개요
MySQL의 인덱스를 공부하면 가장 처음 등장하는 내용이 바로 클러스터링 인덱스와 논 클러스터링 인덱스다. 필자는 인덱스를 공부하기 전 데이터가 적재되는 구조를 이해하고 싶었다. 이를 이해해야 인덱스를 설정했을 때 내부 구조, 성능과 같은 것들을 쉽게 유추할 수 있다고 생각했기 때문이다. 그리고 B-Tree 가 등장했다. 유투브 영상을보며 어떤 메커니즘으로 데이터들이 적재되고 구조화되는지 이해했다.
마지막으로 MySQL의 인덱스 구조에 대한 아래 이미지를 보고 필자가 공부했던 B-Tree를 적용시켜 이해하려했다. 그런데 이게 웬걸? MySQL의 인덱스구조와 B-Tree의 구조가 매칭되지 않았다. 이번 글에서는 MySQL의 인덱스 구조와 실제 B-Tree의 구조가 다른 이유를 이해하고, 클러스터링 인덱스와 논 클러스터링 인덱스에 대해 알아보도록 하겠다.

MySQL의 데이터 적재 구조는 B-Tree 가 맞긴 해?
다양한 DBMS들이 존재하고, 이들의 데이터 적재 구조도 모두 다르다. 이 중 MySQL은 B-Tree 방식의 데이터 구조를 채택했다고 하는데(실제 MySQL 공식문서에서도 말이다.) 위 이미지를 보면 '이게 B-Tree가 맞아?' 라는 생각이 든다.
결론부터 말하면 B-Tree가 맞긴하다. 다만 필자가 공부했던 기본 형태의 B-Tree 가 아니다. 변형된 형태의 B-Tree 이다. MySQL에서는 변형된 B-Tree인 B+Tree 를 사용한다!!
B+Tree 란
B-Tree의 변형된 형태의 트리이다. 필자가 공부하고 느낀 4가지의 주요 특징들을 정리해보았다.

1. 실제 데이터는 리프 노드에만 저장된다.
2. 리프 노드들은 포인터로 연결된 연결 리스트 형태이다.
3. 내부 노드는 오직 탐색을 위해 존재한다. 즉, 실제 데이터(== 레코드 데이터)가 없다.
4. 노드가 꽉 찰 경우 상위노드로 격상시킨다. 단, 복제된 ID를 격상시킨다.
위 특징을 이해하면 B+Tree 와 MySQL의 데이터 적재 구조를 이해할 수 있고, 더 나아가 인덱스와도 연계시킬 수 있다. 익숙한 B-Tree 를 보고 B+Tree와 뭐가 다른지 알아보자.
B-Tree 구조 살펴보기
4차 B-Tree에 1~10까지의 ID를 넣은 구조이다. 살펴보면, 루트 노드, 내부 노드, 리프 노드에 ID 값이 중복없이 들어있다. 만약 실제 DB였다면, ID 값과 함께 실제 데이터도 들어갔을것이다. 루트 노드, 내부 노드, 리프 노드에도 ID 와 함께 실제 데이터가 들어갔을것이란 말이다.
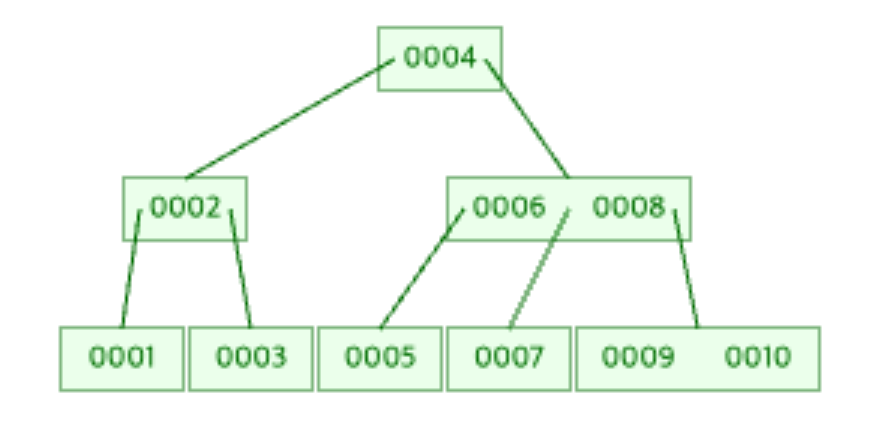
이제 MySQL 데이터 구조와 대조해보자. 먼저 눈에 띄는 건 ID이다. 루트 노드, 내부 노드, 리프 노드에 ID 값이 중복되어 들어있다. 하나 더있다. 루트 노드(or 내부 노드)의 데이터에는 실제 데이터가 아닌 리프노드의 주소 값이 들어있고, 리프 노드에 실제 데이터가 들어있다는 것이다.
B-Tree는ID 중복을 허용하지 않고, 루트 노드(or 내부노드)에는 실제 데이터가 들어있던것과 상반되는 내용이다. 이를 통해 B-Tree 구조가 실제 데이터 페이지의 트리 구조와 다를 수 있다는 것을 직감할 수 있다.
B+Tree 구조 살펴보기
마찬가지로 4차 B+Tree에 1~10까지의 ID를 넣은 구조이다. B-Tree와 마찬가지로 루트 노드, 내부 노드, 리프 노드에 ID 값이 들어있다. 단, 중복을 허용하지 않았던 B-Tree와는 다르게 중복된 ID가 많다. 여기서 하나 짚고 넘어갈게 있다. B-Tree 와 B+Tree의 노드들이 분리된 이유는 뭘까? 바로 '격상' 때문이다. B-Tree는 균형잡힌 트리로써 균형을 맞추기 위해 값을 격상시킨다.
그럼 B-Tree는 중복 ID가 없고, B+Tree는 있는 이유가 뭘까? 4번 특징인 '노드가 꽉 찰 경우 상위노드로 격상시킨다. 단, 복제된 ID를 격상시킨다.' 때문이다. 격상된 노드의 ID에 대한 데이터는 자신의 하위노드에 대한 포인터가 저장된다.
격상된 노드에 포인터를 저장하는 이유는 뭘까? B+Tree의 3번 특징인 '내부 노드는 오직 탐색을 위해 존재한다. 즉, 실제 데이터(== 레코드 데이터)가 없다.' 때문이다. 이정표 역할만 하는것이다. 그럼 실제 데이터는 어디에 저장될까? 1번 특징에 따라 실제 데이터는 리프 노드에만 저장된다.
마지막으로 리프 노드들은 모두 오른쪽 리프노드의 포인트를 갖는 것을 볼 수 있다. 이말은 뭘까? 특정 리프노드에서 다음으로 큰 ID를 가진 리프노드로 바로 이동할 수 있다는 뜻이다. 2번 특징인 '리프 노드들은 포인터로 연결된 연결 리스트 형태이다.'에 대한 내용이다. MySQL InnoDB 엔진에서는 이러한 특성을 살려 Next Key Lock을 걸 수 있고, 팬텀 리드 현상을 방지할 수 있다. 이에 대한 내용은 아래 글을 참고하면 좋다.
https://tlatmsrud.tistory.com/196
[MySQL] InnoDB 스토리지 엔진 잠금 / 레코드, 갭, 넥스트 키 락 / 팬텀리드를 방지할 수 있는 이유
개요 InnoDB 스토리지 엔진은 MySQL 엔진에서 제공하는 잠금과는 별개로 레코드 기반의 잠금 방식을 탑재하고 있다. 테이블 기반의 잠금 방식을 채택하고 있는 MyISAM 엔진보다 동시성 처리 측면에서
tlatmsrud.tistory.com
B+Tree 와 MySQL 데이터 구조 살펴보기
이제 다시 MySQL의 실제 데이터 구조를 보자. ID 값이 여러 노드에 중복되어 있고, 루트노드(or 내부노드)는 실제 데이터가 아닌 리프노드의 주소 값을 갖고 있다. 리프 노드는 실제 데이터를 갖고있으며, 이 이미지에 표시되지 않았지만, 101 번 노드는 102번 노드, 102번 노드는 103번 노드에 대한 포인터 정보도 갖고있다. 그렇다. 앞서 설명했던 B+Tree 구조와 MySQL의 실제 데이터 구조가 동일한 것을 느낄것이다.
이제 MySQL에서 데이터가 B+Tree 구조로 적재되는 것을 이해했다. 다음으로 클러스터링 인덱스와 논 클러스터링 인덱스를 이해해보자.
클러스터링이란 ?
클러스터링은 "여러개를 하나로 묶는다"라는 의미로 사용된다. 인덱스의 클러스터링도 이 의미를 벗어나지 않는다. 클러스터링 인덱스는 PK가 비슷한 레코들끼리 묶어 저장시키는 인덱싱 방식을 말한다. 방금 B+Tree 구조를 보면 알 수 있듯이 실제 데이터가 저장된 리프노드에는 비슷한 ID를 가진 데이터들이 모여있는 것을 알 수 있다.
클러스터링 인덱스란 뭔가요? 🤔
클러스터링 인덱스는 '키'에 대해서만 적용되는 인덱스이다. 즉, '키'가 비슷한 레코드끼리 묶어서 저장하는 것을 클러스터링 인덱스라고 한다. 클러스터링 인덱스는 테이블에 PK가 존재할 경우 자동 적용된다. 즉, 테이블을 설계할 때 PK를 설정하면 클러스터링 인덱스가 적용될것이고, 실제 레코드가 저장될 때 PK가 비슷한 레코드끼리 묶여서 저장된다. 클러스터링 인덱스를 설정하면 인덱스로 설정한 컬럼을 키로 하는 B+Tree 구조로 데이터를 정렬 저장하겠다는 뜻이다.
키 값이 변경되면 어떻게되나요? 🤔
PK가 비슷한 레코드들끼리 묶여 저장된다는 뜻은 PK가 비슷하지 않은 레코드들은 비교적 떨어져있다는 뜻이다. 키가 변경된다면, 그리고 그 키가 클러스터링 인덱스였다면 PK에 대한 레코드의 위치, 즉, 물리적인 저장 위치가 바뀌게된다.
InnoDB 엔진에서 클러스터링 인덱스는 반드시 있어야한다!
B+Tree의 구조 상 B+Tree의 키가 되는 값이 반드시 필요하다. 그런데 PK를 설정하지 않는다며 어떻게될까? 이 경우 InnoDB 스토리지 엔진은 다음 우선순위에 따라 클러스터링 인덱스를 자동으로 설정한다.
1. PK가 있으면 기본적으로 PK를 클러스터링 인덱스 키로 설정
2. NOT NULL 옵션의 유니크 인덱스 중에서 첫 번째 인덱스를 클러스터링 키로 설정
3. 자동으로 유니크한 값을 가지도록 증가되는 컬럼을 내부적으로 추가 후 클러스터링 키로 설정
유니크 인덱스
저장되는 값들이 중복되지 않도록 강제하는 인덱스로, UNIQUE 제약 조건을 설정하면 내부적으로 유니크 인덱스가 생성된다.
정리하면, '프라이머리 키 > 유니크 키 > 자동 생성 값' 순서로 클러스터링 인덱스를 설정한다.
자동 생성 값은 쓸모 없지 않아요? 🙁
자동 생성 값은 사용자 입장에선 쓸모없는게 맞다. 사용자가 볼 수 없고, 이 컬럼을 조건절로 조회 쿼리를 날릴수도 없다. B+Tree 구조를 전혀 활용하지 못하는 상태이다. 하지만 이 값이 없다면 B+Tree 구조에서 사용할 ID가 없는 상황이 된것과 같다. 자동 생성 값은 이런 상황때문에 필요하다. 오직 InnoDB의 B+Tree 저장구조를 유지하기 위해 만들어진 것이다. 사용자에게는 쓸모없고 불필요해도 데이터 구조를 유지하기 위해서 반드시 필요한 값인것이다.
논 클러스터링 인덱스가 뭔가요?
테이블의 기본 데이터 정렬 순서와 무관하게 별도의 B+Tree로 관리되는 인덱스이다. 여기서 말하는 기본 데이터 정렬 순서란 클러스터링 인덱스 기반으로 정렬된 데이터의 순서이다. 풀어 말하면 클러스터링 인덱스 기반으로 정렬된 데이터의 순서와 무관하게 별도로 관리되는 인덱스이다.
논 클러스터링 인덱스는 실제 데이터 페이지의 물리적 위치를 이동시키지 않는다. 너무 당연한 말이다. 실제 데이터 페이지는 클러스터링 인덱스에 의해 생성된 B+Tree에 있고, 이와 별개로 논 클러스터링 인덱스는 별도의 B+Tree를 생성/관리하기 때문이다. 아까 클러스터링 인덱스의 리프노드에는 실제 레코드 데이터가 들어있다고 했다. 논 클러스터링 인덱스의 데이터에는 실제 레코드 데이터가 아닌 데이터 레코드의 주소가 들어있다.
아래 이미지는 논 클러스터링 인덱스의 원리 설명을 위해 여러 블로그에서 많이 사용하는 이미지이다. 여기서 Index Page는 논 컬러스터링 인덱스 구조, Data Page는 클러스터링 인덱스 구조라고 생각한다면 몇가지 의문점이 들것이다.

첫째, Index Page의 ID가 1 ~ 15, Data Page의 ID도 1 ~ 15로 동일하다.
논 클러스터링 인덱스의 ID가 DataPage의 ID와 어떤 연관성이 있는걸까? 아니다! 이는 카디널리티가 1~15 인 age와 같은 컬럼을 논 클러스터링 인덱스로 설정했다고 생각하면 된다. 만약 name 컬럼을 인덱스로 설정했다면 IndexPage의 각 인덱스 ID는 andrew, bob, sean, tom과 같은 문자열 값이 들어갔을것이다.
둘째, Data Page 의 ID가 정렬되어 있지 않다.
Data Page는 클러스터링 인덱스의 리프노드라고 생각할것이다. 일반적인 방식으로 테이블을 설계한다 치면 PK로 ID를 넣었을 것이고, 그 말은 ID 가 정렬되어 저장되는게 맞다. PK를 설정하지 않았다고 하더라도 유니크 인덱스 ID 혹은 자동 생성 ID 기반으로 정렬되어 있을것이다.
이 이미지의 Data Page는 클러스터링 인덱스로 생성된 리프노드 아닌 것이다. INSERT 한 순서대로 데이터들이 적재된 데이터 페이지였다. 논 클러스터링 인덱스의 데이터 값에 데이터 페이지의 주소가 들어갔다는 것을 중점으로 설명하기 위한 예시로 이해하자.
위 두 내용을 인지하고 논 클러스터링 인덱스 구조 설명 이미지를 다시봐보자. 왜 저렇게 설명했는지를 이해할 수 있을것이다.
회고
이번 포스팅을 통해 MySQL 데이터 구조와 B+Tree , 인덱스 개념을 연관시켜 이해할 수 있었다. 다음에는 인덱스 기반으로 조회 쿼리를 날렸을 때 어떻게 데이터를 스캔하는지에 대해 알아보도록 하겠다.
'DB > MySQL' 카테고리의 다른 글
| [MySQL] InnoDB 스토리지 엔진 잠금 / 레코드, 갭, 넥스트 키 락 / 팬텀리드를 방지할 수 있는 이유 (0) | 2025.05.27 |
|---|---|
| [MySQL] MySQL 엔진 잠금 / 글로벌 락 / 테이블 락/ 네임드 락/ 메타데이터 락 (1) | 2025.05.26 |
| [MySQL] Slow Query Logging 설정하기 / 슬로우 쿼리 로깅 설정 (0) | 2025.05.26 |
| [MySQL] InnoDB Buffer Pool / 구조 / LRU / MRU (2) | 2025.02.11 |
| [MySQL] 비관적 잠금과 낙관적 잠금 (0) | 2025.01.14 |