필자의 주관적인 생각과 이해를 바탕으로 작성된 글입니다. 잘못된 부분이 있거나 있다면 댓글로 피드백 부탁드립니다!
개요
HashMap은 Key, Value 데이터쌍을 저장하는 자료구조로 익히 알고있다. 속도면에서 장점을 갖고 있어 코딩테스트에서도 많이 활용된다. 도대체 어떻게 생겨먹은 녀석이길래 이렇게 빠른지 알아보자.
HashMap = Hash + Map
Map
Key, Value 쌍으로 이루어진 자료형.
순서를 보장하지 않음.
키는 중복이 허용되지 않음.
Hash
해시 함수를 사용하여 임의의 길이를 가진 데이터를 고정된 길이를 가진 데이터로 매핑한 값
즉, HashMap이란 Map은 Map인데 Hash를 활용한 Map인 것이다.
Map은 어떻게 Key, Value 쌍으로 관리할 수 있을까? 🤔
HashMap을 이해하기 위해선 Map과 Hash에 대해 이해해야한다. 먼저 Map이 어떻게 Key와 Value 쌍으로 관리할 수 있는 이유는 내부적으로 Key와 Value를 담을 수 있는 배열 타입으로 데이터를 관리하고 있기 때문이다.
먼저 일반적인 배열의 형태를 생각해보자. 인덱스마다 하나의 값을 넣을 수 있는 자료구조인데 Key와 Value를 둘 다 넣는다는 건 말이 되지 않아보인다. 그런데 배열의 인덱스에 Key값을 넣는다면 얘기가 된다. 0이라는 Key에 대한 Value는 010-1111-1111, 1이라는 Key에 대한 Value는 010-2222-2222로 관리한다고 가정한다면 아래와 같이 배열의 인덱스에는 Key 값을 넣어 관리할 수 있다.

배열의 인덱스를 키로 활용한다고? 그럼 Key는 정수만 가능하잖아... 🤔
그렇다. HashMap의 Key는 정수 뿐 아니라 모든 타입의 인스턴스가 들어올 수 있다. 그럼 인스턴스를 정수로 변환할 수 있다면 어떨까? 그럼 Key로 들어온 모든 인스턴스는 Key로 사용 가능하게 된다. HashMap의 Hash 의미를 여기서 알 수 있다. 키로 들어온 값을 해시함수를 통해 해시화 시키고, 이를 배열의 인덱스로 사용하는 것이다! 여기서 사용되는 해시함수는 들어온 인스턴스의 hashCode() 메서드이다.
그럼 HashMap 은 이렇게 생겼나요? (상상)
hashMap.put("Sim","010-1111-1111");
hashMap.put("Park","010-2222-2222");
hashMap.put("Hong","010-3333-3333");
String 타입의 Key와 Value를 저장하기 위해 String 타입의 HashMap을 생성하고 위 코드를 실행시킨다고 가정해보자. Sim, Park, Hong에 대한 해시 값이 아래와 같다.

지금까지의 설명을 토대로 HashMap의 구조를 상상해보면 다음과 같을것이다. 만약 새로운 Key, Value 쌍이 들어온다면 해시값과 Size 나머지 연산을 통해 구한 인덱스에 Value가 추가될것이다.

갑자기 % Size는 뭐야? 🤔
Hash Func, 즉 해시함수를 통해 해시 코드를 구하고 이를 Size 로 나머지 연산(실제로는 시프트 연산)을 한다. 나머지 연산을 하는 이유는 배열의 인덱스 중 하나로 매핑시키기 위함이다.
예를들어 Size가 10인 배열은 0~9까지의 인덱를 갖는다. 해시 값은 hashCode() 메서드 뿐 아니라 부가적인 연산도 함께 수행되어 구해지는데 아래와 같이 큰 숫자의 정수형이 리턴된다.

만약 3288449라는 값을 배열의 인덱스로 사용한다면 최소 3288449 크기의 배열을 생성해야한다. 메모리를 많이 차지할것이다. 때문에 이 값을 배열의 Size로 나눈 나머지를 구하고 이를 Index로 사용하는 것이다. 만약 HashMap 내부 배열 Size가 10이라면 3288449 % 10 = 9. 즉 9라는 인덱스를 갖게 된다.
실제로는 이렇지 않아요. 배열은 배열인데 Node 타입의 배열이랍니다. 🤭
실제로 데이터가 저장되는 곳은 제네릭 타입, Object 타입의 배열일까? 모두 아니다 Node 타입의 배열에 저장된다. HashMap에 선언된 Node 타입 변수 및 클래스이다.
transient Node<K,V>[] table; // hashMap 클래스 내에 선언되어있어요
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
...
}
멤버필드로 hash, key, value, nextNode 가 존재한다. 사실 Index와 Value로만 Key, Value 쌍을 관리하면 문제가 많다. 해시가 충돌될 경우 처리도 못하고, 리사이징과 해시 재배치 시 문제가 된다. (문제가 되는 이유는 아래에서 설명하도록 하겠다!)
Index랑 value 만 관리하면 될 줄 알았는데 아니네요? 🤔
hash, key, value, nextNode 필드를 갖는 Node 타입의 인스턴스로 관리되는 이유를 HashMap의 리사이징과 재배치, 충돌 우회 전략과 함께 이해해보자.
리사이징
리사이징
새로운 길이의 배열을 생성한 후 데이터를 이관시킴으로써 결과적으로 배열의 사이즈를 변경시키는 작업
배열의 사이즈는 초기화 시 정해진다. 기본 생성자를 통해 HashMap을 생성한 후 put 메서드를 실행하면 기본사이즈인 16 사이즈의 Node 배열이 생성되고 리사이징 임계 값으로 12(0.75*16)가 결정된다. 여기서 리사이징 임계값이란 배열을 리사이징하는 기준값을 뜻하며 현재 배열길이의 두 배로 리사이징한다. 12개를 초과할 경우 배열을 16의 2배인 32 사이즈로 리사이징 하는것이다.
ArrayList도 내부적으로 배열을 사용하고, 배열에 더 이상 들어갈 공간이 없을 경우 현재 사이즈의 절반 사이즈를 추가한 새로운 배열로 리사이징하는데 이와 같은 이치이다.

재배치
재배치
배열의 사이즈가 변경될 때 기존 데이터들의 Index를 재배치하는 작업
리사이징과 이어지는 내용이다. 리사이징을 할 경우 두 배 사이즈로 배열을 재생성하고 데이터를 이관시킨다고 했다. 이는 기존에 저장되어 있던 Node들의 Index가 재배치되어야 함을 의미한다. Index를 구하는 공식은 hashCode % Size 이므로 Size가 바뀐다면 Index도 바뀌어야하기 때문이다. 예를들어 사이즈가 10 일때 해시값 5755151를 통해 구한 Index는 1이지만, 사이즈가 20일 경우 Index는 11이 된다.
Node에서 hash 값이 관리되는 이유
이 재배치 작업 때 해시 값을 가져와 연산을 해야하는데 해시 값을 hash에 저장해놨기 때문에 나머지 연산만 하면 된다. 만약 해시 값이 없다면 해시 값 추출을 위해 존재하는 데이터 수 만큼의 해시함수 연산을 해야할것이다.
충돌 우회 전략 - Separate Chaining
지금 Index 기반으로 값을 넣고 있는데 과연 Index가 충돌할 확률은 대략적으로 어느정도일까? 사이즈에 대한 나머지를 Index로 사용하므로 배열 사이즈가 20이라면, Index가 중복될 확률은 최소 20분의 1이 된다.
어찌됐든 충돌이 일어날 수 있는 상황이다. HashMap은 이런 충돌에 대한 우회 전략으로 Separate Chaining 방식을 사용하며, 이 전략을 위해 nextNode를 사용한다.
Separate Chaning
동일한 해시값이 이미 존재할경우 LinkedList로 관리한다. 즉, Node에 있는 필드 중 nextNode를 활용하여 중복된 해시 값에 대한 Value를 관리하는 것이다.
그런데 만약 동일한 Key 값이 들어왔다면 어떨까? Sim이라는 Key값이 들어있는 HashMap에 Sim이라는 Key 값으로 다른 Value를 넣는 것은 전혀 문제되지 않는다. 이 경우 Index에 대한 Value가 덮어씌워져야한다. 즉, 동일한 Key가 들어왔는지를 확인하려면 Index 값만 비교하는 게 아니라 실제 Key 값도 비교해봐야한다.
Node에서 key, nextNode 값이 관리되는 이유
동일한 Key가 들어왔는지 확인하고, Linked List 형태로 우회하는 Separate Chaining 전략을 사용하기 위해 key와 nextNode가 관리된다.
Separate Chaining 동작원리
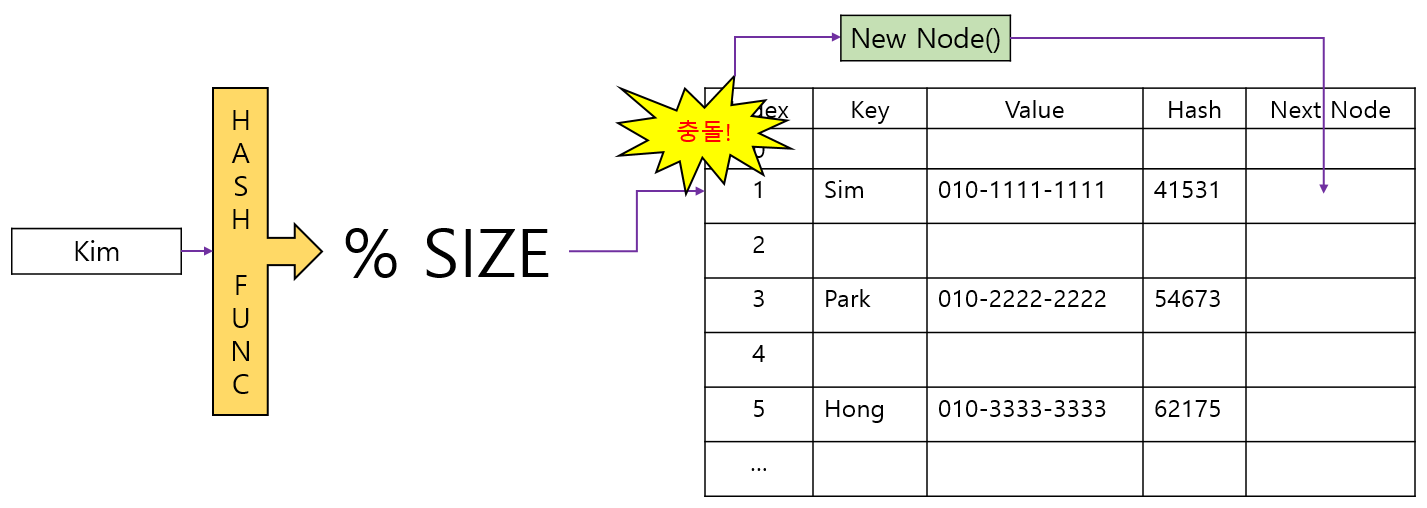
해시함수로 해시값을 구하고 나머지 연산으로 추출한 Index 가 충돌할 경우를 가정했다.
충돌이 일어나면 들어온 Kim에 대한 해시 값과 키 값을 충돌한 Node의 값과 비교한다. 다를 경우 Separate Chaining 전략에 따라 key, value, hash, nextNode를 갖는 Node 인스턴스를 생성하여 NextNode에 할당한다. 만약 비교한 Key와 Hash 값이 같았다면 중복된 Key가 들어온 것이므로 해당 Node의 Value 값을 새로 들어온 Value 값으로 수정한다.
그럼 NextNode에 추가된 Kim을 조회할 땐 어떻게 동작할까?🤔
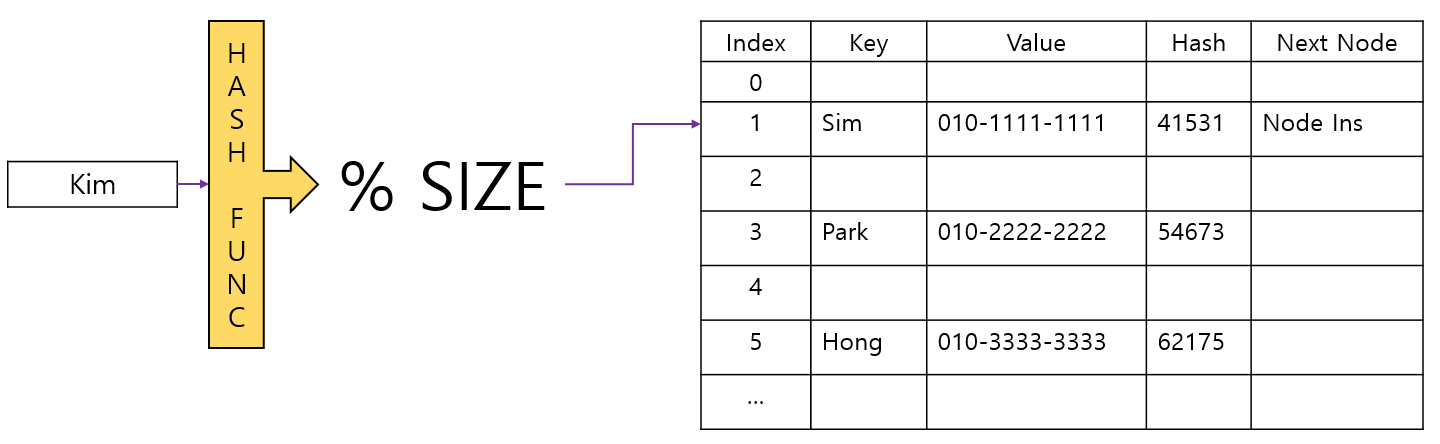
NextNode에 추가된 Kim에 대한 Value 값 조회를 시도하면 다음 과정을 수행하게 된다.
1. Hash Func % Size 연산을 통해 Index를 구한다.
2. Index 에 매핑된 노드가 존재하는지 확인한다.
3. 매핑된 노드가 존재하므로(충돌) 해당 노드의 Key, Hash 값과 요청으로 들어온 Key, Hash 값을 비교한다.
4. Kim과 Sim의 Key와 Hash 값이 다르므로 해당 노드의 nextNode가 있는지 존재한다.
5. nextNode가 존재하므로 해당 Node를 참조한다.
6. nextNode에 저장된 Key와 Hash 값이 들어온 Key와 Hash 값과 일치하므로 이 노드에 대한 Value 값을 리턴한다.
내부 구조를 이해한 후 다시 생각해본 HashMap의 장점
1. 조회가 빠르다.
조회 시 Key 값에 해시 및 나머지 연산만 하면 Index를 구할 수 있고, Index 기반으로 접근하니 당연히 조회 속도가 빠를수밖에 없다.
2. 저장, 삭제도 ArrayList보다 빠르다.
저장은 Key에 대한 Index를 구한 후 값을 넣기만 하면 되고, 삭제도 Key에 대한 Index를 구하고 삭제하면 된다. ArrayList의 경우 순서를 유지해야 하기 때문에 중간에 값을 삭제할 경우 빈자리를 채우기 위한 이동 연산이, 등록할 경우 빈자리를 만들기 위한 이동 연산이 수행되어야하는데 말이다.
내부 구조를 이해한 후 다시 생각해본 HashMap의 단점
1. 너무 많은 저장이 일어날 경우 오히려 속도가 느려진다.
저장이 많아지면 그만큼 리사이징과 재배치작업이 많아지기 때문이다. 만약 저장해야할 데이터가 많다면 HashMap의 사이즈를 너프하게 잡는것도 좋은 방법이다.
'공부 > 자료구조' 카테고리의 다른 글
| [자료구조] Iterator란? Iterator 사용 이유 (1) | 2021.07.22 |
|---|---|
| [자료구조] 리스트, 배열, 연결리스트의 정의 / 차이 (2) | 2021.07.15 |
| [자료구조] Generic 프로그래밍, Generic이란? (0) | 2021.07.08 |
| [자료구조] 추상클래스와 추상메서드 (0) | 2021.07.06 |
| [자료구조] 상속 / 메서드 오버라이딩 / 다형성 (0) | 2021.06.24 |