1. 개요
국토 교통부에서 제공하는 법정동 코드를 다운받아 DB 테이블에 밀어 넣고, JPA를 통해 주소를 검색하는 API를 구현하였다. 하지만 데이터의 양이 많아 응답까지 1초 ~ 3초정도가 소요되는 것을 보고 Redis의 캐싱 기능을 도입하게 되었다. 그 과정을 정리한다.
2. Cache 설정
2.1. RedisCacheConfig.kt
@Configuration
@EnableCaching
class RedisCacheConfig {
@Bean
fun redisCacheManager(cf: RedisConnectionFactory?): CacheManager? {
val redisCacheConfiguration = RedisCacheConfiguration.defaultCacheConfig()
.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(StringRedisSerializer()))
.serializeValuesWith(
RedisSerializationContext.SerializationPair.fromSerializer(
GenericJackson2JsonRedisSerializer()
)
)
.entryTtl(Duration.ofDays(1))
return RedisCacheManager.RedisCacheManagerBuilder.fromConnectionFactory(cf!!)
.cacheDefaults(redisCacheConfiguration).build()
}
}
TTL은 하루로 설정하였고, 직렬화 방식은 key는 String, value는 GenericJackson2JsonRedisSerializer를 사용했다. 이 형식을 사용한 이유는 캐싱할 value 값이 List<Object> 형태였기 때문이다.
2.2. Applicatoin.kt
@SpringBootApplication
@EnableCaching
class Application
fun main(args: Array<String>) {
runApplication<Application>(*args)
}캐시를 사용하기 위해 Application 실행파일에 @EnableCaching을 추가하였다.
2.3. Service.kt
@Service
class AddressService (
private val addressRepository: AddressRepository
){
@Cacheable(value = ["Address"], key = "#searchWord", cacheManager = "redisCacheManager")
fun searchAddress(searchWord : String) : List<AddressResponse> {
return addressRepository.findBySearchWordLike(searchWord)
}
}캐시를 적용하고자 하는 메서드에 @Cacheable 을 설정한다. [value]는 redis에 저장되는 Key의 prefix, [key]는 suffix 이다. 만약 동일한 키를 가진 캐싱 데이터가 있을 경우 cache hit가 발생하여 캐싱된 데이터를 조회하고, 없을 경우 cache miss가 발생하여 DB에서 데이터를 조회한 후 데이터를 캐싱할 것이다.
cacheManage에는 RedisCacheConfig 에서 생성한 Bean 이름을 넣어준다.
2.4. Controller.kt
@Controller
@RequestMapping("/api/address")
class AddressController (
private val addressService : AddressService
) {
...
@GetMapping("/search")
fun searchAddress(@RequestParam("searchWord") searchWord : String) : ResponseEntity<List<AddressResponse>> {
val list = addressService.searchAddress(searchWord)
return ResponseEntity.ok(list)
}
...
}Controller에서 캐싱 메서드를 호출한다.
3. 테스트
3.1. 최초 검색
최초 검색시 cache miss가 발생함에 따라 DB 조회 및 redis 에 데이터를 캐싱하는 과정을 거치게 된다. IDE에 찍힌 로그를 보면 JPA 쿼리 결과가 조회되는데, 이는 DB를 조회하여 데이터를 가져왔다는 사실을 알수있다.
캐싱된 데이터는 redis-cli 를 실행 후 keys, get 명령어를 통해 확인할 수 있다. 시간은 1400ms가 소요되었다.


3.2. 두번째 요청
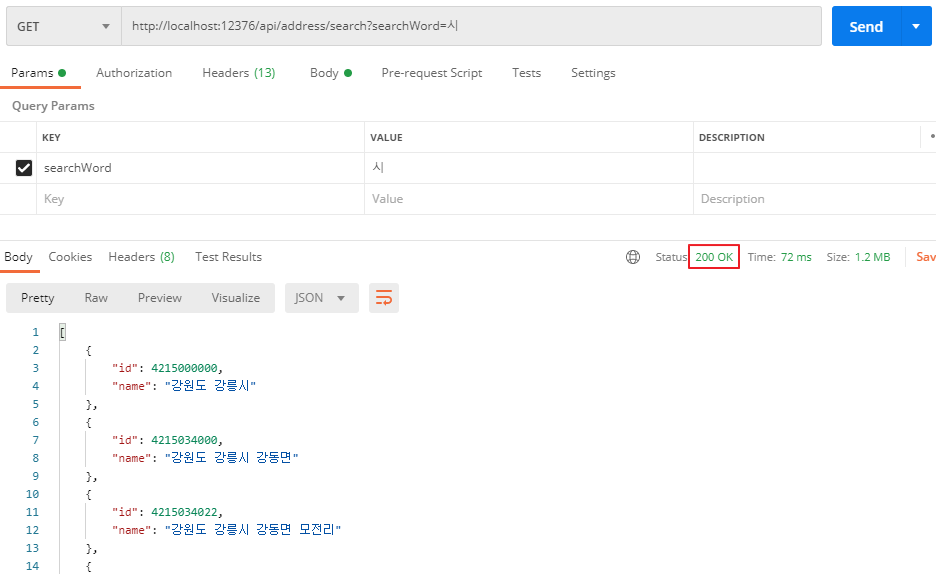
동일한 값으로 요청하니 cache hit가 발생하여 DB를 조회하지 않고 캐싱된 데이터를 조회하고 있다. DB를 조회했다면 JPA 쿼리 결과가 콘솔에 찍힐테지만, 아무 로그도 찍히지 않고 있다. 시간은 72ms가 소요되었다.
3.3. 새로운 키워드로 요청
캐싱된 값이 없으니 cache miss가 발생하고 3.1. 최초검색과 비슷한 시간이 소요됨을 확인하였다.
4. 문제
4.1. 건당 Redis 메모리 사용량
redis-cli 의 info memory 명령어를 통해 redis 메모리 사용량을 확인할 수 있다. 확인해보니 시, 도 별로 검색할 경우 한 건당 메모리가 약 1M 정도 사용되었다. 결코 적은 양이 아니다. 만약 시, 도별 다른 키워드로 검색을 한다면 cache miss가 발생하여 데이터를 캐싱할 것이고, 1M 정도가 추가로 사용될 것이었다.
TTL을 하루로 설정하였기에 RAM 용량이 8GB라면 각기 다른 키워드로 8000번 호출 시 redis 서버가 다운될 가능성이 있다.
4.2. 주소 검색의 특성
주소 검색 특성상 많은 사람들이 똑같은 키워드보다는 본인이 사는 동이나, 지번으로 검색할 확률이 높다. 새로운 키워드가 들어올 확률이 높다는 것이다. cache miss가 빈번하게 발생할 것이고, 응답 시간은 DB를 단독으로 사용하는 것보다 느린 케이스도 빈번할 것이다. redis 메모리 사용량도 빠르게 늘어날 것이다.
5. 개선
주소 검색 시 선 작업으로 모든 주소를 조회하는 로직을 추가하였다. 그 후 조회한 리스트에서 검색어에 대한 주소 값을 추출하는 방식을 채택했다.
캐싱은 모든 주소를 조회하는 부분에 적용하였다. cache hit시 리스트에서 필터링하는 시간과 비용만 소비하면 된다. 물론, 첫번째 방식 사용 시보다 응답 속도가 느린 케이스도 있다. TTL이 만료되는 24시간 후 cache miss가 발생할 때 데이터를 가져올때나 동일 키워드로 여러번 검색할때이다. 일단 개선 로직 구현 후 이에 대한 트레이드 오프를 분석할 예정이다.
5.1. 개선 AddressController.kt
...
@GetMapping("/search")
fun searchAddress(@MemberAuthentication authenticationAttributes: AuthenticationAttributes
, @RequestParam("searchWord") searchWord : String) : ResponseEntity<List<AddressResponse>> {
val allAddressList = addressService.searchAllAddress()
val findAddressList = addressService.searchAddress(allAddressList, searchWord)
return ResponseEntity.ok(findAddressList)
}
...addressService.searchAllAddress() 메서드를 통해 캐싱되어있는 모든 주소리스트를 조회하고, searchAddress() 메서드를 통해 키워드를 포함하는 요소를 찾아 리턴한다.
searchAddress() 메서드 안에서 searchAllAddress()를 호출할 수 도 있지만, AOP를 사용하는 캐싱 메서드의 특성 상 Self-invocation 이슈가 있어 Controller에서 따로 호출하였다.
* Self-invocation 으로 인한 이슈
AOP 기반으로 호출되는 캐싱 메서드의 특성 상 같은 클래스 내 위치한 특정 메서드에 의해 캐싱 메서드가 호출될 경우 캐싱 기능이 동작하지 않는다. 이에따라 컨트롤러에서 캐싱 메서드를 호출하여 캐싱 처리하고, 응답받은 값을 통해 서치하는 메서드를 호출하는 방식을 채택하였다.
5.2. 개선 AddressService.kt
@Service
class AddressService (
private val addressRepository: AddressRepository
){
...
@Cacheable(value = ["AllAddress"], key = "", cacheManager = "redisCacheManager")
fun searchAllAddress() : List<AddressResponse> {
val list = addressRepository.findAll()
return list.stream()
.map { e -> AddressResponse(e.id, e.addr) }
.collect(Collectors.toList())
}
fun searchAddress(list : List<AddressResponse>, searchWord: String): List<AddressResponse> {
return list.stream()
.filter { address -> address.name.contains(searchWord) }
.collect(Collectors.toList())
}
}searchAllAddress() 메서드는 DB에서 모든 주소 값을 읽어와 List<AddressResponse> 형태로 리턴하며 캐싱한다. cache miss가 발생 시 시간이 다소 소요된다. searchAddress는 list에 대해 필터링하는 메서드이다.
6. 개선 테스트
6.1. 최초 검색
1차 테스트와 동일한 검색어로 검색한 결과 cache miss 발생 시 응답속도가 1400 ms 에서 2170 ms로 0.67초 느려진 것을 확인하였다. 모든 주소 값을 읽고, 캐싱하는 부분으로 인한 시간이라 생각한다.
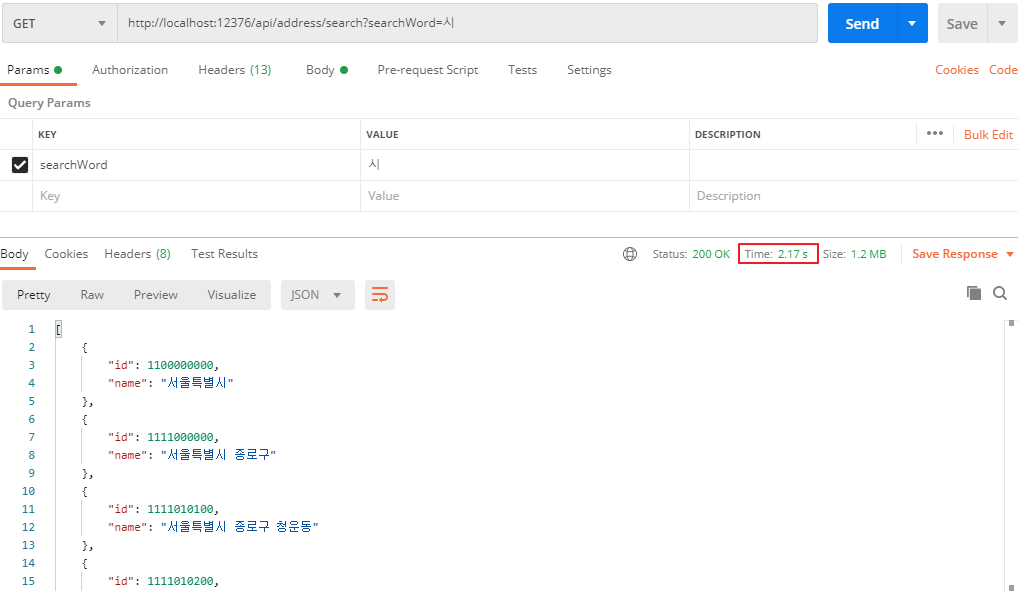
6.2. 두번째 검색
동일한 키워드로 두번째 검색을 하였다. 전자의 경우 '시'라는 키워드에 대한 결과가 미리 캐싱되어있었기에 소요되는 시간이 조금 더 걸릴것으로 예상했으나, 72ms에서 92ms로 생각보다 시간 차이가 얼마 나지 않음을 알 수 있었다. 몇번 더 테스트해봐도 100ms 안밖이었다.
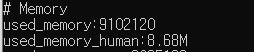
cache miss가 발생하지 않았기에 사용되는 메모리는 증가하지 않았다. 참고로 약 9MB 정도를 사용중이다. 이제 다른 키워드로 검색해보자.
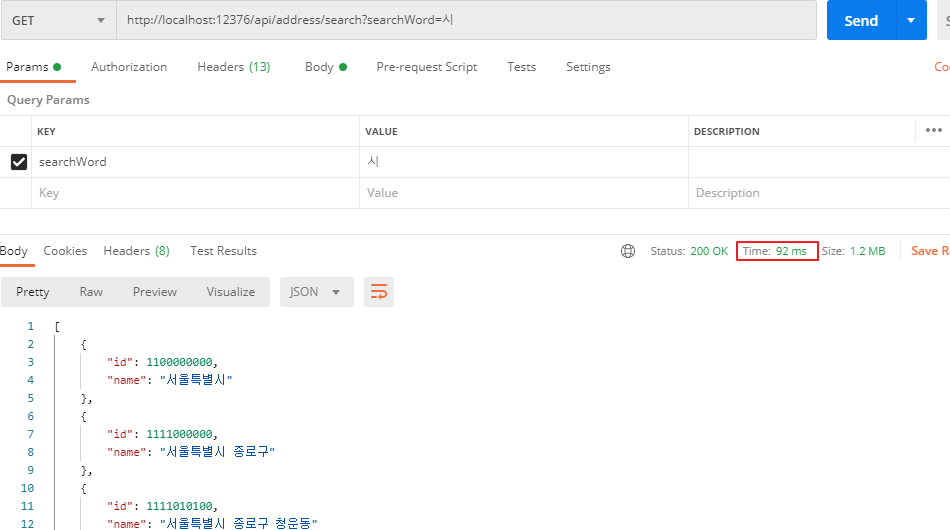
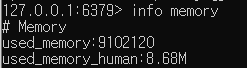
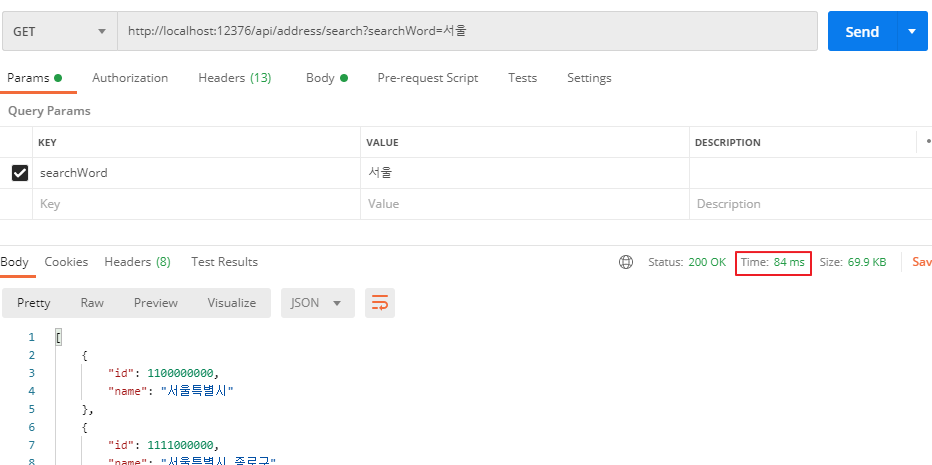
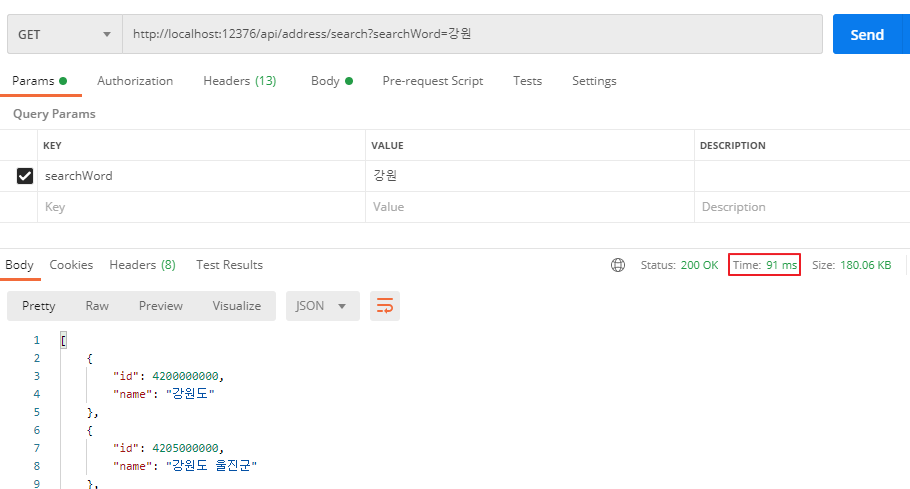
6.3. 새로운 키워드로 검색
서울, 강원 등 여러 키워드로 검색해보았다. 그 결과 걸린 시간은 모두 100ms 안팎임을 확인하였다. 메모리 사용량도 변함이 없다.
7. 장단점
개선 방식으로의 변경을 통해 확인한 장단점을 정리해보았고, 트레이드 오프를 고려했을 때 개선된 방식이 훨씬 더 효율적이라는 결론을 내렸다.
* 장점
1. Redis 메모리 부족 위험에 대해 완전히 벗어날 수 있다.
2. 새로운 키워드로 검색해도 cache miss가 발생하지 않아 속도가 빠르다. (1400 ms > 100ms로 개선)
3. 동일한 키워드로 검색해도 이전 방식과 속도차이가 거의 나지 않는다. (약 20ms 차이)
* 단점
1. cache miss 발생 시 이전보다 더 많은 시간이 소요된다. (1400 ms > 2170 ms 로 증가)
2. 데이터 정합성 문제 발생 확률이 이전보다는 높다. (하지만 쓰기 작업을 연마다 하는 특성 상 큰 문제는 되지 않을 것이라 판단하였다)
8. 회고
데이터 수정이 없는 주소 데이터 특성에 의해 무작정 캐싱 도입을 하였으나, 큰 성능향상은 얻지 못했고, 오히려 Redis 메모리에 대한 잠재적인 문제와, cache miss 시 속도문제를 안게 되었다. 이건 캐싱에 대한 이해도가 부족해 발생한 것이라 생각하여 개념, 용어, 방법, 전략들을 공부하였다.
전략을 선택할 때 가장 중요한 건 캐싱할 데이터의 성격을 분석하는 것이라 생각한다. 메모리 용량은 많아봤자 32GB로 제한적이다. 많은 데이터를 캐싱할 수록 메모리의 부담은 커지고, 메모리 부담을 덜기 위해 무작정 TTL을 낮춘다면, 잦은 DB 혹은 API 통신으로 시간이 더 걸릴 수 있다. 만약 특정 키워드로 반복적인 읽기가 많은 작업이었다면 캐싱을 적용하기 전보다 성능이 낮아질수도 있다.
조회 작업이 많은지, 쓰기 작업이 많은지, 쓰기 작업 없진 않는지, 있다면 그 빈도는 어떤지, 조회만 하는지 등을 분석하여 메모리 사용량을 낮추고, 속도는 비교적 높일 수 있는 캐싱 전략을 세워야 하는데, 이는 캐싱 데이터의 성격에 따라 달라진다.
주소 검색의 경우 쓰기 전략을 Write Around를, 읽기 전략은 Look Aside로 설정하고 코드를 개선해나갔다. 주로 읽기 작업이고, 쓰기작업은 연 주기로 공공기관을 통해 데이터를 다운받아 DB에 밀어넣는 것 하나이기 때문이다. 또한 쓰기 작업이 되어 새로 등록된 주소는 cache miss가 발생할 때 조회해도 서비스 운영에는 큰 문제가 발생하지 않고, 즉시 조회를 해야 한다고 해도 캐시를 수동으로 만료시키는 방안도 있었다.
이렇게 데이터의 성격을 파악하고 전략을 수립한 상태에서 리팩토링을 하니 속도와 메모리 효용성을 향상시킬 수 있는 방법을 구상하고 적용할 수 있게 되었다. 캐싱을 적용하는 것은 어렵지 않다. 다만 데이터의 성격을 분석하여 캐싱을 왜 적용하는지, 어느 부분에 적용해야 좋은지, 적용을 통해 얻을 수 있는 장단점은 어떻고, 적절한 트레이드 오프인지를 생각하는 것이 중요하다고 생각한다.
'백엔드 > Redis' 카테고리의 다른 글
| [Redis] Redis를 활용한 자동완성 구현 (2) / 검색빈도 내림차순 조회 (2) | 2023.06.17 |
|---|---|
| [Redis] Redis를 활용한 자동완성 구현 (1) 및 자동완성 데이터 셋 만들기 (4) | 2023.06.09 |