개요
MySQL의 인덱스 구조는 B+Tree이다. 그럼 이미 등록된 인덱스 키를 테이블에서 추가, 삭제, 변경했을 때 내부적으로 어떻게 처리되는지를 이해해보자. 그리고 더 나아가 검색을 했을 때는 어떤 메커니즘으로 키를 찾아가는지도 이해해보자.
인덱스 키 추가
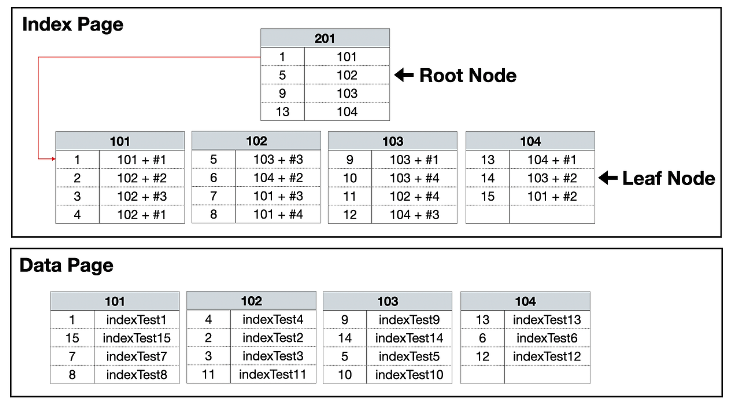
B+Tree에 키를 추가하기위해 가장 먼저 해야할 일은 B+Tree 상의 적절한 위치를 검색하는 것이다. 검색은 B+Tree 트리탐색을 통해 진행되며, 저장될 위치가 결정되면 인덱스 키와 데이터 레코드의 주소 정보(또는 데이터)를 리프노드에 저장한다. 만약 클러스터드 인덱스의 키 였다면 [key, 데이터]를, 세컨더리 인덱스의 키 였다면 [key, 클러스터드 인덱스의 리프노드 주소]가 추가될것이다.

인덱스 키 삭제
키 삭제는 간단하다. 해당 키 값이 저장된 리프 노드를 찾아서 삭제 마킹만 하면 끝이다. 삭제 마킹된 인덱스 키 공간은 방치되거나 재사용된다.
그냥 삭제하면 되지, 왜 삭제 마킹을??
만약 인덱스가 즉시 삭제된다면 B+Tree 구조에서 재정렬 작업이 발생하게 된다. InnoDB 엔진은 이러한 오버헤드를 줄이기 위해 삭제 마킹만 해놓고 purge thread가 백그라운드에서 일괄 삭제한다.
인덱스 키 변경
인덱스 키 값에 따라 B+Tree 상의 위치가 결정되므로 키 값이 변경되는 경우에는 B+Tree 상에서 인덱스 키 값만 달랑! 변경할 수 없다. 먼저 키 값을 삭제한 후(이때도 마킹이다), 다시 새로운 키 값을 추가하는 형태로 처리된다.
인덱스 키 검색
인덱스를 검색하는 작업은 B+Tree의 루트 노드부터 시작해 브랜치 노드를 거쳐 리프 노드까지 이동한다. 이를 트리 탐색이라 하는데, 내가 호출한 쿼리가 인덱스를 활용할 수 있는 상황에서 사용된다. 또한 상황에 따라 SELECT 절 뿐 아니라 UPDATE, DELETE 에도 사용된다는 것을 알 수 있을것이다. (값을 찾아야하니까!) 그럼 실제 조회 쿼리를 날렸을 때 어떤 메커니즘으로 데이터가 조회되는지 알아보자.
Integer 타입의 인덱스 키 조회
TBL_TEST 라는 테이블에 1~15 까지의 값을 INSERT 한 상황에서 아래 쿼리를 날렸다면 어떻게 조회될까? 이해를 돕기위해 필자가 사용하는 B+Tree 시뮬레이션 사이트를 활용했다.
SELECT * FROM TABLE WHERE ID = 10;
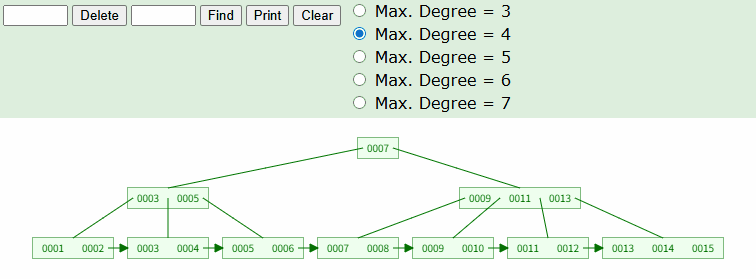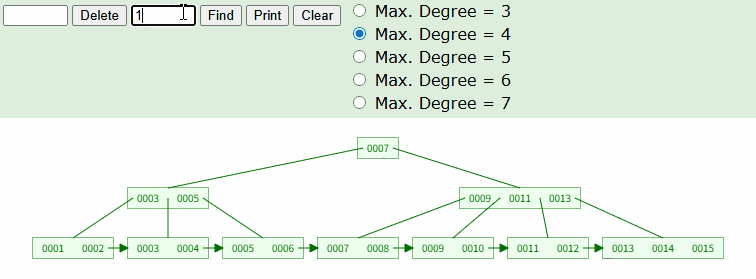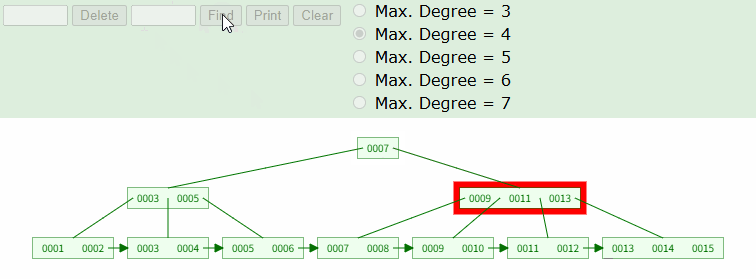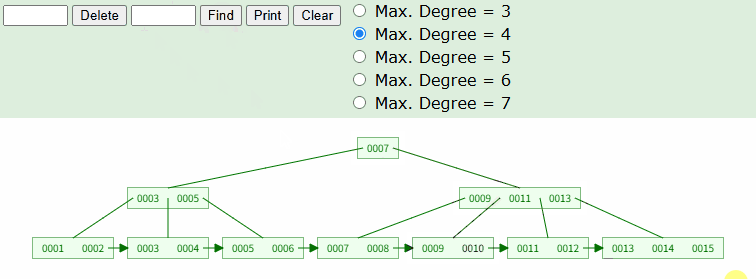
위와 같이 트리 탐색이 실시되고, 실제 데이터 노드가 있는 리프노드까지 이동한다. 위는 가장 일반적인 상황으로, 테이블의 ID 컬럼이 Integer 타입의 PK 라고 생각하면 된다.
String 타입의 인덱스 키 조회
String 타입의 값을 세컨더리 인덱스의 키로 설정하고, 이를 조회했을 땐 어떨까?
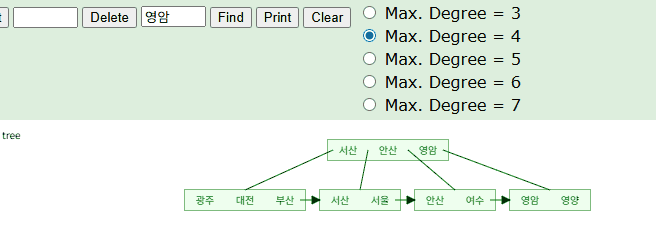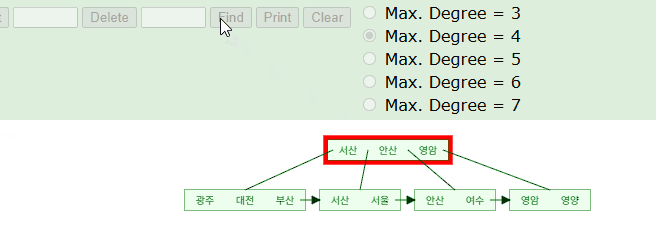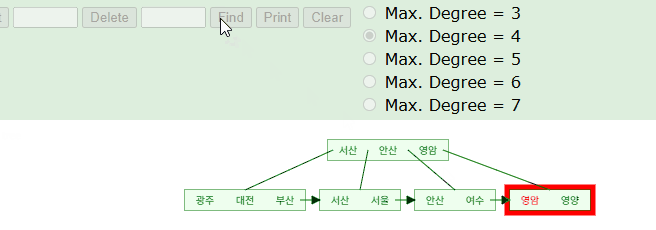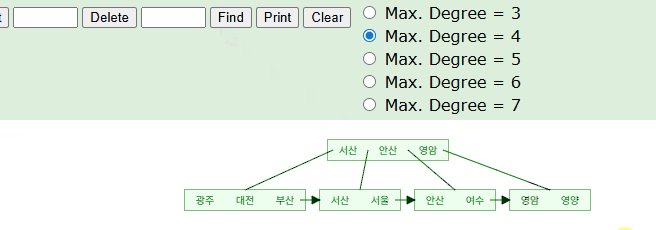
마찬가지로 B+Tree에 가나다 순으로 순서대로 저장될것이기에 트리 탐색을 통해 조회된다.
인덱스는 키 값이 100% 일치하는 조건절에만 사용되나요?
키 값이 100% 일치하는 상황 뿐 아니라 아래와 같이 값의 앞부분을 비교하거나 부등호를 통해 비교할 때에도 사용된다. 단, 뒷부분을 비교할 때는 트리 탐색. 즉, 인덱스가 사용되지 않는다. 이 이유는 아래서 설명하겠다.'
앞부분이 일치하는 인덱스 키 조회
SELECT * FROM TABLE WHERE NAME LIKE '서%';
B+Tree 구조를 활용하여 '서'로 시작하는 인덱스 키의 위치를 찾아낼 수 있다. 시뮬레이션을 돌며보면 해당 단어가 위치할만한 예상 지점을 찾아가고 있다. 실제 InnoDB 엔진에서는 아래와 같이 시작점을 찾은 후 리프노드의 포인터를 거쳐가며 '서'로 시작하는 데이터를 검증해나갈것이다.
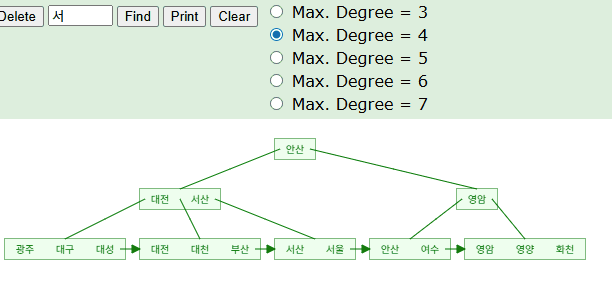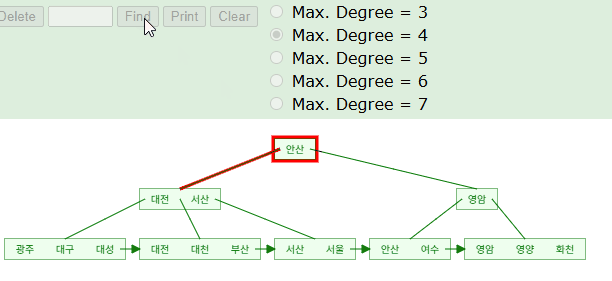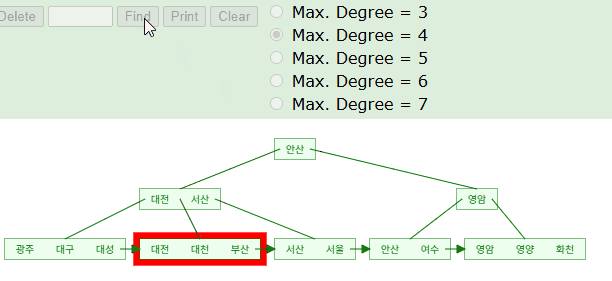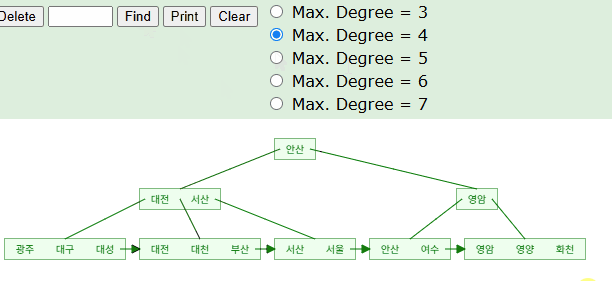
왜 꼭 앞부분 비교할때만 트리 탐색. 즉, 인덱스가 사용되는거에요?
책을 예시로 들면 바로 이해할 수 있다. 책에는 페이지 번호가 있다. 그런데 만약 페이지 번호가 숫자가 아닌 문자열(?)이라면 어떨까? 첫페이지는 광주, 두번째 페이지는 대구, 세번째 페이지는 대성... 이렇게 해서 마지막 페이지에 화천이 있는것이다.
만약 이 상황에서 '서'로 시작하는, 즉 LIKE '서%' 를 찾아야한다면 어떻게 찾아갈까? 가장 먼저 페이지의 중간을 펼칠것이다. '대천' 페이지가 나왔다면 '대천'이라는 단어보다 '서' 가 더 뒤에있으니 뒷 페이지에 어딘가에 있다는 것을 알 수 있다. 범위를 좁혀가며 페이지를 찾아가다보면 금방 '서' 로 시작하는 '서산' 이라는 페이지를 찾게될것이다. 그 이후부터는 한페이지씩 넘기면서 '서'라는 글자가 페이지 앞에 포함되어 있는지만 확인하면 된다. 그리고 '안산' 이라는 페이지가 나왔을때, 다음 페이지부터는 '서'로 시작하는게 페이지가 없다는 걸 알 수 있다.
B+Tree 도 똑같다. 문자열이든 숫자든 정렬되어 있으니 앞부분을 통해 값의 위치를 찾아갈 수 있다. 인덱스를 활용할 수 있는 것이다.
그럼 왜 뒷부분 비교에는 인덱스 사용이 안돼요?
그럼 뒷부분을 직접 비교해보자. 방금 말한 책에서 뒤가 '수'로 끝나는 페이지를 찾을 땐 어떻게 찾아야할까? 펼친 페이지 값을 통해 '수'로 끝나는 데이터의 위치를 유추할 수 있을까?
SELECT * FROM TABLE WHERE NAME LIKE '%수';
펼친 페이지에 어떤 문자열이 있건간에 유추할 수 없다. 페이지 번호(문자열)가 정렬되어 있더라도 뒷부분에 대한 비교에는 활용할 수 없는것이다. 첫번째 페이지부터 마지막 페이지까지 모두 스캔해가며 뒤에 '수'가 붙어있는지 확인하는 방법밖에 없다. 바로 이것이 Full Scan이다. 인덱스를 활용하지 못하면 Full Scan이 발생한다.
부등호에도 인덱스가 사용되는 이유는 알겠어요!
위 내용을 이해했다면 부등호를 사용했을 때 인덱스가 사용되는 이유도 알 수 있다. 65 < x < 70 인 값을 찾아야한다면 인덱스를 통해 B+Tree 상에서 65라는 키의 위치를 탐색한 후, 70이 되기 전까지 페이지를 앞으로 넘겨가면 된다.
WHERE 절에서 인덱스가 활용되는 조건
1) 등호(100% 일치) 비교
- ID 인덱스 활용
SELECT * FROM TABLE WHERE ID = 123;
2) IN 절
- ID 인덱스 활용
* 단, 너무 많은 값이 들어가면 옵티마이저가 무시할 수 있음.
SELECT * FROM TABLE WHERE ID IN (1,2,3);
3) 범위조건 (부등호, BETWEEN)
- CREATE_AT 인덱스 활용
SELECT * FROM TABLE WHERE CREATE_AT BETWEEN '2025-01-01' AND '2025-12-31';
4) LIKE 'ABC%'
- NAME 인덱스 활용
* 뒷부분을 검색하는 LIKE '%승'은 인덱스가 적용되지 않음
SELECT * FROM TABLE WHERE NAME LIKE '승%';
5) AND 조건에서 복합 인덱스
- 복합 인덱스 (COL1, COL2) 활용
* 복합 인덱스는 왼쪽부터 순서대로 사용하는 조건에만 적용됨
* COL1만 써도 인덱스 적용, COL2 만 쓰면 인덱스 적용 안됨
SELECT * FROM TABLE WHERE COL1 = 'A' AND COL2 = 'B';
회고
인덱스의 삽입, 삭제, 변경, 검색 방법에 대해 내부 메커니즘을 이해할 수 있었다. 이로 인해 인덱스가 사용되는 케이스, 사용되지 않는 케이스에 대해서도 그렇게 되는 이유를 생각할 수 있었다. 인덱스 사용에 대한 기준을 잡아가고 있고, 그 기준을 통해 서비스에도 적용할 수 있다는 자신감이 든다. 다음 게시글에서는 인덱스의 종류에 대해 알아보도록 하겠다.
'DB > MySQL' 카테고리의 다른 글
| [MySQL] 다중 컬럼(Multi-column) 인덱스 / 인덱스 설계 원칙 / Index Range Scan (1) | 2025.07.10 |
|---|---|
| [MySQL] MySQL과 B-Tree 함께 이해하기 / B-Tree / B+Tree / 클러스터링 인덱스 / 논 클러스터링 인덱스 (3) | 2025.06.11 |
| [MySQL] InnoDB 스토리지 엔진 잠금 / 레코드, 갭, 넥스트 키 락 / 팬텀리드를 방지할 수 있는 이유 (0) | 2025.05.27 |
| [MySQL] MySQL 엔진 잠금 / 글로벌 락 / 테이블 락/ 네임드 락/ 메타데이터 락 (1) | 2025.05.26 |
| [MySQL] Slow Query Logging 설정하기 / 슬로우 쿼리 로깅 설정 (0) | 2025.05.26 |