웹 캐시란?
브라우저가 웹 서버에 접속하여 받아온 정적 컨텐츠 (html, 이미지, js 등)를 메모리 또는 디스크에 저장해 놓는 것을 말한다. 이후 HTTP 요청을 할 경우 해당 리소스가 캐시에 있는지 확인하고 이를 재사용함으로써 응답시간과 네트워크 대역폭을 줄일 수 있다.
웹 캐시의 장점
1. 불필요한 네트워크 통신을 줄인다.
클라이언트가 서버에게 문서를 요청할 때, 서버는 해당 문서를 클라이언트에게 전송하게 된다. 재차 똑같은 문서를 요청할 경우 똑같이 전송하게 된다.
캐시를 이용하면, 첫번째 응답은 브라우저 캐시에 보관되고, 클라이언트가 똑같은 문서를 요청할 경우 캐시된 사본이 이에대한 응답으로 사용될 수 있기 때문에, 중복해서 트래픽을 주고받는 네트워크 통신을 줄일 수 있다.
2. 네트워크 병목을 줄여준다.
많은 네트워크가 원격 서버보다 로컬 네트워크에 더 넓은 대역폭을 제공한다. WAN 보다 LAN이 구성이 더 쉽고, 거리도 가까우며, 비용도 적게들기 때문이다. 만약 클라이언트가 빠른 LAN에 있는 캐시로부터 사본을 가져온다면, 캐싱 성능을 대폭 개선할 수 있다.

예를들어 샌프란시스코 지사에 있는 사용자는 애틀랜타 본사로부터 문서를 받는데 30초가 걸릴 수 있다. 만약 이 문서가 샌프란시스코의 사무실에 캐시되어 있다면, 로컬 사용자는 같은 문서를 이더넷 접속, 즉 LAN을 통해 1초 미만으로 가져올 수 있을 것이다.
3. 거리로 인한 네트워크 지연을 줄여준다.
대역폭이 문제가 되지 않더라도, 거리가 문제될 수 있다. 만약 보스턴과 샌프란시스코 사이에 네트워크 통신을 한다면 그 거리는 4,400 킬로미터이고, 신호의 속도를 빛의 속도(300,000 킬로미터 / 초)로 가정하면 편도는 약 15ms, 왕복은 30ms 가 걸린다.
만약 웹페이지가 20개의 작은 이미지를 포함하고 있다면, 이 속도에 비례하여 통신 시간이 소요된다. 추가 커넥션에 의한 병렬처리가 이 속도를 줄일 수 있지만, 이보다 더 떨어진 거리거나, 훨씬 더 복잡한 웹페이지일 경우 거리로 인한 속도 지연은 무시할 수 없다.
캐시는 이러한 거리를 수천 킬로미터에서 수십 미터로 줄일 수 있다.
4. 갑작스런 요청 쇄도(Flash Crowds)에 대처 가능하다.
원 서버로의 요청을 줄이기때문에 갑작스런 요청 쇄도 (Flash Crowds) 에 대처할 수 있다.
적중과 부적중 (cache hit, cache miss)
캐시에 요청이 도착했을 때, 그에 대응하는 사본이 있다면 이를 이용해 요청이 처리될 수 있다. 이를 캐시 적중(cache hit)라고 하고, 대응하는 사본이 없다면 원 서버로 요청이 전달된다. 이를 캐시 부적중(cache miss)라고 한다.
웹 캐시 체감하기
1. 기본 셋팅
실제로 웹 캐시를 적용했을때와 그렇지 않았을 때의 차이를 비교해보자. 테스트 환경으로는 웹서버인 Apache 2.4 버전을 사용했으며, 보다 확실하게 체감하기 위해 Network 속도를 Slow 3G로 설정하였다. 이는 크롬 개발자 도구에서 설정 가능하다.

1. 웹 캐시로부터 읽어오지 않은 응답
1) 최초 HTTP 통신
최초 웹서버 접속 시 HTML 형태의 응답을 받고, HTML 내에 존재하는 정적 리소스를 로딩하기 위해 서버로 요청하고 있다. 이때 해당 리소스의 Size는 5~20 kb, Time은 약 2초 정도 걸렸다.
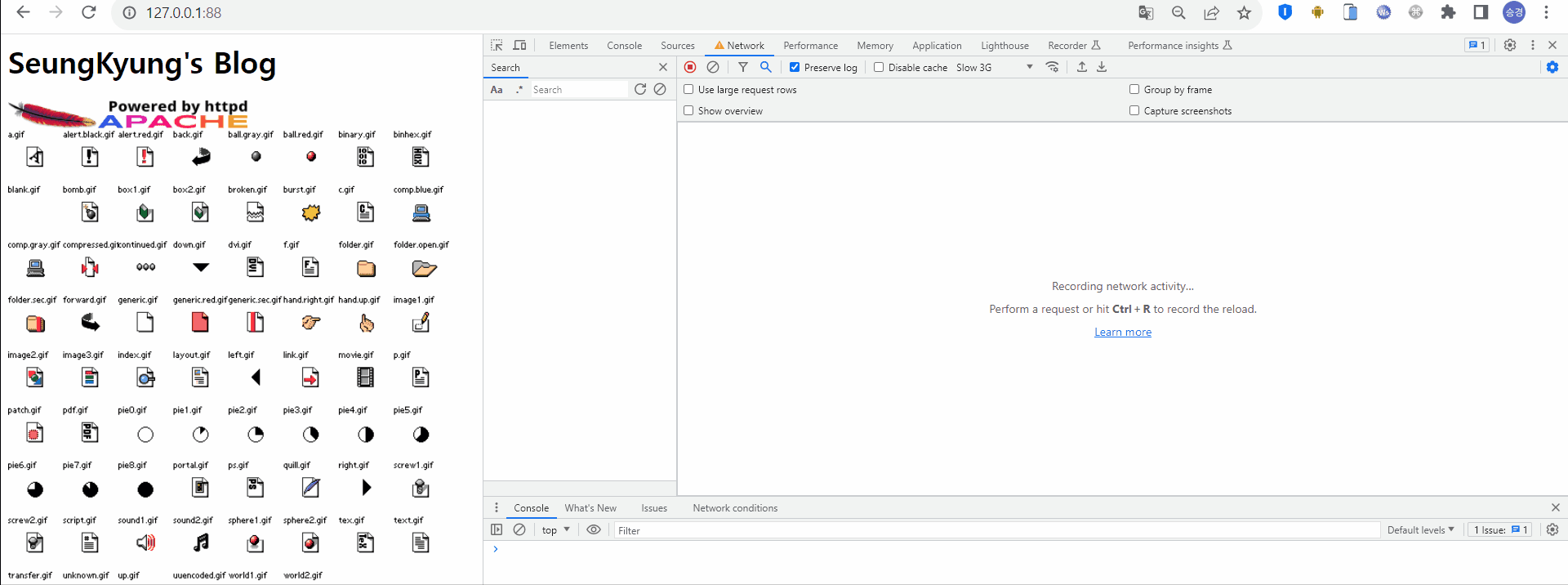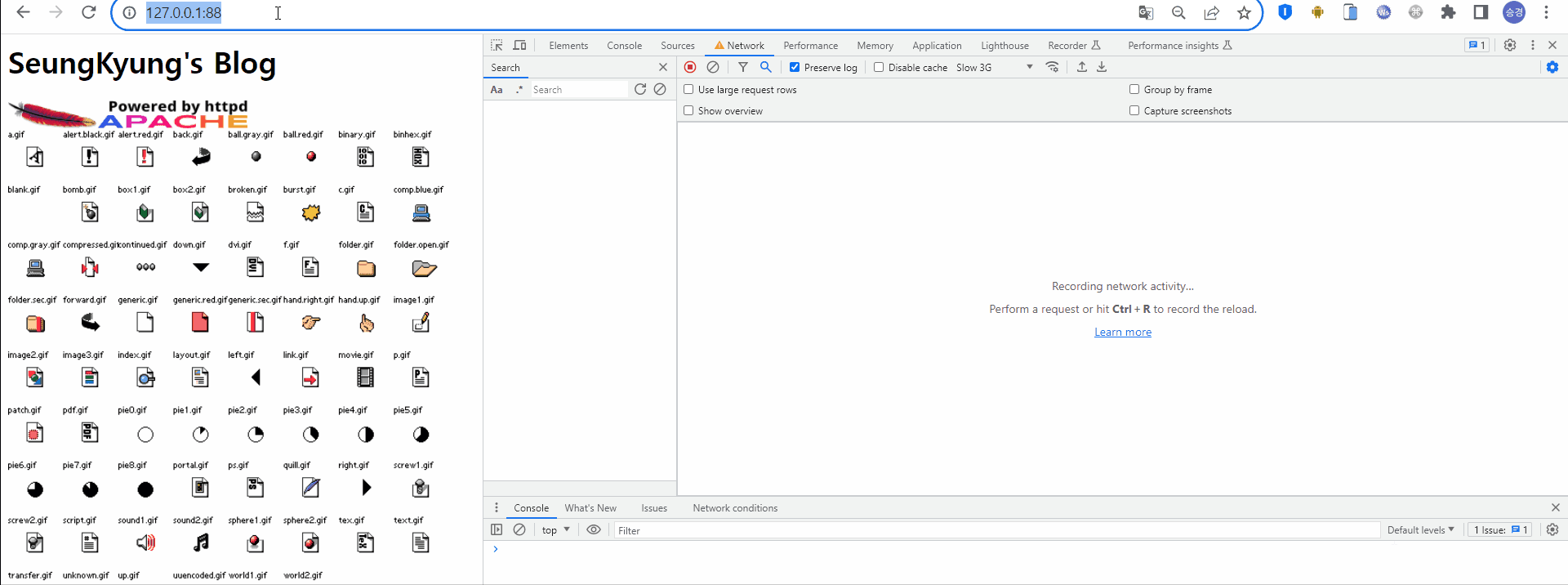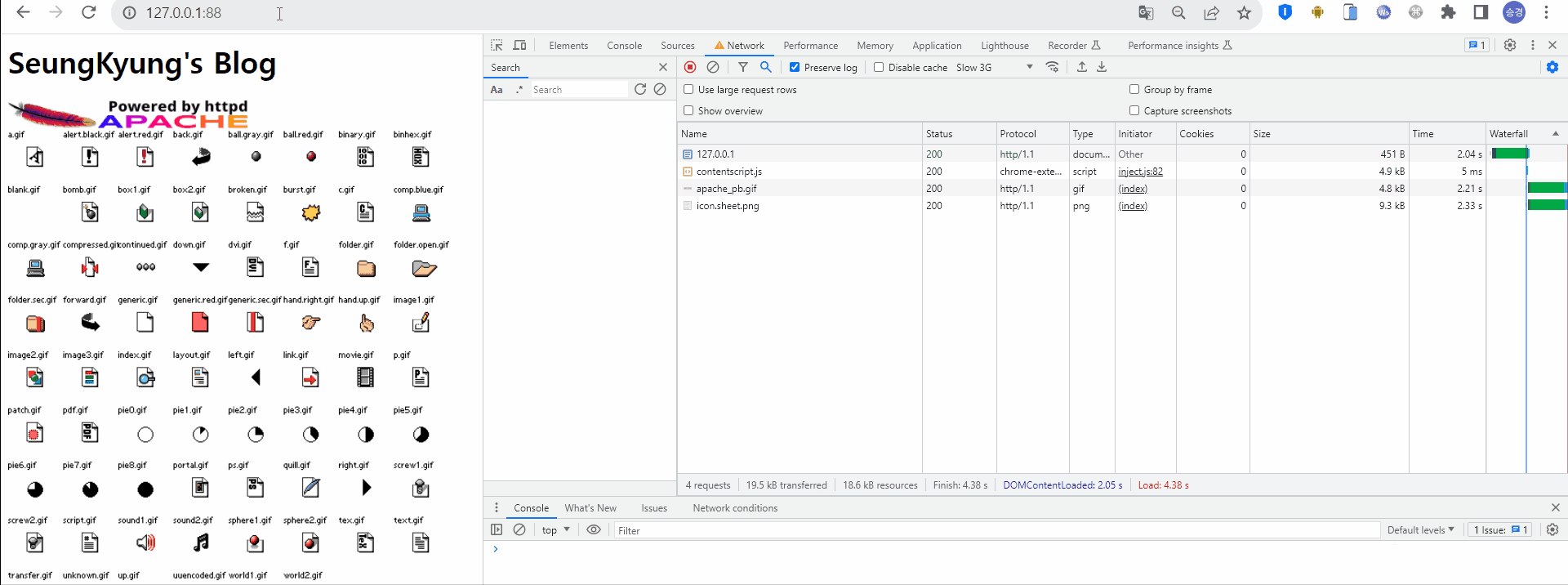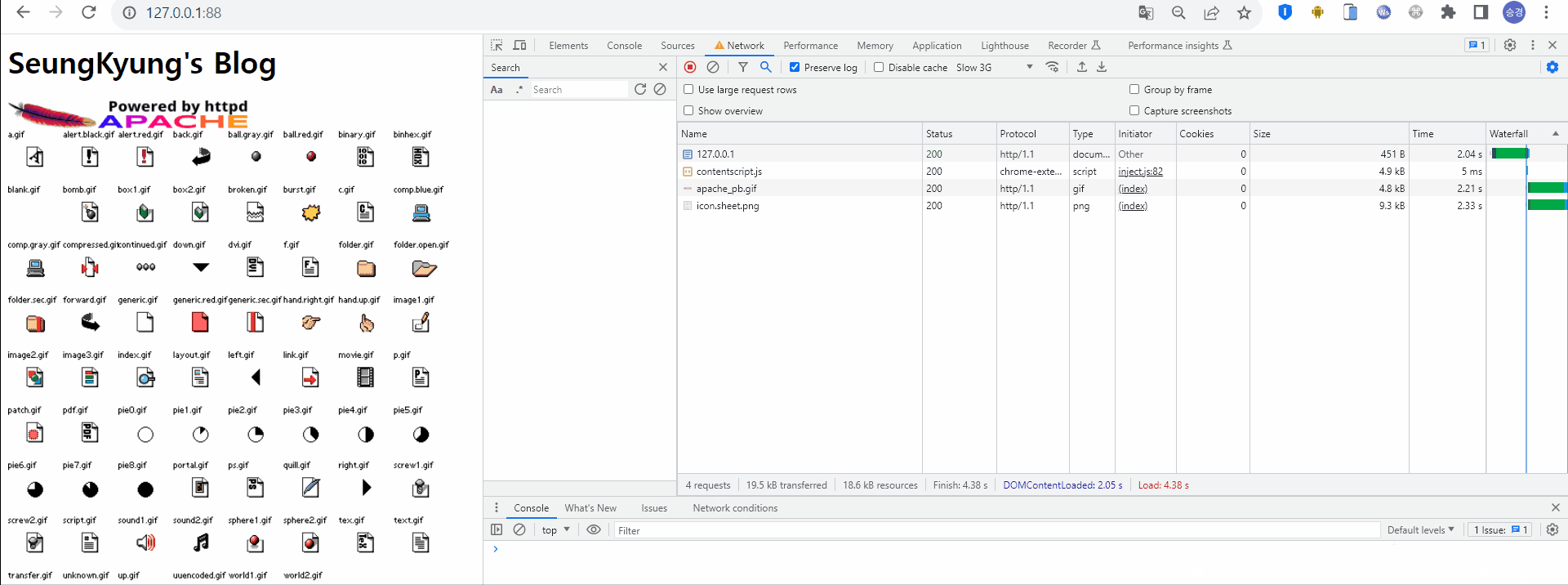
2) 두번째 HTTP 통신
이후 동일 URI로 재요청 한다. 마찬가지로 HTML 형태의 응답을 받고, HTML 내에 존재하는 정적 리소스를 로딩하기 위해 다시 서버로 요청하고 있다. Size와 Time 모두 이 전 요청과 동일하다. 이를 통해 정적데이터가 필요할 때마다 서버로 요청한다는 것을 알 수 있다.

2. 웹 캐시로부터 읽어온 응답
1) 최초 HTTP 통신
최초 웹서버 접속 시 HTML 형태의 응답을 받고, HTML 내에 존재하는 정적 리소스를 읽어오기 위해 서버로 요청하고 있다. 이때 해당 리소스의 Size는 5~20 kb, Time은 약 2초 정도 걸렸다.

2) 두번째 HTTP 통신
이후 동일 URI로 재요청 한다. 마찬가지로 HTML 형태의 응답을 받고, HTML 내에 존재하는 정적 리소스를 읽고 있다. 그런데 다른점이 있다. Size에 memory cache 가 적혀있고, Time은 0ms이다. 해당 리소스를 서버가 아닌 memory에서 조회했다는 것을 알 수 있다. 이를 통해 정적데이터가 캐시에 저장되어 있을 경우 캐시에서 로드한다는 것을 알 수 있다.
캐시 옵션 설정하기
캐시는 Cache-Control이라는 HTTP Header로 설정할 수 있다. 먼저 해당 옵션을 살펴보자.
1. Cache-Control
| 설정 값 | 내용 |
| no-store | 캐시에 리소스를 저장하지 않는다. |
| no-cache | 캐시 만료기간에 상관하지 않고 항상 원 서버에게 리소스의 재검사를 요청한다. |
| must-revalidate | 캐시 만료기간이 지났을 경우에만 원 서버에게 리소스의 재검사 요청한다. |
| public | 해당 리소스를 캐시 서버에 저장한다. |
| private | 해당 리소스를 캐시 서버에 저장하지 않는다. 개인정보성 리소스이거나 보안이 필요한 리소스의 경우 이 옵션을 사용한다. |
| max-age | 캐시의 만료기간(초단위)을 설정한다. |
※ 재검사가 뭔가요?
재검사(Revalidation)는 신선도 검사라고도 하며, 캐시가 갖고 있는 사본이 최신 데이터인지를 서버를 통해 검사하는 작업을 말한다. 최신 데이터인 경우 304 Not Modifed 응답을 받게 되는데, 이는 '캐시에 있는 사본 데이터가 최신이며, 수정되지 않았다'라는 뜻을 의미한다. 이 경우 클라이언트는 해당 리소스를 캐시로부터 로드하게 된다.
2. Apache httpd.conf 설정
Apache 웹서버의 httpd.conf를 통해 설정할 수 있다. 필자의 경우 캐시의 만료기간을 10초로 설정하기 위해 아래 구문을 최하단에 넣어주었다. 서버를 재시작하여 설정을 적용하고 서버로 요청을 보내보자.
Header Set Cache-Control "max-age=10"
만료기간 10초가 지나기 전에 다시 요청할 경우 캐시 메모리에 저장된 리소스를 가져옴을 확인할 수 있다.

3. HTTP Status 304
캐시의 만료기간인 10초가 지나자 재검사를 진행했고, 서버의 리소스가 바뀌지 않아 304 상태코드를 리턴받고 있다. 그럼 재검증은 HTTP 메시지의 어떤 값을 통해 확인할 수 있는걸까?


서버를 통해 리소스를 응답받으면 Response Header에 해당 리소스의 마지막 수정날짜가 들어간다. 아래 이미지를 보면 Last-Modified 헤더에 Sat, 04 May 2013 12:52:00 GMT로 되어있다.

이를 우리나라 시간으로 환산하면 2013년 5월 4일 21시 52분인데, 실제 서버에 있는 리소스의 마지막 수정날짜이다.

이 후 서버로 리소스 요청을 보낼 때 요청 헤더의 If-Modified-Since 에 리소스의 마지막 수정날짜를 보낸다. 서버는 이 값과 실제 수정 날짜를 비교하여 일치하지 않을 경우, 즉 리소스가 변경된 경우에 200 코드와 함께 해당 리소스를 내려준다.
리소스가 변경되지 않았을 땐 304를, 리소스가 삭제되었다면 404를 응답한다.
캐시 포톨로지
캐시는 한 명의 사용자에게만 할당될 수 있고, 수천 명의 사용자에게 공유될 수도 있다. 한명에게만 할당된 캐시를 전용 캐시, private cache라 하고, 여러 사용자가 공유하는 캐시는 공용 캐시, public cache 라고 한다.
private cache의 대표적인 예는 방금 설명했던 브라우저 캐시이다. 웹 브라우저는 개인 전용 캐시를 내장하고 있으며 컴퓨터의 디스크 및 메모리에 캐시해놓고 사용한다.

public cache의 대표적인 예는 프락시 캐시라고 불리는 프락시 서버이다. 각각 다른 사용자들의 요청에 대해 공유된 사본을 제공할 수 있어 private cache보다 네트워크 트래픽을 줄일 수 있다.

캐시 처리 단계
웹 캐시의 기본적인 동작은 총 일곱 단계로 나뉘어져 있다.

1. 요청 받기
먼저 캐시는 네트워크 커넥션에서의 활동을 감지하고, 들어오는 데이터를 읽어들인다. 즉, 서버로 요청하기 전 캐시에서 선 작업이 진행된다. (캐시는 HTTP의 응용계층에서 처리된다.)
2. 파싱
캐시는 요청 메시지를 여러 부분으로 파싱하여 헤더 부분을 조작하기 쉬운 자료구조에 담는다. 이는 캐싱 소프트웨어가 헤더 필드를 처리하고 조작하기 쉽게 만들어준다.
3. 검색
캐시는 URL을 알아내고 그에 해당하는 로컬 사본이 있는지 검사한다. 만약 문서를 로컬에서 가져올 수 없다면, 그것을 원 서버를 통해 가져오거나 실패를 반환한다.
4. 신선도 검사
HTTP는 캐시가 일정 기간 동안 서버 문서의 사본을 보유할 수 있도록 해준다. 이 기간동안 문서는 신선하다고 간주되고 캐시는 서버와의 접촉 없이 이 문서를 제공할 수 있다. 하지만 max-age를 넘을 정도로 너무 오래 갖고 있다면, 그 객체는 신선하지 않은 것으로 간주되며, 캐시는 그 문서를 제공하기 전 문서에 어떤 변경이 있었는지 검사하기 위해 서버와 통신하여 재검사 작업을 진행한다.
5. 응답 생성
캐시는 캐시된 응답을 원 서버에서 온 것처럼 보이게 하고 싶기 때문에, 캐시된 서버 응답 헤더를 토대로 응답 헤더를 새로 생성한다.
6. 전송
응답 헤더가 준비되면, 캐시는 응답을 클라이언트에게 돌려준다.
7. 로깅
대부분의 캐시는 로그 파일과 캐시 사용에 대한 통계를 유지한다. 각 캐시 트랜잭션이 완료된 후, 캐지 적중과 부적중 횟수에 대한 통계를 갱신하고, 로그파일에 요청 종류, URL 그리고 무엇이 일어났는지를 알려주는 항목을 추가한다.
'CS' 카테고리의 다른 글
| [CS] SSL 인증서란? / SSL 동작방식 / 암호화 방식 / CA를 통해서 인증서를 발급받는 이유 (0) | 2025.04.17 |
|---|---|
| [CS] 프로세스와 스레드 / 프로세스 구조 및 상태 / 싱글 스레드와 멀티 스레드 (0) | 2023.12.06 |
| [CS] 웹 프락시 / Proxy (0) | 2023.09.20 |
| [CS] HTTP 메시지 (0) | 2023.08.30 |
| [CS] URL이란? (0) | 2023.08.30 |








