도가 낮아 변경에 유연하며, 단일 책임에 집중하는 응집도 높은 코드를 개발할 수 있다.
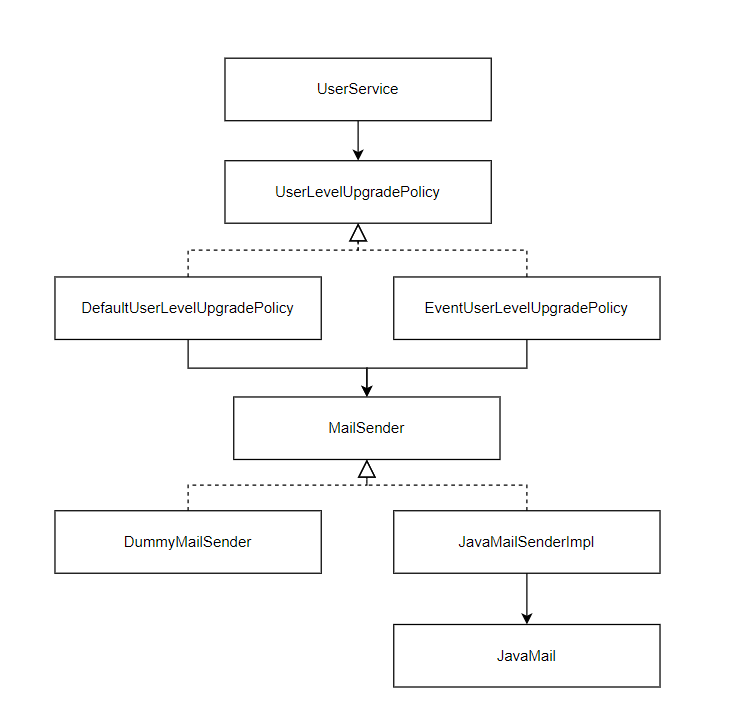
3. 메일 서비스 추상화
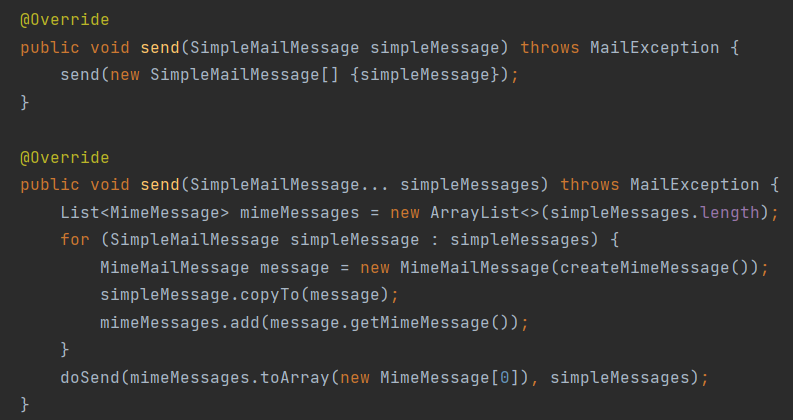
위 내용을 생각하며 메일 발송에 대한 추상화를 적용해보자. 메일은 자바에서 제공하는 메일 발송 표준 기술인 JavaMail을 사용한다. 일반적으로 사용되는 예제 코드를 사용했으며, 필자의 경우 NAVER에서 제공하는 SMTP를 사용하였기에 사용에 필요한 여러 프로퍼티와 id, password 정보를 담고있는 Authenticator 객체 활용해주었다.
3.1. DefaultUserLevelUpgradePolicy.java
public class DefaultUserLevelUpgradePolicy implements UserLevelUpgradePolicy{
...
public String upgradeLevel(User user){
user.upgradeLevel();
userDao.update(user);
sendUpgradeMail(user); // 메일 발송 추상화메서드
return user.getId();
}
private void sendUpgradeMail(User user) {
Properties props = new Properties();
props.put("mail.host", "smtp.naver.com");
props.put("mail.port", "465");
props.put("mail.smtp.auth" , "true");
props.put("mail.smtp.ssl.enable", "true");
props.put("mail.smtp.ssl.trust", "smtp.naver.com");
props.put("mail.debug", "true");
Session s = Session.getInstance(props, new Authenticator() {
protected PasswordAuthentication getPasswordAuthentication() {
return new PasswordAuthentication("ID","PASSWORD");
}
});
MimeMessage message = new MimeMessage(s);
try{
message.setFrom(new InternetAddress("test@naver.com"));
message.addRecipient(Message.RecipientType.TO, new InternetAddress(user.getEmail()));
message.setSubject("Upgrade 안내");
message.setText("사용자님의 등급이 " + user.getLevel().name() +" 로 업그레이드 되었습니다.");
Transport.send(message);
} catch (AddressException e) {
e.printStackTrace();
throw new RuntimeException(e);
} catch (MessagingException e) {
e.printStackTrace();
throw new RuntimeException(e);
} catch (Exception e) {
e.printStackTrace();
throw new RuntimeException(e);
}
}
}
3.2. 테스트 결과
기존에 작성했던 테스트 코드를 실행하니 레벨 업그레이드 관련된 테스트 시 지정한 메일 주소로 메일이 발송됨을 확인할 수 있었다. (필자의 메일로 보냈다.)
메일 발송 테스트
3.3. 메일이 발송되는 테스트
이제 테스트 코드를 실행할 때마다 메일이 발송되게 되었다. 그런데 이처럼 메일이 발송되는 테스트는 바람직한 테스트라고 할 수 없다. 그 이유는 다음과 같다.
첫째, 메일 발송이란 부하가 큰 작업이다. 필자의 경우 네이버에서 제공하는 메일 서버를 사용했지만, 만약 유료 메일서버나, 본인이 속한 회사에서 실제 운영중인 메일 서버를 사용한다면 해당 서버에 상당한 부담을 줄 수 있다.
둘째, 실수로 인해 메일을 발송할 수 있다. 메일 테스트를 위해 개발자 자신의 이메일이나, 더미 이메일을 설정할수도 있지만, 개발, 운영 환경 설정 실수로 인해 테스트 메일을 실 사용자에게 발송할 수도 있다.
셋째, 테스트 속도가 느려진다. 레벨 업그레이드에 대한 테스트 케이스가 많다면, 실제 메일 발송도 많이 일어나게 된다. 메일 발송이 많다면, 테스트도 느려질 수 있다.
메일 서버는 충분히 테스트된 시스템이므로 초기에 몇번정도만 실제 주소로 메일을 보내고 받는걸 확인하는 걸로 충분하다. 결국 바람직한 메일 발송 테스트란 메일 전송 요청은 받되 메일 발송은 되지 않도록 하는것이다. 운영 시에는 JavaMail을 직접 이용해서 동작하도록 하고, 테스트 중에는 JavaMail을 사용할 때와 동일한 인터페이스를 갖는 코드가 동작하도록 구현해보자.
4. 메일 발송 테스트를 위한 서비스 추상화
실제 메일 전송을 수행하는 JavaMail 대신 JavaMail과 같은 인터페이스를 갖는 오브젝트를 만들어 사용하려했으나 그럴 수 없었다. 이유는 JavaMail의 핵심 API에는 DataSource처럼 인터페이스로 만들어진게 없기때문에 구현부를 바꿀 수 없다. 메일 발송 시 사용하는 Session, MailMessage, Transport 모두 인터페이스가 아닌 클래스이다. 실제로 JavaMail은 확장이나 지원이 불가능하도록 만들어진 API 중 하나라고 한다.
스프링에서는 이러한 JavaMail에 대한 추상화 기능을 제공하고 있다. JavaMail의 서비스 추상화 인터페이스는 다음과 같다.
@ExtendWith(SpringExtension.class)
@ContextConfiguration(locations = "/test-applicationContext.xml")
class DefaultUserLevelUpgradePolicyTest {
@Autowired
IUserDao userDao;
@Autowired
DefaultUserLevelUpgradePolicy userLevelUpgradePolicy;
List<User> users; // 테스트 픽스처
public static final int MIN_LOGIN_COUNT_FOR_SILVER = 50;
public static final int MIN_RECCOMEND_FOR_GOLD = 30;
@BeforeEach
void setUp(){
users = Arrays.asList(
new User("test1","테스터1","pw1", Level.BASIC, MIN_LOGIN_COUNT_FOR_SILVER-1, 0, "tlatmsrud@naver.com"),
new User("test2","테스터2","pw2", Level.BASIC, MIN_LOGIN_COUNT_FOR_SILVER, 0, "tlatmsrud@naver.com"),
new User("test3","테스터3","pw3", Level.SILVER, 60, MIN_RECCOMEND_FOR_GOLD-1, "tlatmsrud@naver.com"),
new User("test4","테스터4","pw4", Level.SILVER, 60, MIN_RECCOMEND_FOR_GOLD, "tlatmsrud@naver.com"),
new User("test5","테스터5","pw5", Level.GOLD, 100, 100, "tlatmsrud@naver.com")
);
}
@Test
void canUpgradeLevel() {
assertThat(userLevelUpgradePolicy.canUpgradeLevel(users.get(0))).isFalse();
assertThat(userLevelUpgradePolicy.canUpgradeLevel(users.get(1))).isTrue();
assertThat(userLevelUpgradePolicy.canUpgradeLevel(users.get(2))).isFalse();
assertThat(userLevelUpgradePolicy.canUpgradeLevel(users.get(3))).isTrue();
assertThat(userLevelUpgradePolicy.canUpgradeLevel(users.get(4))).isFalse();
}
@Test
void upgradeLevel() {
userLevelUpgradePolicy.upgradeLevel(users.get(1));
assertThat(users.get(1).getLevel()).isEqualTo(Level.SILVER);
userLevelUpgradePolicy.upgradeLevel(users.get(3));
assertThat(users.get(3).getLevel()).isEqualTo(Level.GOLD);
}
}
테스트 코드는 기존과 바뀐게 없다. 이로써 아래와 같이 MailSender 인터페이스를 핵심으로 하는 메일 전송 서비스 추상화 구조가 아래와 같이 구성되었다.
추상화 구조 UML
4.4. 테스트
테스트가 성공했을 때 메일 발송은 되지 않는 걸 확인할 수 있을 것이다.
5. 테스트 대역
5.1. 테스트 대역이란?
그런데 사실 이제까지 작성한 테스트 코드는 문제점이 하나 있다. 바로 테스트의 범위이다. UserServiceTest 클래스의 경우 UserService 클래스의 메서드를 테스트하는 코드이다. 하지만 그와 동시에 의존하는 UserLevelUpgradePolicy의 실제 로직도 수행된다. 사실 UserServiceTest 클래스의 관심사는 오로지 UserService 클래스의 로직이어야 한다. 의존하는 객체에 대해서는 그 클래스의 Test 코드에서 수행하는게 맞다.
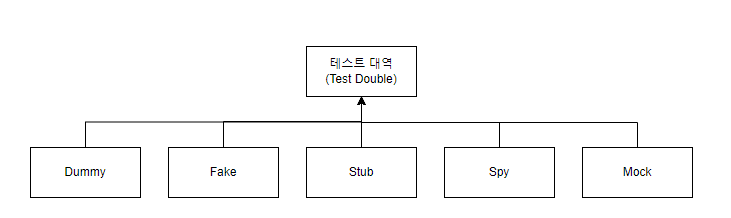
테스트 대상 오브젝트에는 여러 의존 오브젝트들이 있을 수 있다. 이때에는 의존 오브젝트에 대한 '대역' 역할을 하는 오브젝트를 만들어 테스트가 이상없이 동작되도록 해야한다. 이러한 오브젝트들을 테스트 대역(test double) 이라고 한다.
5.2. 테스트 대역의 종류
테스트 대역의 종류
5.2.1. Dummy
아무런 동작을 하지 않는 테스트 대역이다. 인스턴스화된 객체는 필요하지만 기능은 굳이 필요없는 경우에 사용한다. 앞서 생성한 DummyMailSender가 Dummy에 속한다.
public class DummyMailSender implements MailSender{
@Override
public void send(SimpleMailMessage simpleMessage) throws MailException {
}
@Override
public void send(SimpleMailMessage... simpleMessages) throws MailException {
}
}
5.2.2. Fake
동작은 하지만, 실제 동작 방식과 다르게 구현하는 테스트 대역이다. DB 데이터 처리를 Fake로 만들고자 한다면 Repository 인터페이스에 대한 구현체 클래스를 만들고 내부에 ArrayList와 같은 멤퍼 필드를 생성하여 인메모리로 관리할 수 있다. 즉, DB가 아닌 다른 방식으로 구현하는 것이다.
아래는 데이터를 실제 DB가 아닌 인메모리에 저장한 list로 처리하도록 구현한 예이다.
public class FakeUserDao implements IUserDao{
private final List<User> list = new ArrayList<>();
@Override
public void add(User user) {
list.add(user);
}
@Override
public void deleteAll() {
list.clear();
}
@Override
public User get(String id) {
return list.stream()
.filter(user -> id.equals(user.getId()))
.findFirst()
.get();
}
@Override
public int getCount() {
return list.size();
}
...
}
5.2.3. Stub
Dummy 객체가 실제로 동작하는 것처럼 구현하는 테스트 대역이다. 어떤 메서드를 호출했을 때 반환 값이 없을 경우 Dummy를 사용해도 되지만, 반환 값이 있거나 네거티브 테스트로 인해 예외를 발생시켜야 할 경우에는 기존 Dummy 객체에 의도한 동작을 구현해줘야 한다.
아래는 ID가 100인 사용자 정보를 요청할 경우 RuntimeException을 발생시키고, 그 외에는 무조건 테스터 유저에 대한 픽스처를 생성 후 리턴하는 예이다.
public class StubUserDao implements IUserDao{
...
@Override
public User get(String id) {
if("100".equals(id)){
throw new RuntimeException("삭제된 ID입니다.");
}
return new User("1", "테스터","비밀번호", Level.BASIC,0 ,0,"test@naver.com");
}
...
}
5.2.4. Spy
기본적으론 실제 오브젝트처럼 동작한다. 대신, 원하는 메서드에 Stubbing 처리를 하여 응답을 미리 지정할 수 있다. 즉, Subbing이라는 스파이를 지정할 수 있는 테스트 대역이다. mockito 라이브러리에서 제공하는 SpyBean 어노테이션을 사용하면 쉽게 구현할 수 있다.
아래는 upgradeLevel() 메서드 호출 시 users.get(3)에 대해서만 RuntimeException을 발생시키고, 나머지는 실제 로직을 수행시키도록 하는 예이다. given 메서드를 사용하여 upgradeLevel에 대한 Stub를 지정하고 있다.
@SpyBean
DefaultUserLevelUpgradePolicy spyUserLevelUpgradePolicy;
...
@Test
@DisplayName("레벨업 처리 도중 예외 발생 테스트")
void exceptionDuringLevelUp(){
...
// users.get(3) 오브젝트로 upgradeLevel 메서드를 호출하면 RuntimeException을 발생시키도록 Stubbing
given(spyUserLevelUpgradePolicy.upgradeLevel(users.get(3))).willThrow(new RuntimeException());
/* upgradeLevels 메서드 내부에서 spyUserLevelUpgradePolicy.upgradeLevel()를 호출하고 있음.
* users.get(0), users.get(1), users.get(2)에 대한 매개변수로 호출 시 실제 로직이 실행되나,
* users.get(3) 으로 호출 시 RuntimeException이 발생함.
*/
userService.upgradeLevels();
...
}
5.2.5. Mock
가짜 객체를 만든 후 Stubbing을 통해 미리 명세를 정의해 놓은 대역을 말한다. Stub와 다른 점은 메서드의 리턴 값으로는 판단할 수 없는 행위를 검증할 수 있다는 점이다. 예제에서는 리턴 값이 없어 메일 발송 내역 확인이 어려운 DummyMailSender 클래스 대신 발송 내역을 확인할 수 있는, 즉 어떤 행위를 했는지를 명확히 검증하기 위해 MockMailSender 클래스를 생성하였다. 테스트 코드에서는 requests를 조회한 후 누구에게 발송했는지를 확인할 수 있다.
public class MockMailSender implements MailSender {
private final List<String> requests = new ArrayList<>();
@Override
public void send(SimpleMailMessage simpleMessage) throws MailException {
requests.add(simpleMessage.getTo()[0]);
}
@Override
public void send(SimpleMailMessage... simpleMessages) throws MailException {
}
public List<String> getRequests(){
return requests;
}
}
추가로 mockito 라이브러리에서 제공하는 기능 중 Mock 객체에 대해 특정 메서드를 어떤 파라미터로 호출 했는지를 검증할 수 있는 기능을 활용할 수 있다. 아래의 경우 userService.upgradeLevels() 내부에서 호출되는 mockUserLevelUpgrdePolicy라는 Mock 객체에 대해 users.get(3)을 파라미터로 하여 upgradeLevel 메서드가 호출됐는지를 확인한다. 이처럼 Mock은 상태 뿐 아닌 행위까지 검증할 수 있다.
정기 사용자 레벨 관리 작업을 수행하는 도중 네트워크가 끊기거나 중간 로직에서 예외가 발생한다면, 그때까지 변경된 사용자의 레벨은 그대로 둘까? 모두 롤백할까?
당연히 모두 롤백해야 한다. 일부 사용자만 레벨이 조정됐다면 사용자의 반발이 우려되기 때문이다. 롤백 후 다시 일정을 잡아 해당 작업을 수행해야 한다. 현재 JdbcTemplate을 사용해 정기 사용자 레벨 관리 작업에 대한 데이터 처리 작업을 하고있다. 작업 중간에 예외가 발생했을때 실제로 모두 롤백이 되는지 확인해보고, 롤백이 되지 않는다면 원인을 파악해보자.
2. 롤백 테스트
2.1. 테스트 케이스
정기 사용자 레벨 관리 작업은 모든 유저 조회, 레벨업 조건 만족 여부 체크, 레벨업 데이터 처리 과정을 거친다. 이에따라 조건을 만족하는 N개의 유저 픽스처를 미리 생성한 후 조건을 만족하는 특정 유저에 대해 레벨업 처리 데이터 처리 시 RuntimeException을 발생시키도록 하는 테스트 케이스를 구현하였다.
교재에서는 서비스 클래스를 상속받고, 특정 유저 ID로 레벨 업 처리 시 예외가 발생하도록 하였으나, 필자는 실제 로직은 건들고 싶지 않아 테스트 코드만으로 처리하였다.
2.2. 테스트 코드
@Autowired
UserService userService;
@SpyBean
DefaultUserLevelUpgradePolicy spyUserLevelUpgradePolicy;
@SpyBean
IUserDao spyUserDao;
List<User> users; // 테스트 픽스처
@BeforeEach
void setUp(){
users = Arrays.asList(
new User("test1","테스터1","pw1", Level.BASIC, 49, 0),
new User("test2","테스터2","pw2", Level.BASIC, 50, 0),
new User("test3","테스터3","pw3", Level.SILVER, 60, 29),
new User("test4","테스터4","pw4", Level.SILVER, 60, 30),
new User("test5","테스터5","pw5", Level.GOLD, 100, 100),
new User("test6","테스터6","pw6", Level.PLATINUM, 100, 100)
);
}
@Test
@DisplayName("레벨업 처리 도중 예외 발생 테스트")
void exceptionDuringLevelUp(){
userService.setUserLevelUpgradePolicy(spyUserLevelUpgradePolicy); // spyBean 설정
// Stubbing : userDao.getAll() 호출 시 users 리턴
given(spyUserDao.getAll()).willReturn(users);
// Stubbing : 네번째 유저에 대한 레벨업 메서드 호출 시 RuntimeException 발생
given(spyUserLevelUpgradePolicy.upgradeLevel(users.get(3))).willThrow(new RuntimeException());
// 모든 유저 삭제
spyUserDao.deleteAll();
// 유저 등록
users.forEach(user -> spyUserDao.add(user));
// 정기 레벨업 작업
userService.upgradeLevels();
checkLevelUpgraded(users.get(1),false);
checkLevelUpgraded(users.get(3),false);
}
private void checkLevelUpgraded(User user, boolean upgraded){
User userUpdate = userDao.get(user.getId());
if(upgraded){
assertThat(userUpdate.getLevel()).isEqualTo(user.getLevel().getNexeLevel());
}else{
assertThat(userUpdate.getLevel()).isEqualTo(user.getLevel());
}
}
...
네번째 유저에 대해 RuntimeException이 발생하도록 하고, checkLevelUpgraded 메서드를 통해 유저의 레벨 업 여부를 체크한다. 첫번째 파라미터는 체크할 유저, 두번째 파라미터는 레벨업 여부이다. 만약 users.get(1) 유저가 레벨업이 된다면 테스트는 실패할 것이다.
2.3. 테스트 결과
users.get(1) 유저가 레벨업 되었기때문에 테스트는 실패했다. 이로써 기본적인 jdbcTemplate을 사용할 경우 중간에 예외가 발생해도 롤백이 되지 않는다는 사실을 알게 되었다.
3. 롤백이 되지 않는 이유
3.1. 트랜잭션
그렇다면 롤백이 되지 않는 이유는 뭘까? 바로 트랜잭션 때문이다. 모든 사용자의 레벨을 업그레이드하는 작업인 upgradeLevels() 메서드가 하나의 트랜잭션 안에서 동작하지 않았기 때문이다.
트랜잭션이란? 데이터베이스의 상태를 변화시키는 하나의 논리적 기능을 수행하기 위한 작업의 단위를 말한다.
만약 upgradeLevels()이 하나의 트랜잭션으로 구성되었다면 '하나의 트랜잭션은 모두 성공하거나 또는 모두 실패해야한다'는 트랜잭션 원자적 성질에 따라 모두 실패했겠지만, 여러개의 트랜잭션으로 구성되었기 때문에 모두 롤백될 수가 없었다. 결국 이를 해결하기 위해서는 트랜잭션의 원자적 성질을 적용시키기 위해upgradeLevels() 메서드에서 일어나는 모든 데이터 처리에 대해 하나의 트랜잭션으로 구성되도록 설정해야한다. 아래와 같이 말이다.
public void upgradeLevels() {
// 트랜잭션 시작
// 비지니스 로직(모든 유저 조회, 레벨업 조건 만족 여부 체크, 레벨업 처리)
// 트랜잭션 종료
}
3.2. JdbcTemplate의 트랜잭션
JdbcTemplate의 메서드 호출 한번에 한 개의 DB 커넥션이 만들어지고 닫힌다. 일반적으로 트랜잭션은 커넥션보다도 존재 범위가 짧은데, 템플릿 메서드가 호출될 때마다 트랜잭션이 만들어지고, 메서드를 빠져 나오기 전에 종료되게 된다. 즉, jdbcTemplate의 메서드를 사용하는 UserDao는 각 메서드마다 하나의 독립적인 트랜잭션으로 실행되었기 때문에 롤백이 되지 않았던 것이다.
아래는 JdbcTemplate 메서드 실행 시 호출되는 execute 메서드이다. Connection이 생성되고, 반환되는 것을 확인할 수 있다.
그런데 조금 특이한 부분이 있다. 일반적으로 Connection을 생성할 때는 DataSource 객체를 사용하는데 여기서는 DataSourceUtils 객체를 사용하여 호출하고 있다. 이에 대해 구글링하니 다음과 같은 답변을 찾아볼 수 있었다.
DataSource.getConnection() 는 DataSource 또는 연결 풀에서 얻은 새 연결을 반환합니다. DataSourceUtils.getConnection() 현재 스레드에 대한 활성 트랜잭션이 있는지 확인합니다. 있는 경우 활성 트랜잭션에 대한 Connection을 반환하고, 없을 경우 DataSource와 같은 방식으로 작동합니다.
스레드에 활성 트랜잭션이 있을 경우 이 트랜잭션에 대한 Connection을 사용한다는 뜻이다. JdbcTemplate 메서드 호출 시 무조건 새로운 Connection을 생성하지 않았다. 이 활성 트랜잭션을 활용하는 방법이 있는데 이게 바로 트랜잭션 동기화이다.
4. 트랜잭션 동기화
4.1. 트랜잭션 동기화란
스프링은 트랜잭션을 시작하기 위해 만든 Connection을 동기화 저장소에 보관해두고, 이후에 호출되는 다른 메서드에서 Connection을 사용해야 할 경우 저장된 Connection을 가져다 사용하게 하여 하나의 트랜잭션으로 관리할 수 있는 방법을 제공한다. 이를 트랜잭션 동기화라고 한다.
4.2. 트랜잭션 동기화 적용
스프링은 멀티스레드 환경에서도 안전하게 트랜잭션을 동기화하는 기능을 지원한다. TransactionSynchronizationManager와 앞서 찾아보았던 DataSourceUtils이다.
TransactionSynchronizationManager를 이용해 트랜잭션 동기화 작업을 초기화하도록 요청하고, DataSourceUtils에서 제공하는 getConnection() 메서드를 통해 DB 커넥션을 생성한다. DataSource에서 Connection을 직접 가져오지 않고, 이를 이용하는 이유는 Connection 오브젝트를 생성해줄 뿐만 아니라 트랜잭션 동기화에 사용하도록 저장소에 바인딩해주기 때문이다.
트랜잭션 동기화가 되어 있는 채로 JdbcTemplate을 사용하면 JdbcTemplate 메서드 호출 시 동기화시킨 Connection을 사용하게 된다. 즉, upgradeLevels() 에서 트랜잭션 동기화 작업을 한다면, 내부에서 호출되는 JdbcTemplate은 upgradeLevels()에서 만든 Connection을 사용하게 되어 하나의 트랜잭션으로 돌아가게 된다.
4.3. 코드 적용
DataSourceUtils 메서드에 필요한 dataSource를 사용하기 위해 수정자 메서드를 추가 및 DI 설정 후, 트랜잭션 동기화 로직을 추가하였다. 이제 테스트 코드를 통해 롤백이 되었는지 확인해보자. 아마 롤백이 되어 테스트가 성공할 것이다.
public class UserService {
...
private DataSource dataSource; // dataSource 추가
public void setDataSource(DataSource dataSource){ // dataSource 수정자 메서드 추가
this.dataSource = dataSource;
}
...
public void upgradeLevels() {
TransactionSynchronizationManager.initSynchronization(); // 동기화 작업
Connection c = DataSourceUtils.getConnection(dataSource); // 커넥션 생성 및 저장소 바인딩
try{
c.setAutoCommit(false);
List<User> users = userDao.getAll();
for(User user : users) {
if (userLevelUpgradePolicy.canUpgradeLevel(user)) {
userLevelUpgradePolicy.upgradeLevel(user);
}
}
c.commit();
}catch(Exception e){
try{
c.rollback();
}catch (SQLException ex){
e.printStackTrace();
}
}finally {
DataSourceUtils.releaseConnection(c, dataSource); // DB Connection close
TransactionSynchronizationManager.unbindResource(this.dataSource); // 트랜잭션 저장소에서 데이터소스 반환
TransactionSynchronizationManager.clearSynchronization(); // 동기화 작업 종료
}
}
5. 트랜잭션 서비스 추상화
그렇다면 2개 이상의 DB를 하나의 트랜잭션으로 묶을 수 있을까?
현재 방법으로는 불가능하다. 트랜잭션이 하나의 DB Connection에 종속되는 방식인 로컬 트랜잭션 방식을 사용하기 때문이다. 이 경우 별도의 트랜잭션 관리자를 통해 트랜잭션을 관리하는 글로벌 트랜잭션 방식을 사용해야 한다. 자바는 글로벌 트랜잭션을 지원하는 API인 JTA(Java Transaction API)를 제공한다.
하지만 다짜고짜 JTA를 적용하는 것도 문제가 된다. JTA를 적용하려면 서비스 로직이 수정되어야하는데 기존 로컬 트랜잭션 방식을 사용하는 경우 굳이 수정할 필요가 없기 때문이다.
스프링은 이러한 다른 트랜잭션 방식에 대해서도 추상화하여 사용할 수 있도록 트랜잭션 추상화 기술을 제공하고 있다. 이를 이용하면 로컬, 글로벌과 같은 트랜잭션 방식 뿐 아니라 JDBC, JPA, 하이버네이트 등과 같은 기술들의 각 트랜잭션 API를 이용하지 않고도 일관된 방식으로 트랜잭션 제어가 가능해진다.
5.1. PlatformTransactionManager
스프링이 제공하는 트랜잭션 처리를 위한 추상 인터페이스이다. JDBC의 로컬 트랜잭션을 이용한다면 PlatformTransactionManager를 구현한 DataSourceTransactionManager를 사용하고 JTA를 이용하는 글로벌 트랜잭션을 이용한다면 JTATransactionManager로 구현체를 바꿔 사용하면 된다.
5.2. DataSourceTransactionManager 적용
5.2.1) UserService.java
public class UserService {
private IUserDao userDao;
private PlatformTransactionManager transactionManager;
public void setTransactionManager(PlatformTransactionManager transactionManager){
this.transactionManager = transactionManager;
}
...
public void upgradeLevels() {
// DI 받은 트랜잭션 매니저를 공유해서 사용한다.
TransactionStatus status = transactionManager.getTransaction(
new DefaultTransactionDefinition()
);
try{
List<User> users = userDao.getAll();
for(User user : users) {
if (userLevelUpgradePolicy.canUpgradeLevel(user)) {
userLevelUpgradePolicy.upgradeLevel(user);
}
}
transactionManager.commit(status);
}catch(Exception e){
transactionManager.rollback(status);
}
}
public void add(User user) {
if(user.getLevel() == null){
user.setLevel(Level.BASIC);
}
userDao.add(user);
}
}
5.2.2) applicationContext.xml
<bean id = "userService" class = "org.example.user.service.UserService">
<property name="userDao" ref = "userDao"></property>
<property name="userLevelUpgradePolicy" ref = "userLevelUpgradePolicy"></property>
<property name="transactionManager" ref="transactionManager"></property>
</bean>
<bean id = "transactionManager" class ="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource"></property>
</bean>
...
필자의 경우 DataSource를 통한 로컬 트랜잭션 방식을 사용해야 하므로 transactionManager의 구현체 클래스를 DataSourceTransactionManager로 하는 Bean을 생성하였다. 해당 클래스 생성 시 dataSource가 필요하므로 property를 통해 주입시켰다.
2. 사용자가 처음 가입하면 BASIC 레벨이 되며 이후 활동에 따라 한단계씩 업그레이드 된다.
3. 가입 후 50회 이상 로그인을 하면 BASIC에서 SILVER 레벨이 된다.
4. SILVER 레벨이면서 30번 이상 추천을 받으면 GOLD 레벨이 된다.
5. 사용자의 레벨 변경 작업은 일정한 주기를 가지고 일괄적으로 진행된다. 작업 전에는 조건을 충족하더라도 레벨의 변경이 일어나지 않는다.
2.1. 상수는 Enum 클래스로
Level은 상수로 관리해야 하므로 상수 관리에 적합한 Enum 클래스로 관리한다. 교재에서는 DB에 정수 형태로 저장하기 위해 value 필드를 만들어 BASIC은 1, SILVER는 2, GOLD는 3으로 관리하고 있다.
public enum Level{
GOLD(3),
SILVER(2),
BASIC(1);
private final int value;
Level(int value){
this.value = value;
}
public int intValue(){ // DB 저장 시 값을 가져오기 위한 메서드
return value;
}
public static Level valueOf(int value){ // value 값으로 레벨을 조회하는 메서드
switch (value){
case 1 : return BASIC;
case 2 : return SILVER;
case 3 : return GOLD;
default: throw new AssertionError("Unknown value : "+value);
}
}
}
2.2. User 필드 추가
유저의 레벨 관리를 위해 Level 타입의 멤버필드를 User 클래스에 추가한다. 또한 로그인, 추천 횟수 정보를 담을 login, recommend 도 추가한다.
public class User {
private String id;
private String name;
private String password;
private Level level;
private int login;
private int recommend;
public User(String id, String name, String password, Level level, int login, int recommend){
this.id = id;
this.name = name;
this.password = password;
this.level = level;
this.login = login;
this.recommend = recommend;
}
// getter, setter
}
2.3. 비지니스 로직은 Service로 관리
레벨 변경 작업은 레벨을 업그레이드 하기 위한 조건들을 체크하는 비지니스성 작업이다. 이러한 비지니스 로직은 Service 클래스로 관리해야한다. DAO 클래스는 DB 데이터를 가져오고 조작하는 작업을 담당한다. 만약 비지니스 로직 중 DB를 접근해야 하는 부분이 있다면, Service 클래스에서 DAO 클래스를 참조하는 형태가 되어야 한다. 테스트 코드도 구현한다고 가정하면 아래와 같은 형태의 UML로 구성된다.
Service를 추가한 UML
구현을 위해 UserService 클래스를 생성하고 조건을 체크하여 레벨을 업그레이드하는 upgradeLevels() 메서드를 생성하였다.
public class UserService {
private IUserDao userDao;
public void setUserDao(IUserDao userDao){ // userDao DI를 위한 메서드
this.userDao = userDao;
}
public void upgradeLevels() {
// 구현해야하는 비지니스 로직
}
}
2.4. upgradeLevels() 구현
레벨 업에 대한 비지니스 로직을 upgradeLevels() 메서드 안에 녹였지만 if, else if 구문 내용에 여러 관심이 섞여버리는 문제점이 있다.
1) 현재 레벨을 체크하는 user.getLevel() == Level.BASIC, user.getLevel() == Level.SILVER, 그와 함께 레벨 업 조건을 체크하는 user.getLogin() >= 50, user.getRecommend() >= 30.
기존 메서드는 자주 변경될 가능성이 있는 구체적인 내용이 추상적인 로직의 흐름과 함께 섞여있다.
* 추상적인 로직 - userDao.getAll(), userDao.update()
* 구체적인 내용 - 레벨 체크, 레벨 변경 등과 같은 비지니스 로직
구체적인 내용을 메서드화 하여 추상적으로 만들어보자.
...
public void upgradeLevels() {
List<User> users = userDao.getAll();
for(User user : users) {
if (canUpgradeLevel(user)) { // 업그레이드 가능 여부 체크
upgradeLevel(user); // 업그레이드 처리
}
}
}
이제 추상화한 메서드인 canUpgradeLevel과 upgradeLevel의 비지니스 로직을 구현한다.
private static final int MIN_LOGIN_COUNT_FOR_SILVER = 50;
private static final int MIN_RECOMMEND_FOR_GOLD = 30;
private boolean canUpgradeLevel(User user){
Level currentLevel = user.getLevel();
switch(currentLevel){
case BASIC: return (user.getLogin() >= MIN_LOGIN_COUNT_FOR_SILVER);
case SILVER: return (user.getRecommend() >= MIN_RECOMMEND_FOR_GOLD);
case GOLD: return false;
default: throw new IllegalArgumentException("Unknown Level :"+currentLevel);
}
}
private void upgradeLevel(User user){
if(user.getLevel() == Level.BASIC) user.setLevel(Level.SILVER);
else if(user.getLevel() == Level.SILVER) user.setLevel(Level.GOLD);
userDao.update(user);
}
canUpgradeLevel은 레벨 업 조건을 만족하는지 체크한다. 이전과는 다르게 switch case 문을 사용해 현재 사용자 레벨 체크와 레벨업 조건 체크를 분리하였다. 그리고 알수없는 레벨 값이 들어왔을 때에는 예외처리도 하고 있다.
upgradeLevel은 레벨 업 작업을 담당하는데 이 부분도 추상적인 로직과 비지니스 로직이 섞여있다. 유저의 레벨을 체크하는 부분, 유저의 레벨을 수정자 메서드로 set하는 부분이다.
또다른 문제점도 있다. 알수없는 레벨에 대한 예외 처리가 되어 있지 않으며, 레벨이 늘어나면 if문도 점점 늘어날 수 있다는 것이다.
2.6. upgradeLevel 리팩토링
1) 레벨 관리는 Level에서. (= 자기의 일은 스스로하자)
'다음 레벨 조회'에 대한 책임을 가진 클래스가 없기에 레벨 업을 위해 다음 레벨을 조회하는 로직이 if문 내 하드코딩으로 구현되어있다. 이에 대한 책임은 Level에서 갖도록 해야한다. 한단계 높은 레벨을 뽑아내는건 UserService가 하는것보다 Level 스스로 하는게 낫기 때문이다. 이제 다음 단계의 레벨이 무엇인지를 찾기 위해 if 조건식을 만들어서 비지니스 로직에 담을 필요가 없다.
public enum Level {
GOLD(3, null),
SILVER(2, GOLD),
BASIC(1, SILVER);
private final int value;
private final Level nextLevel;
Level(int value, Level nextLevel){
this.value = value;
this.nextLevel = nextLevel;
}
public Level getNextLevel(){
return this.nextLevel;
}
...
}
2) User의 변경 책임은 User에서 (= 자기의 일은 스스로하자)
User의 내부 정보를 변경하기 위해 UserService에서 user.setLevel()을 호출하고 있지만, 앞서 Level과 마찬가지로 User의 정보가 변경되는 것은 User 스스로 다루는 게 적절하다. UserService가 레벨 업그레이드 시에 user의 어떤 필드를 수정하는 로직을 갖고 있기보다는, User에게 레벨 업그레이드를 요청하는 편이 낫다.
public class User {
...
public void upgradeLevel(){
Level nextLevel = this.level.getNextLevel();
if(nextLevel == null){
throw new IllegalStateException(this.level +"은 업그레이드가 불가능합니다.");
}
this.level = nextLevel;
}
}
3) upgradeLevel() 리팩토링
위 두가지를 적용한 후 upgradeLevel() 메서드를 리팩토링하니 훨씬 간결하고 추상적인 메서드가 되었다.
3. 이벤트 기간에 한해 GOLD에서 PLATINUM으로 레벨업 가능하며 조건은 추천 횟수 100번이다.
3.1. UserLevelUpgradePolicy 인터페이스 구현
전략 패턴을 사용하기 위해 UserLevelUpgradePolicy 인터페이스를 구현하였다. 패키지는 뭘로할까 고민하다가 Service에서 사용되는 하나의 정책 속성이라고 생각하여 attribute라는 패키지를 만들어 구성하였다. 업그레이드 기능과 연관된 메서드인 canUpgradeLevel()과 upgradeLevel() 메서드를 인터페이스 메서드로 구성하였다.
UserLevelUpgradePolicy 를 상속받은 DefaultUserLevelUpgradePolicy 클래스를 만들고, 구현했던 로직을 이관시켰다. 레벨 업 조건이 바뀌었으므로 상수 값을 수정하였고, UserDao DI를 위한 수정자 메서드 추가, canUpgradeLevel에는 새롭게 추가될 등급인 PLATINUM도 추가하였다.
기본 정책에서 PLATINUM 레벨은 추가되지 않지만, 이벤트 기간 후 다시 기본 정책으로 돌아왔을 때 아래 클래스를 사용하게 될텐데, 이때 PLATINUM 조건이 없다면 canUpgradeLevel 메서드에서 예외가 발생할 것이기 때문에 해당 레벨도 switch 문에 추가하였다.
public class DefaultUserLevelUpgradePolicy implements UserLevelUpgradePolicy{
private IUserDao userDao;
private static final int MIN_LOGIN_COUNT_FOR_SILVER = 50;
private static final int MIN_RECOMMEND_FOR_GOLD = 30;
public void setUserDao(IUserDao userDao){
this.userDao = userDao;
}
public boolean canUpgradeLevel(User user){
Level currentLevel = user.getLevel();
switch(currentLevel){
case BASIC: return (user.getLogin() >= MIN_LOGIN_COUNT_FOR_SILVER);
case SILVER: return (user.getRecommend() >= MIN_RECOMMEND_FOR_GOLD);
case GOLD:
case PLATINUM:
return false;
default: throw new IllegalArgumentException("Unknown Level :"+currentLevel);
}
}
public void upgradeLevel(User user) {
user.upgradeLevel();
userDao.update(user);
}
}
3.3. 이벤트 레벨 업그레이드 정책 클래스 구현
UserLevelUpgradePolicy 를 상속받은 EventUserLevelUpgradePolicy 클래스를 만들었다. 레벨 업 조건이 바뀌었으므로 상수 값을 수정하였고, UserDao DI를 위한 수정자 메서드 추가, canUpgradeLevel에는 새롭게 추가될 등급인 PLATINUM도 추가하였다.
public class EventUserLevelUpgradePolicy implements UserLevelUpgradePolicy{
private IUserDao userDao;
private static final int MIN_LOGIN_COUNT_FOR_SILVER = 30;
private static final int MIN_RECOMMEND_FOR_GOLD = 20;
private static final int MIN_RECOMMEND_FOR_PLATINUM = 100;
public void setUserDao(IUserDao userDao){
this.userDao = userDao;
}
public boolean canUpgradeLevel(User user){
Level currentLevel = user.getLevel();
switch(currentLevel){
case BASIC: return (user.getLogin() >= MIN_LOGIN_COUNT_FOR_SILVER);
case SILVER: return (user.getRecommend() >= MIN_RECOMMEND_FOR_GOLD);
case GOLD: return (user.getRecommend() >= MIN_RECOMMEND_FOR_PLATINUM);
case PLATINUM: return false;
default: throw new IllegalArgumentException("Unknown Level :"+currentLevel);
}
}
public void upgradeLevel(User user) {
user.upgradeLevel();
userDao.update(user);
}
3.4. DI 설정 정보 수정
DI 설정 정보를 관리하는 DaoFactory 클래스에 UserLevelUpgradePolicy에 대한 Bean을 생성하고, UserService에서 이를 DI 받도록 구성하였다. 이제 이벤트 기간에는 UserLevelUpgradePolicy의 구현체 클래스를 EventUserLevelUpgradePolicy로 설정하면 된다.
@Configuration
public class DaoFactory {
@Bean
public UserDaoJdbc userDao(){
UserDaoJdbc userDaoJdbc = new UserDaoJdbc();
userDaoJdbc.setDataSource(dataSource());
return userDaoJdbc;
}
@Bean
public DataSource dataSource(){
SimpleDriverDataSource dataSource = new SimpleDriverDataSource();
dataSource.setDriverClass(com.mysql.jdbc.Driver.class);
dataSource.setUrl("jdbc:mysql://localhost/xxx");
dataSource.setUsername("test");
dataSource.setPassword("test");
return dataSource;
}
@Bean
public UserService userService(){
UserService userService = new UserService();
userService.setUserDao(userDao());
userService.setUserLevelUpgradePolicy(userLevelUpgradePolicy());
return userService;
}
@Bean
public UserLevelUpgradePolicy userLevelUpgradePolicy(){
DefaultUserLevelUpgradePolicy policy = new DefaultUserLevelUpgradePolicy();
policy.setUserDao(userDao());
return policy;
}
}
3.5. 테스트 코드
UserLevelUpgradePolicy 구현체에 대한 테스트 코드는 각각 생성하였다. 레벨업 조건이 다르기 때문에 테스트 픽스처와 조건 상수 수정이 필요했기 때문이다.
UserService에 대한 테스트 코드는 UserLevelUpgradePolicy 구현체에 따라 결과가 달라지므로 테스트 메서드 레벨에서 UserLevelUpgradePolicy 구현체를 분리하도록 구현하였다.
1) DefaultUserLevelUpgradePolicyTest.java
@ExtendWith(SpringExtension.class)
@ContextConfiguration(locations = "/test-applicationContext.xml")
class DefaultUserLevelUpgradePolicyTest {
@Autowired
IUserDao userDao;
DefaultUserLevelUpgradePolicy userLevelUpgradePolicy;
List<User> users; // 테스트 픽스처
public static final int MIN_LOGIN_COUNT_FOR_SILVER = 50;
public static final int MIN_RECCOMEND_FOR_GOLD = 30;
@BeforeEach
void setUp(){
userLevelUpgradePolicy = new DefaultUserLevelUpgradePolicy();
userLevelUpgradePolicy.setUserDao(userDao);
users = Arrays.asList(
new User("test1","테스터1","pw1", Level.BASIC, MIN_LOGIN_COUNT_FOR_SILVER-1, 0),
new User("test2","테스터2","pw2", Level.BASIC, MIN_LOGIN_COUNT_FOR_SILVER, 0),
new User("test3","테스터3","pw3", Level.SILVER, 60, MIN_RECCOMEND_FOR_GOLD-1),
new User("test4","테스터4","pw4", Level.SILVER, 60, MIN_RECCOMEND_FOR_GOLD),
new User("test5","테스터5","pw5", Level.GOLD, 100, 100)
);
}
@Test
void canUpgradeLevel() {
assertThat(userLevelUpgradePolicy.canUpgradeLevel(users.get(0))).isFalse();
assertThat(userLevelUpgradePolicy.canUpgradeLevel(users.get(1))).isTrue();
assertThat(userLevelUpgradePolicy.canUpgradeLevel(users.get(2))).isFalse();
assertThat(userLevelUpgradePolicy.canUpgradeLevel(users.get(3))).isTrue();
assertThat(userLevelUpgradePolicy.canUpgradeLevel(users.get(4))).isFalse();
}
@Test
void upgradeLevel() {
userLevelUpgradePolicy.upgradeLevel(users.get(1));
assertThat(users.get(1).getLevel()).isEqualTo(Level.SILVER);
userLevelUpgradePolicy.upgradeLevel(users.get(3));
assertThat(users.get(3).getLevel()).isEqualTo(Level.GOLD);
}
}
2) EventUserLevelUpgradePolicyTest.java
@ExtendWith(SpringExtension.class)
@ContextConfiguration(locations = "/test-applicationContext.xml")
class EventUserLevelUpgradePolicyTest {
@Autowired
IUserDao userDao;
EventUserLevelUpgradePolicy userLevelUpgradePolicy;
List<User> users; // 테스트 픽스처
private static final int MIN_LOGIN_COUNT_FOR_SILVER = 30;
private static final int MIN_RECOMMEND_FOR_GOLD = 20;
private static final int MIN_RECOMMEND_FOR_PLATINUM = 100;
@BeforeEach
void setUp(){
userLevelUpgradePolicy = new EventUserLevelUpgradePolicy();
userLevelUpgradePolicy.setUserDao(userDao);
users = Arrays.asList(
new User("test1","테스터1","pw1", Level.BASIC, MIN_LOGIN_COUNT_FOR_SILVER-1, 0),
new User("test2","테스터2","pw2", Level.BASIC, MIN_LOGIN_COUNT_FOR_SILVER, 0),
new User("test3","테스터3","pw3", Level.SILVER, 60, MIN_RECOMMEND_FOR_GOLD-1),
new User("test4","테스터4","pw4", Level.SILVER, 60, MIN_RECOMMEND_FOR_GOLD),
new User("test5","테스터5","pw5", Level.GOLD, 100, MIN_RECOMMEND_FOR_PLATINUM-1),
new User("test6","테스터6","pw6", Level.GOLD, 100, MIN_RECOMMEND_FOR_PLATINUM),
new User("test7","테스터7","pw7", Level.PLATINUM, 100, 120)
);
}
@Test
void canUpgradeLevel() {
assertThat(userLevelUpgradePolicy.canUpgradeLevel(users.get(0))).isFalse();
assertThat(userLevelUpgradePolicy.canUpgradeLevel(users.get(1))).isTrue();
assertThat(userLevelUpgradePolicy.canUpgradeLevel(users.get(2))).isFalse();
assertThat(userLevelUpgradePolicy.canUpgradeLevel(users.get(3))).isTrue();
assertThat(userLevelUpgradePolicy.canUpgradeLevel(users.get(4))).isFalse();
assertThat(userLevelUpgradePolicy.canUpgradeLevel(users.get(5))).isTrue();
assertThat(userLevelUpgradePolicy.canUpgradeLevel(users.get(6))).isFalse();
}
@Test
void upgradeLevel() {
userLevelUpgradePolicy.upgradeLevel(users.get(1));
assertThat(users.get(1).getLevel()).isEqualTo(Level.SILVER);
userLevelUpgradePolicy.upgradeLevel(users.get(3));
assertThat(users.get(3).getLevel()).isEqualTo(Level.GOLD);
userLevelUpgradePolicy.upgradeLevel(users.get(5));
assertThat(users.get(5).getLevel()).isEqualTo(Level.PLATINUM);
}
}
3) UserServiceTest.java
@ExtendWith(SpringExtension.class)
@ContextConfiguration(locations = "/test-applicationContext.xml")
class UserServiceTest {
@Autowired
UserService userService;
@Autowired
IUserDao userDao;
@Autowired
DefaultUserLevelUpgradePolicy defaultUserLevelUpgradePolicy;
@Autowired
EventUserLevelUpgradePolicy eventUserLevelUpgradePolicy;
List<User> users; // 테스트 픽스처
@BeforeEach
void setUp(){
users = Arrays.asList(
new User("test1","테스터1","pw1", Level.BASIC, 49, 0),
new User("test2","테스터2","pw2", Level.BASIC, 50, 0),
new User("test3","테스터3","pw3", Level.SILVER, 60, 29),
new User("test4","테스터4","pw4", Level.SILVER, 60, 30),
new User("test5","테스터5","pw5", Level.GOLD, 100, 100),
new User("test6","테스터6","pw6", Level.PLATINUM, 100, 100)
);
}
@Test
@DisplayName("업그레이드 레벨 테스트-DefaultUserLevelUpgradePolicy")
void upgradeLevelWithDefaultUserLevelUpgradePolicy(){
userService.setUserLevelUpgradePolicy(defaultUserLevelUpgradePolicy);
userDao.deleteAll();
users.forEach(user -> userDao.add(user));
userService.upgradeLevels();
checkLevelUpgraded(users.get(0),false);
checkLevelUpgraded(users.get(1),true);
checkLevelUpgraded(users.get(2),false);
checkLevelUpgraded(users.get(3),true);
checkLevelUpgraded(users.get(4),false);
checkLevelUpgraded(users.get(5),false);
}
@Test
@DisplayName("업그레이드 레벨 테스트-EventUserLevelUpgradePolicy")
void upgradeLevelWithEventUserLevelUpgradePolicy(){
userService.setUserLevelUpgradePolicy(eventUserLevelUpgradePolicy);
userDao.deleteAll();
users.forEach(user -> userDao.add(user));
userService.upgradeLevels();
checkLevelUpgraded(users.get(0),true);
checkLevelUpgraded(users.get(1),true);
checkLevelUpgraded(users.get(2),true);
checkLevelUpgraded(users.get(3),true);
checkLevelUpgraded(users.get(4),true);
checkLevelUpgraded(users.get(5),false);
}
@Test
@DisplayName("레벨이 할당되지 않은 User 등록")
void addWithNotAssignLevel(){
userDao.deleteAll();
User user = users.get(0);
user.setLevel(null);
userService.add(user);
checkLevelUpgraded(userDao.get(user.getId()), false);
}
@Test
@DisplayName("레벨이 할당된 User 등록")
void addWithAssignLevel(){
userDao.deleteAll();
User user = users.get(4);
userService.add(user);
checkLevelUpgraded(userDao.get(user.getId()), false);
}
private void checkLevelUpgraded(User user, boolean upgraded){
User userUpdate = userDao.get(user.getId());
if(upgraded){
assertThat(userUpdate.getLevel()).isEqualTo(user.getLevel().getNexeLevel());
}else{
assertThat(userUpdate.getLevel()).isEqualTo(user.getLevel());
}
}
}
4. 회고
상수는 enum으로 관리하고, 비지니스 로직은 Service, 데이터 조작은 DAO, 각 객체가 가진 내부정보(멤버필드)의 수정은 스스로 처리하도록 구현했다. 이론적으로는 숙지하고 있던 내용이었지만 실무에서는 객체 스스로 처리하도록 하는 작업을 많이 생략했던 것 같다. 비지니스 로직에만 집중했었기 때문이었다. 회사의 업무 롤도 분명 큰 영향이 있었지만, OOP 대해 깊히있게 이해하려 노력하지 않았던게 더 큰것 같다. 이번 기회를 통해 객체 스스로 처리하도록 구현하는 부분에 더 신경쓸 수 있게 된 것 같다.
스프링에 대해 어느정도 안다고 생각했지만, 모르는 부분도 너무 많다고 생각한다. 이를 바로잡기 위해 토비의 스프링을 공부하고 있는데, 공부하면 할수록 기초적이지만 중요한 내용들을 놓치고 있었구나 라는게 느껴진다.
일반적으로 비지니스 로직 개발만큼 예외처리에 투자하지 않는다. 무성의한 예외처리는 어플리케이션의 많은 버그를 낳을 수 있다. 올바른 예외처리 방법을 알아보자.
2. 초난감 예외처리
개발자들의 코드에서 종종 발견되는 초난감한 예외처리 케이스들이다.
2.1. 예외 블랙홀
예외 상황이 발생해도 이를 무시하고 블랙홀처럼 먹어버리는 케이스이다. 이 경우 아래 코드와 같이 IOException이 발생해도 try/catch 블록을 빠져나가 다음 로직을 계속 수행하게 된다. 이는 비지니스 로직이 스무스하게 흘러갔다는 착각을 가져올 수 있고, 버그를 야기할 수 있다.
try{
...
}catch(IOException e){
// 예외 꺼억
}
콘솔에 에러 메시지만 출력시키는 것도 예외 블랙홀이다. 출력시켜도 다음 로직을 수행하는건 마찬가지니까.
catch 블록으로 라이브러리가 던지는 예외들을 매번 throws로 선언하기 귀찮아 상위 클래스인 Exception 클래스를 throws하는 케이스이다. 예외는 이 메서드를 호출한 메서드로 던져지겠지만, 그 메서드에서도 throws하는 것을 반복할 가능성이 높다. 이러한 케이스는 발생할 예외에 대한 정보를 얻을 수 없다. throws Exception만 보고는 파일을 찾지 못한건지, DB 예외가 난건지, IO 예외가 난건지 알 수 없기 때문이다.
//AS-IS
public void test() throws IOException, FileNotFoundException {
... //CheckedException을 던지는 라이브러리 코드 사용 중
}
//TO-BE → 예외 처리따위 세탁기에 돌려버리자!
public void test() throws Exception {
... //CheckedException을 던지는 라이브러리 코드 사용 중
}
3. 예외의 종류 및 특징
예외를 어떻게 다뤄야할지를 알아보기 전, 예외의 종류와 특징을 알아보자. 자바에서 발생시킬 수 있는 예외는 크게 세 가지가 있다. Error, Checked Exception, UnCheckedException.
3.1. Error
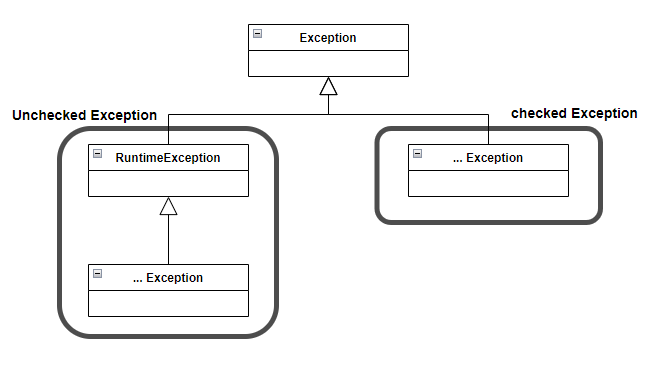
Error는 java.lang.Error 클래스의 서브 클래스들이다. Error는 OutOfMemory나 ThreadDeath와 같이 시스템에 비정상적인 상황 발생 시 사용된다. 자바 VM에서 발생시키는 것이므로 어플리케이션 코드에서 잡을 수 없다.
3.2. Checked Exception (체크 예외)
Exception은 Error와 달리 어플리케이션 코드 작업 중 예외상황이 발생했을 경우 사용된다. 이 Exception은 Checked Exception과 Unchecked Exception으로 구분된다. Checked Exception은 RuntimeException을 상속받지 않은 클래스, UnCheckedException은 RuntimeException을 상속한 클래스이다.
Exception의 구조
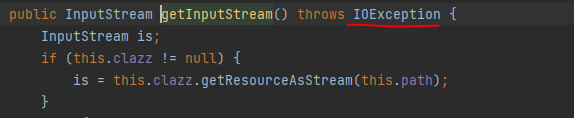
Checked Exception를 발생시키는 메서드를 사용할 경우 반드시 예외 처리 코드를 함께 작성해야 한다. 그렇지 않으면 컴파일 에러가 발생한다. 예를들어 예외를 처리하지 않고 getInputStream() 메서드 사용 시 IOException 예외가 처리되지 않았다는 컴파일 에러가 발생한다. 해당 메서드는 IOException 예외를 던지고 있고, IOException은 Exception을 상속받는다. 즉, IOException 는 Checked Exception 이기 때문에 예외 처리를 하지 않아 컴파일 에러가 발생하는 것이다.
RuntimeException 클래스를 상속한 예외들은 예외처리를 강제하지 않기때문에 언체크 예외라고 불린다. 대표적인 예로는 NullPointException이 있다.
3.4. 필자가 생각하는 둘의 구분점
필자가 생각하는 Checked Exception와 UncheckedException의 구분점은 대비책을 마련할 수 있냐 없냐로 생각한다.
예외 체크가 된다는 건 예외 발생이 예상 가능하단 뜻이고, 예상 가능하다는 건 대비책을 미리 마련해놓을 수 있다. 만약 어떤 문제가 발생했을 때 대비책을 마련할 가능성이 있다면, Checked Exception을 적용할 수 있다는 것이다. CheckedException이 트랜잭션 롤백을 하지 않는 이유도 예외 발생 시 적절한 대비책을 마련하여 복구할 가능성이 있기 때문이다.
반대로 UncheckedException은 대비책을 마련할 필요가 없거나 마련할 수 없다. 대표적인 예로 허용되지 않는 값을 사용해서 메서드를 호출할 때 발생하는 IllegalArugmentException이나, 할당하지 않는 레퍼런스 변수를 사용할 때 발생하는 NullPointException가 있는데 이는 모두 개발자의 실수와 부주의로 발생한다. 이는 어디에서든 일어날 수 있다. 만약 이러한 예외에 대해서도 대비해야 한다면, 모든 코드에 try, catch나 thrwos와 같은 예외처리 방법을 사용해야 할것이다. 이러한 예외들은 그 범위가 매우 방대하므로 대비책을 마련할 필요성이 없다.
필자의 팁 만약 Checked Exception과 Unchcked Exception이 잘 구분되지 않는다면, 전자는 컴파일 단계에서 체크(check)하는 Exception이므로 Checked Exception, 후자는 컴파일 단계에서 체크하지 않고(Unchecked) 런타임(Runtime)시 발생할 수 있으므로 UncheckedException이라고 이해해 보는건 어떨까요?
4. 예외처리 방법
이제 예외 처리 방법에 대해 알아보자. 방법으로는 예외 복구, 예외처리 회피, 예외 전환이 있다.
4.1. 예외 복구
말 그대로 예외를 복구하는 방법이다. 여기서의 복구란 '예외 상황을 파악하고, 문제를 해결해서 정상 상태로 돌려놓는 것'이다. 정상 상태로 가는 다른 작업 흐름으로 유도하는 것도 예외 복구로 해석한다.
예를들어 사용자가 요청한 파일이 없을 경우 IOException이 발생할 것이다. 이 때 사용자에게 문제 상황에 대한 에러 메시지를 뿌려주고, 다른 파일을 이용하도로 안내하는 것도 예외 복구이다.
네트워크가 불안정한 A 시스템은 원격지에 위치한 DB 서버 접속 시 실패하여 SQLException이 종종 발생한다. 이 경우 일정 시간 대기했다가 재 접속을 시도하는 방법을 통해 예외 복구를 시도할 수 있다.
int maxretry = 5;
while(maxretry -- > 0){
try{
//예외 발생 가능성이 있는 코드
}catch(Exception e){
//로그 출력 및 정해진 시간만큼 대기
}finally {
//리소스 반납 및 정리작업
}
}
throw new InternalException("에러가 발생하였습니다.");
예외 처리를 강제하는 Checked Exception들은 예외를 어떤 식으로든 복구할 가능성이 있는 경우에 사용한다. API를 사용하는 개발자로 하여금 예외가 발생할 수 있음을 인식하도록 도와주고, 적절한 복구를 시도해보도록 요구하는 것이다.
4.2. 예외처리 회피
예외 처리를 자신이 담당하지 않고 자신을 호출한 쪽으로 던져버리는 방법이다. 메서드 시그니처에 throws 문으로 선언하거나, catch 문으로 예외를 잡은 후 로그따위를 남기고 예외를 던지는 것이다.
public static void exceptionEvasion() throws SQLException{
try{
/// JDBC API
throw new SQLException();
}catch(SQLException e){
throw e;
}
}
JdbcTemplate에서 사용하는 콜백 오브젝트는 ResultSet이나 Statement 등을 이용해서 작업하다 발생하는 SQLException을 자신이 처리하지 않고 외부로 던진다. 그래서 콜백 오브젝트의 메서드는 모두 throws SQLException이 붙어있다. 예외를 처리하는 일은 템플릿의 역할이라고 보기 때문이다.
하지만 콜백과 템플릿처럼 긴밀한 관계가 아니라면 자신의 코드에서 발생하는 예외를 그저 던지는 건무책임한 책임회피일 수 있다. 때문에긴밀한 관계가 아니라면 자신을 사용하는 쪽에서 예외를 처리하는게 좋다.
JdbcTemplate.update 메서드
4.3. 예외 전환
예외를 다른 예외로 전환하는 방법이다. 전환을 사용하는 두가지 상황이 있다.
첫째, 발생된 예외가 그 예외 상황에 대해 적절한 의미를 부여하지 못할 때이다. 예를들어 회원 가입 시 아이디가 중복될 경우 DB 에러가 발생하면 SQLException이 발생한다. 이때 아래와 같이 예외를 외부로 던진다면, 이를 호출한 메서드에서는 SQLException 발생원인을 알기 어렵다.
// 회원가입 메서드를 호출하는 메서드
public static void requestJoin(User user){
try{
join(user);
}catch(SQLException e){
// 예외 처리를 해야하는데, SQLException이 왜 발생한거지? 내부 로직을 확인해봐야겠다..
}
}
// 회원가입 메서드
public static void join(User user) throws SQLException{
// 1. 회원가입 로직 ...
// 2. ID, PW 정보 DB INSERT 시 ID 중복(무결정 제약조건 위배)되어 SQLException 발생
// 3. 메서드 시그니처의 throws SQLException 을 통해 예외 throw
}
requestJoin 메서드를 보는 개발자 입장에서는 join 메서드에서 SQLException이 발생한다는 건 알 수 있으나 ID가 중복되어 발생했다는 건 바로 알수 없다. SQLException만으로는 ID가 중복으로 인한 예외의 의미를 부여하지 못하기 때문이다. 이때 예외 전환을 사용한다면 다음과 같이 변경할 수 있다.
// 회원가입 메서드를 호출하는 메서드
public static void requestJoin(User user){
try{
join(user);
}catch(DuplicateUserIdException e){ // ID 중복이 발생할 수 있구나!
// 예외 처리
}
}
// 회원가입 메서드
public static void join(User user) throws DuplicateUserIdException{
try{
// 1. 회원가입 로직 ...
// 2. ID, PW 정보 DB INSERT 시 ID 중복(무결정 제약조건 위배)되어 SQLException 발생
}catch(SQLException e){
throw new DuplicateUserIdException(e); // 3. DuplicateUserIdException 예외 throw
}
}
이때는 DuplicationUserIdException 예외 자체가 ID 중복의 의미를 담고 있기 때문에 개발자도 예외 원인을 한눈에 파악할 수 있다.
둘째, checked Exception을 UncheckedException으로 바꿀때(혹은 포장할 때)이다.
try{
OrderHome orderHome = EJBHomeFactory.getInstance().getOrderHome();
Order order = orderHome.findByPrimaryKey(Integer id);
}catch(NamingException ne){
throw new EJBException(ne);
}catch(SQLException se){
throw new EJBException(se);
}catch(RemoteException re){
throw new EJBException(re);
}
위 코드에서 EJBException은 런타임 예외(Unchekced Exception) 이고 나머지 예외는 Checked Exception이다. 런타임 예외의 큰 특징 중 하나는 시스템 오류로 판단하고 트랜잭션을 자동으로 롤백해주는 것이다. 이 코드는 단순히 런타임 예외로 포장만 했지만, 트랜잭션 롤백 처리도 하게 되었다. 또한, 위 메서드를 호출하는 다른 메서드에서는 EJBExceptoin에 대한 예외를 처리할 필요가 없으니 메서드의 시그니처나 로직이 변경될 필요가 없다.변경에 닫혀있으니 OCP를 잘 따른다고 할 수 있다.
5. 예외 처리 전략
이러한 예외 처리 방법을 통해 어떤 형식의 예외 처리 전략을 가져가야 할지 알아보자.
5.1. 런타임 예외를 보편적으로 사용하자
체크 예외가 발생할 경우 사실상 예외를 복구하는 것보다 해당 요청의 작업을 취소하고 개발자에게 통보하는 편이 낫다. 대게 체크 예외는 복구가 불가능한 상황이 많기 때문이다. 실제로 자바의 환경이 서버로 이동하면서 체크 예외의 활용도가 떨어지고 있으며 프레임워크에서도 API가 발생시키는 예외를 체크 예외 대신 런타임 예외로 정의하는 것이 일반화 되고 있다. OCP나 트랜잭션 등 앞서 알아본 런타임 예외의 이점을 생각해봤을 때 예외는 런타임 예외로 정의하는 것이 보편적이다.
5.2. 체크 예외는 런타임 예외로 전환하자.
체크 예외가 발생할 경우 런타임으로의 예외로 전환/포장하는 방법을 적절히 사용하자. 아래와 같이 SQLExcetion이라는 체크 예외 발생할 경우 예외 클래스의 에러 코드를 통해 ID 중복으로 발생한 예외인지를 체크할 수 있다. 이렇게 체크한 후 DuplicationUserIdException() 따위의 런타임 예외로 전환/포장하는 전략을 사용하자. 이렇게 되면 의미있는 클래스를 통해 예외 처리가 가능하며, 외부에서는 이 예외에 대한 처리를 신경쓰지 않아도 된다.
public static void join(User user) throws DuplicateUserIdException{
try{
// 1. 회원가입 로직 ...
// 2. ID, PW 정보 DB INSERT 시 ID 중복(무결정 제약조건 위배)되어 SQLException 발생
}catch(SQLException e){
if(e.getErrorCode() == MysqlErrorNumbers.ER_DUP_ENTRY){
throw new DuplicateUserIdException(e); // 예외 포장/전환
}else{
throw new RuntimeException(e); // 예외 포장
}
}
}
6. 애플리케이션 예외
애플리케이션 자체의 로직에 의해 의도적으로 발생시키는 예외를 말한다. 예를들어 사용자가 요청한 금액을 출금하는 메서드는 요청한 금액보다 잔고가 많을 경우에만 출금이 가능하다. 반대 상황일 때에는 애플리케이션 로직에서 의도적으로 예외를 발생시킨 후 사용자에게 잔고가 부족하다는 등의 메시지를 전달해야 한다. 아래 코드가 그 예이다.
try{
BigDecimal balance = account.withdraw(amount);
// 정상적인 처리 결과를 출력하도록 진행
}catch (InsufficientBalanceException e){ // Checked Exception
// InsufficientBalanceException에 잔고금액 정보를 가져옴
BigDecimal availFunds = e.getAvailFunds();
// 잔고부족 안내 메시지를 준비하고 이를 출력하도록 진행
}
InsufficientBalanceException은 Checked Exception으로 생성하였는데, 위와 같이 예외를 복구하는 로직을 강제하여 추가하기 위함이다.
7. JdbcTemplate의 SQLException
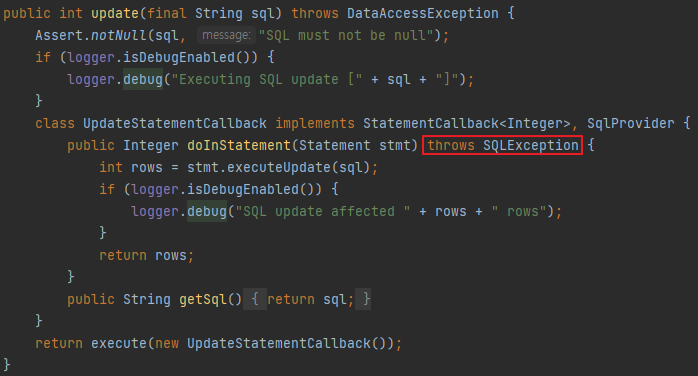
예제 코드인 UserDao를 보면 스프링에서 제공하는 JdbcTemplate를 도입을 하면서 SQLException에 대한 예외 처리(예외 회피) 코드인 throws SQLException 구문이 모두 사라진 것을 알 수 있었다. SQLException에 대한 예외처리를 하지 않아도 컴파일 에러가 발생하지 않는 상황이다. SQLException은 ChekcedException이니 예외 처리가 강제되어야 하는데 말이다.
호출하는 메서드를 확인해보니 콜백 오브젝트에서도 throws SQLException을 통해 예외를 던지고 있다. 이상하다고 생각했지만, 앞서 배운 내용을 적용하니 이유를 알 수 있었다.
JdbcTemplate.update에서 SQLException을 throws 하고있음deleteAll 메서드에서 SQLException에 대한 예외처리를 하지 않음.
* SQLException은 복구가 가능한가?
먼저 SQLException은 예외 복구가 가능할까? SQL 문법이 틀리거나, 제약조건을 위배하거나, DB 커넥션이 끊기는 등 다양한 이유로 발생하는 대부분의 예외들은 예외 복구가 불가능하다. 그렇기에 현업에서도 이러한 예외 처리는 에러 로그를 남기고 예외에 대한 메시지를 사용자에게 알려주는 방식으로 처리되었다. 그래서인지 이 메서드들은 콜백 메서드에선 SQLException을 던지고 있지만, 예외 전환/포장 전략을 사용하여 DataAccessException이라는 런타임 예외로 변환하여 던지고 있다.
아래 update 메서드에서 콜백 객체 생성 후 execute() 메서드를 호출하는데 update() 메서드의 throws를 보면 DataAccessException을 던지고 있다.
JdbcTemplate.update에서 SQLException을 throws 하고있음
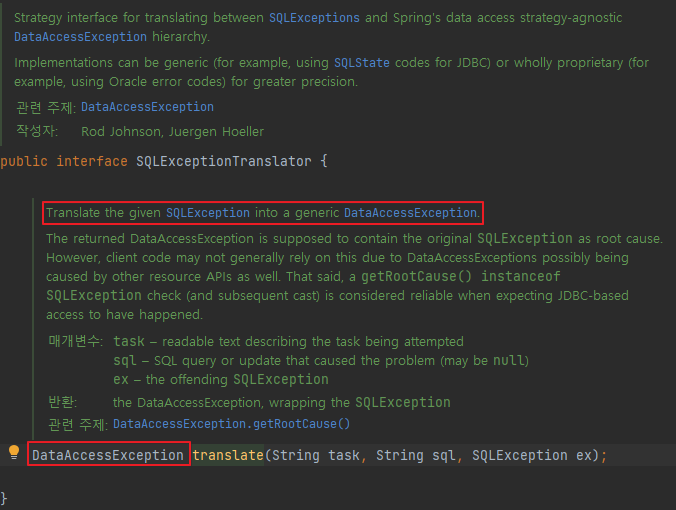
호출되는 execute 메서드에 SQLException 예외를 처리하는 부분이 있는데, getExceptionTranslator().translate() 메서드를 호출한 결과를 throw 하는 것을 볼 수 있다.
JdbcTemplate.execute 메서드
그리고 이 메서드가 SQLException을 DataAccessException으로 전환해주고 있었다. 즉 Checked Exception을 RuntimeException으로 전환하는 예외 전환을 사용하고 있고, RuntimeException은 예외처리 강제성이 없으므로 예외처리를 하지 않았던 것이다.
이 외에 다른 메서드들이나, 스프링에서 제공하는 API 메서드들도 대부분 런타임 예외를 사용하고 있다.
SQLExceptionTranslator.translate 메서드 시그니처
Translate the given SQLException into a generic DataAccessException. = 주어진 SQLException을 일반 DataAccessException으로 변환합니다
정리하면, 콜백 오브젝트 메서드에서 발생한 Checked Exception을 Runtime Exception으로 예외 전환/포장하는 전략을 사용하여 외부로 던지고 있기 때문에 SQLException에 대한 예외처리가 강제되지 않고, 메서드 사용 시 예외처리를 신경쓸 필요도 없게 되었다.
DataAccessException DataAccessExceptoin 는 런타임 예외중 하나로, 자바의 다양한 데이터 액세스 기술을 사용할 때 발생하는 예외들을 추상화한 것들을 계층구조 형태로 모아놓은 클래스이다. 이 클래스는 단순 SQLException을 전환하는 용도로만 사용되는 건 아니다. JDBC 뿐 아니라 JPA, 하이버네이트와 같은 ORM에서 발생하는 예외들도 이 클래스의 계층구조에 관리되어 있다. 예를들어 JDBC, JPA, 하이버네이트에 상관없이 데이터 액세스 기술을 부정확하게 사용했을 때는 InvalidDataAcessResourceUsageException 예외가 던져진다. 이는 각각 또 다른 예외로 세분화된다.
8. 기술에 독립적인 UserDao 만들기
8.1. 인터페이스 적용
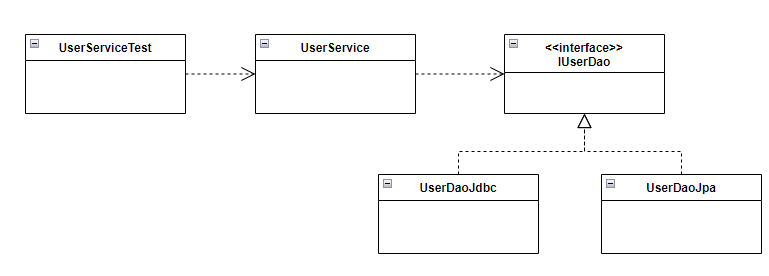
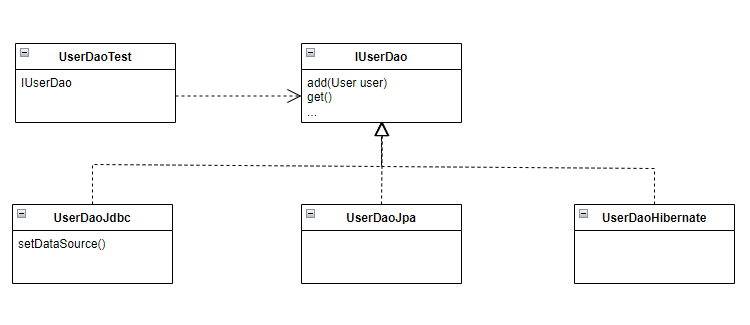
JDBC나 JPA와 같은 DB 데이터 처리 기술에 독립적인 UserDao를 만들기 위해 작성했던 UserDao 클래스를 인터페이스와 구현클래스로 분리해보자. 인터페이스는 접두사에 I를 붙여 만들고, 기존 UserDao 이름을 UserDaoJdbc로 변경하자. 나중에 JPA로 구현한다면 UserDaoJpa라고 이름을 붙일 수 있다. 인터페이스 분리를 통해 변경되고 생성된 코드들은 다음과 같다.
8.1.1. IUserDao.java
public interface IUserDao {
public void add(User user);
public void deleteAll();
public User get(String id);
public int getCount();
public List<User> getAll();
}
8.1.2. UserDaoJdbc.java
public class UserDaoJdbc implements IUserDao{
private JdbcTemplate jdbcTemplate;
private RowMapper<User> userMapper = new RowMapper<User>() {
public User mapRow(ResultSet rs, int rowNum) throws SQLException {
User user = new User();
user.setId(rs.getString("id"));
user.setName(rs.getString("name"));
user.setPassword(rs.getString("password"));
return user;
}
};
public void setDataSource(DataSource dataSource){
this.jdbcTemplate = new JdbcTemplate(dataSource);
}
public void add(final User user) {
jdbcTemplate.update("insert into users(id, name, password) values(?,?,?)",
user.getId(), user.getName(),user.getPassword());
}
public void deleteAll(){
jdbcTemplate.update("delete from users");
}
public User get(String id){
return jdbcTemplate.queryForObject("select * from users where id = ?", new Object[]{id},
userMapper);
}
public int getCount(){
return jdbcTemplate.queryForInt("select count(*) from users");
}
public List<User> getAll() {
return jdbcTemplate.query("select * from users order by id",
userMapper);
}
}
8.1.3 applicationContext.xml
...
<bean id = "userDaoJdbc" class = "org.example.user.dao.UserDaoJdbc">
<property name = "dataSource" ref = "dataSource"></property>
</bean>
8.1.4 UserDaoJdbcTest.java
class UserDaoJdbcTest {
private IUserDao userDaoJdbc; //인터페이스 형으로 변경
private User user1;
private User user2;
private User user3;
@BeforeEach
void setUp(){
ApplicationContext applicationContext = new GenericXmlApplicationContext("applicationContext.xml");
userDaoJdbc = applicationContext.getBean("userDaoJdbc", UserDaoJdbc.class); // userDaoJdbc 빈 조회
user1 = new User("test1","1234","테스터1");
user2 = new User("test2","12345","테스터2");
user3 = new User("test3","123456","테스터3");
}
...
이로써 UserDaoJdbc는 전략패턴을 사용하여 JDBC 기술에 독립된 클래스로 관리되었다.
UserDao 인터페이스 및 구현체 분리
8.2. 테스트
코드가 수정되었으니 테스트 코드를 실행시켜 단위 테스트를 진행해보자. 예제에서 ID 중복에 대한 테스트 코드를 추가하길래 JUnit5에 맞게 메서드를 만들어 주었다.
@Test
public void duplicateId(){
userDaoJdbc.deleteAll();
userDaoJdbc.add(user1);
assertThatThrownBy(()-> userDaoJdbc.add(user1)).isInstanceOf(DataAccessException.class);
}
9. 회고
Checked Exception과 UncheckedException을 사용하는 이유, OCP 관점에서 본 둘의 차이, 특징에 의거하여 체크 예외가 트랜잭션을 롤백하지 않는 이유, 예외처리 방법과 전략 등 예외에 대한 다양한 내용들을 알아보았다. 이 과정들을 스프링에서 제공하는 JdbcTemplate에 적용하니 이해가 훨씬 잘되었다. 출판한지 오랜된 책이지만 요즘 사람들의 입에 자주 언급될만큼의 가치들이 이런곳에서 나오는 것 같다.
예외 처리는 가벼히 여겨서는 안될 어플리케이션의 중요 요소 중 하나라고 생각한다. 이러한 코드들을 구현할 때 이번에 배운 내용들이 내가 작성하는 코드의 자신있는 근거가 될 수 있을것이라 확신한다.