개요

누군가 작성한 코드를 분석하기 위해 100줄 남짓한 메서드를 보고있다. 최상위에 지역변수들이 초기화되어 있고, 아래로 비지니스 로직이 주욱 구현되어 있다. 코드를 분석해나가는 도중 어떤 지역변수가 사용되었지만, 이 값이 어떤 값을 갖고있는지를 잊어버려 최상위에 적힌 지역변수를 다시 확인했다. 어떤 변수는 반복문에서도, try 문 안에서도, 다른 변수에 값을 할당하는 부분에도 사용됐다. 변수의 유효 범위가 너무 넓은 것이다. 변수를 체크하다보니 로직의 흐름을 까먹어 다시 분석하기도 한다. 이런 과정을 반복하면서 코드 분석을 마무리했다.
지역변수가 최상위에 선언되어 있지 않았다면?
지역변수들이 최상위에 선언되어 있지 않고, 쓰일 때 초기화되어 있거나, 현재 보이는 코드라인에 초기화 된 값이 보인다면 어땠을까? 다시 확인할 필요도 없고, 코드 분석에 대한 집중력도 유지할 수 있다. 즉, 지역변수의 범위를 최소화한다면 유지보수성과 가독성을 향상시킬 수 있다.
지역변수의 범위를 최소화하는 방법
가장 강력한 방법은 '가장 처음 쓰일 때 선언하는 방법'이다. 앞서 개요에서 말했던 방법이다. 사용하려면 멀었는데 미리 선언부터 해두면 이를 다시 확인하거나 잘못 사용하게 되는 상황이 발생할 수 있다. 사실 거의 모든 지역변수는 선언과 동시에 초기화해야한다. 여기서 거의라고 말한 이유는 그렇지 않은 예외 케이스가 존재하기 때문인데 바로 try-catch 문이다. 예외 처리를 해야하는 경우 선언은 try 문 밖에서, 초기화는 try 문 안에서 해야 catch나 finally 에서 이에 맞게 핸들링을 하거나 리소스를 제거하는 행위를 할 수 있다.
아래와 같이 FileInputStream 과 같은 타입의 값을 초기화할 때 예외처리를 하지 않을 경우 아래와 같이 컴파일 타임에 에러가 발생한다. 이를 처리하기 위해 예외를 외부로 던질수도 있지만, 이는 예외에 대한 책임을 전가하기에 메서드 내에서 처리를 하려는 사람도 있을 것이다.
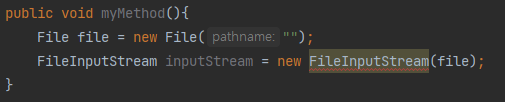
그 경우 inputStream을 try 외부에서 먼저 선언하고 내부에서 초기화하게 된다.
public void myMethod(){
File file = new File("");
FileInputStream inputStream = null;
try{
inputStream = new FileInputStream(file);
}catch (FileNotFoundException e){
e.printStackTrace();
}finally {
try{
inputStream.close();
}catch (IOException e){
e.printStackTrace();
}
}
}
물론 InputStream은 autoClose 가 구현되어 있으니 try-resource를 사용한다면 try 괄호 안에서 초기화가 되겠지만, 그게 아닐 경우 위처럼 선언과 동시에 초기화되지 않을 수도 있다. 어쨌든 중요한건 대부분의 지역변수는 사용할때, 선언과 동시에 초기화해야 한다는 것이다.
반복문의 반복변수
지역변수는 반복문에서도 사용된다. 바로 '반복변수'이다. 일반적으로 for나 while 과 같은 반복문에서 사용하는데 만약 반복 변수의 값을 반복문이 종료된 뒤에도 써야 하는 상황이 아니라면 while 보다 for 문을 쓰는 게 낫다.
예를들어 컬렉션을 순회하는 코드를 작성할 경우 for문은 아래와 같이 for-each나 전통적인 for문을 사용해서 구현할 수 있다.
List<String> list = new ArrayList<>();
//...
// for-each
for(String e : list){
//...
}
// 전통 for
for(Iterator<String> i = list.iterator(); i.hasNext();){
//...
}
while의 경우는 아래와 같이 구현되는데, while 구문 안에 조건을 넣어야하므로 while 구문 전에 반복 변수를 초기화를 해야한다. 그런데 아래와 같이 while 반복문이 두번 사용될 경우 복붙 과정에서 실수로 조건부의 i를 i2로 수정하지 않아 버그가 발생할 수 있다. 이 경우 두번째 반복문이 실행되지 않을 것이다.
Iterator<String> i = list.iterator();
while(i.hasNext()){
//...
}
Iterator<String> i2 = list.iterator();
while(i.hasNext()){ // 버그유발
//...
}
for문의 경우는 어떨까? 반복 변수의 유효범위가 for문 안으로 한정되어 있기 때문에 위와 같은 버그가 발생하지 않는다. 심지어 변수명을 다르게 설정할 필요도 없다.
for(Iterator<String> i = list.iterator(); i.hasNext();){
//...
}
for(Iterator<String> i = list.iterator(); i.hasNext();){
//...
}
여기서 키포인트는 초기화를 내부에서 했냐, 외부에서 했냐가 아니다. while에 사용되는 반복변수는 for문에 사용되는 반복변수보다 유효 범위가 훨씬 넓다는 것이다. while의 반복변수는 메서드 전체인데 반해, for문의 반복변수는 for문 안으로 한정되어 있다. 즉, 지역변수의 유효범위가 넓을수록 버그를 발생시킬 확률이 높고, 가독성과 유지보수성을 헤친다는 것을 말하고 있다.
정리
지역변수의 범위를 최소화하는 목적은 가독성과 유지보수성을 높이는 것이다. 이를 위해 지역변수를 선언과 동시에 초기화하거나, 실제로 쓰일 때 초기화 하거나, while 보다는 for문을 쓴것인데, 만약 이를 다 지킨다고 하더라도, 코드가 길면 어떨까? 긴 코드 안에는 여러 책임들이 얽혀있고, 여러 기능들을 하고, 여러 예외들을 처리한다면 지역변수의 범위를 최소화한다 한들 가독성과 유지보수성을 높인다는 목적을 이루지 못한다.
때문에 지역변수의 범위를 최소화하기에 앞서 선행되어야 할 가장 중요한 것은 단일 책임원칙에 맞게 코드를 구현하여 메서드를 작게 만드는 것이다. 이게 선행됐을 때 비로소 지역변수의 범위를 최소화하는 것이 의미있는 행위가 될것이다.
'공부 > Effective Java' 카테고리의 다른 글
| [Effective Java] Item 61. 박싱된 기본 타입보다는 기본 타입을 사용하라 (0) | 2024.06.05 |
|---|---|
| [Effective Java] Item 59. 라이브러리를 익히고 사용하라 (0) | 2024.05.23 |
| [Effective Java] Item 55. 옵셔널 반환은 신중히 하라 (0) | 2024.04.18 |
| [Effective Java] Item 51. 메서드 시그니처를 신중히 설계하라 (2) | 2024.04.10 |
| [Effective Java] Item 50. 적시에 방어적 복사본을 만들라 (0) | 2024.04.02 |